
比賽回顧1|眾安保險線下Hackthon 保險續保預測
鄙人蔘加了一些資料探勘的競賽,有運氣好抱大腿獲獎的,也有被大佬碾壓的,但是希望能把這些比賽過程儘量記錄下。一方面是記錄一下事件本身,另一方面,是希望把自己的方案和想法記錄下,同時即使獲得了好的成績,也是有運氣成分,還是希望能夠找到有進步的空間,以後能做的更好。
比賽開始的時候,是在2018年8月23日抵達的上海,入住了酒店。第二天早上吃了酒店高貴的自助早餐之後就去簽到了。正式比賽開始是早上10點開始,一直到第二天的中午12點截止。(有沒有覺得很神奇,真的很神奇,線下的預測比賽哦,調參就給了26個小時,中間我們真的沒怎麼睡,熬出來的)
然後到了25號早上,隊友還在玄學調結果,我就只能先默默去把方案ppt給做了,因為我也就做了些特徵相關的處理。下午兩點答辯。最緊張刺激的是,我們當時線上的榜一直都是第一,在最後截止前一個多小時,被超了,最後就屈居第二。懷著沉重的心情,做著方案ppt。不過最後似乎我們的方案更得評委的心,(其實是我沒怎麼講技術實現,然而大家的方法都比較雷同),總分反超獲得第一。emmmm ,運氣不錯叭~
先給大家看些圖好啦~紀念下~

凌晨六點的外灘,你見過嗎?哈哈哈,那時候真的是身心俱疲,太累啦……

夜晚的外灘也是有不錯的風景呢(不過這個是我們結束了之後才去的,放鬆下身心啦)


最後不要臉的放一下我答辯的照片和我們最後的成果啦~
okok!現在直入正題,討論下我們的方案!
首先!資料量!真的很少,真的不多,當時我們是猜測,方便我們線下在訓練的時候,可以節省些時間。大概總共資料量在一萬多條。
主要針對的就是不同的保單,我們可以看到有使用者資訊,同時這些保單是在什麼樣的狀態下生成的,最後是否續報了(label)。
由於題目給的資料是全脫敏的,也就是說,特徵的名稱挺多沒有的,而且由於對於保險領域的知識的匱乏,很多隻能查資料和猜,甚至某些特徵對最後的標籤是否有影響都無法直接判斷。因此我們對於最後的資料結果,主要是以以下的策略去執行的:
放棄無意義的資料,例如那些90%以上都是重複的資料,或者是唯一識別符號性質的資料;
挖掘有意義的資料,對其資料進行重新的對映和標記;
從看起來有意義的資料背後挖掘相關的含義,讓模型和場景結合的更緊密(其實是為了讓答辯有東西可以講)。
那麼接下來就看下我們具體是怎麼做特徵工程的吧:

先來看下我們對於特徵的分析統計資訊。我們被給到的特徵型別主要有C型別,V型別和Z型別的,大概的理解就是C型別的就是編號型別的,V型別的就是數值型別的,Z型別則是一些字元資訊。
當然可以看到,我們根據原有的特徵,進行了重組和計算等等,挖掘了他們背後的意義。總共我們的特徵數量是24條。我們總共獲取的特徵數量是在原有數量的四分之一左右,所以可以看到其中還是有不少特徵是無用,(或者是我們沒有挖掘到深層資訊的特徵)。
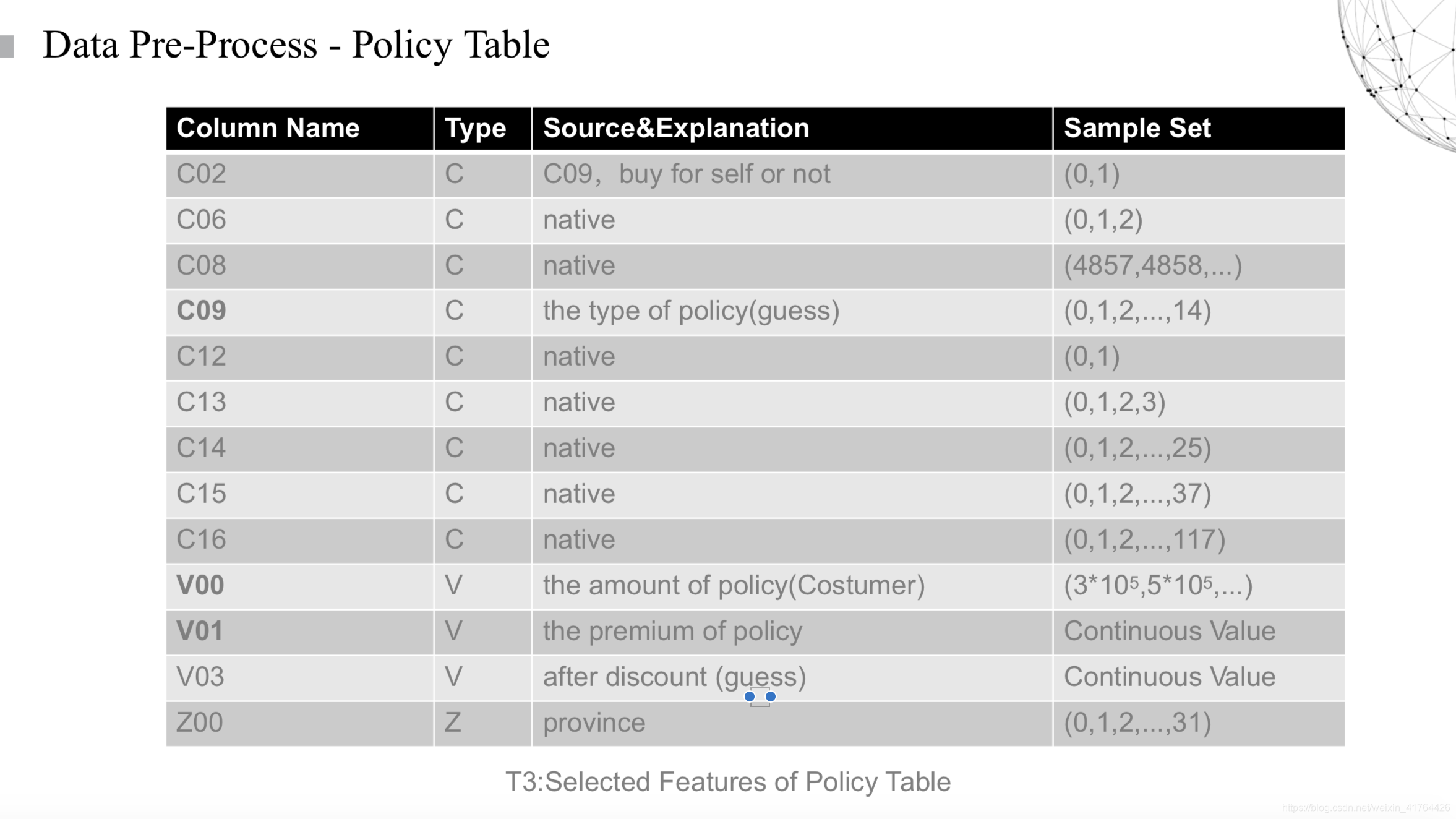
現在來看看我們針對保險表單挖掘的資訊,其中一些標為native的特徵就是直接從原表中複製過來的。然後就讓我來解釋一下其中我們經過處理的特徵,或是我們猜測其背後含義的資料吧。
C02是我們重新定義的一維資料,其中的內容就是為了判斷這份保單是否是使用者為自己購買的,這個資訊可以從表單的對應的人數中看的出來,因為每一張保單對應的角色一共有三個,投保人、被保人和受益人,一般只有都是同一個人,和有兩個人的情況(至少我們在比賽的過程中沒有出現有三個不同的人充當單個角色)。
C09是我們認為一維比較強的特徵,因為它可能代表的是保單的型別。猜測的原因也是因為在保險表單裡面對應的分類較少的一維特徵了。同時我們猜測到這一維特徵是保單的型別,由此推測,保單的型別可能會大概率影響後續的續保行為,有可能保單的保險金額比較高,或者是比較容易報銷,或者是收益比較好,等等,都是有可能的。
V00,V01,V03這三維資料是比較有意思的,當時發現原表單裡面是有三列特徵有加減關係的,意思就是列A+列B=列C,很直觀的就從銷售角度考慮到折扣的問題了,我們就將他們兩個合併成了V03這個單一特徵了。同時V00這個特徵是保留了保單的保額,也是會影響到最後的保單延續的情況。

在保單關於使用者資訊的一欄裡面,最有趣的一欄是我們當時現場逼問出題人這個含義到底是什麼意思。當時有很多無用資料,缺失率大概在80%以上,我們當時都放棄了,但是他們說給我們的資料都是有用的,於是他們就告訴我們在不同平臺上的資料記錄行為會有所區別。這就提示了我們,可能在不同平臺上產生的保單,會有不同的資訊記錄形式,這也就可以從另一個角度告訴我們,這些使用者是在不同平臺上進行保險的購買,同時我也查找了相關的文獻,在官方平臺上產生的購買行為,復購率比第三方平臺上的復購率高很多。於是我們就把這一維特徵表達成了是否在官方平臺上產生購買行為的bool型特徵。
T5中展示的是我們在表中丟掉的一些特徵,其中可能會又人很奇怪,為什麼會丟掉性別特徵,好,來看下一張圖表,我們可以很明確的證明我們的猜想。

這個是我們在公司官網上扒下來的資訊,對於不同年齡段的使用者可能會產生不同的保費,但是其中並沒有性別的選項,因此我們將性別資訊排除在外。同時我們也對其進行猜測,可能在產生重大疾病或重大賠付的人群中,男女比例差別並不大。
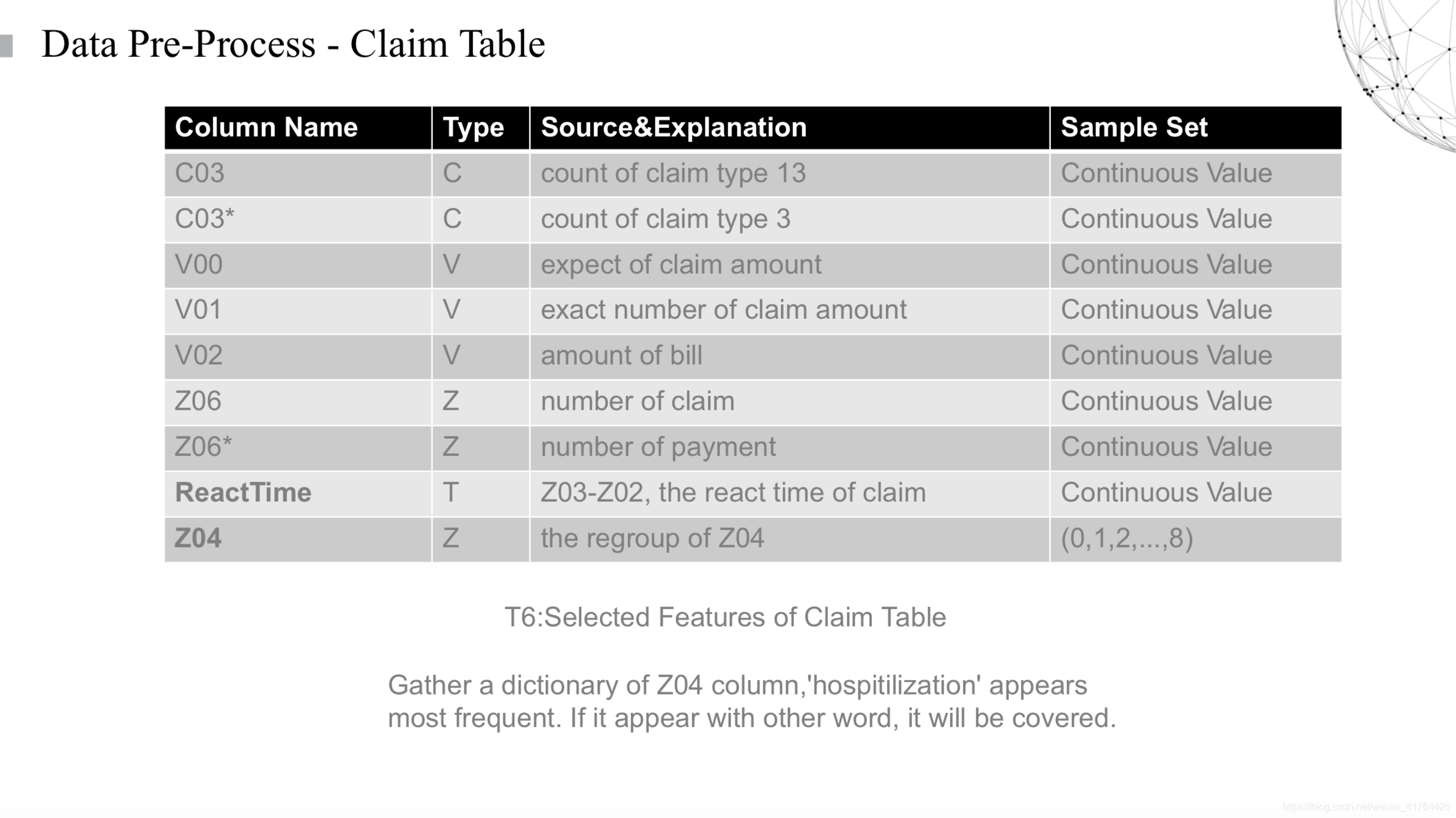
最後一張表是保險賠付的表單,其中主要是使用者產生了賠付行為,其中一些賠付款項,實際賠款,以及我們經過特殊處理的反應時間。在賠付行為和賠付的反應服務上,可能也會對使用者的最後續保行為產生影響。
我們特徵工程差不多就是這麼多。演算法的用的就是資料探勘競賽常用的xgboost演算法,美其名曰其理論非常的優美。
最後的結果是以F1-score來測評的,這個賽題的結果並沒有那麼好,而且大家的方案結果都很接近,我們最終是在0.67左右的結果。
那麼為了讓整個“表演”更加的完整,我們還討論了一下什麼特徵是對於我們最後的預測是最有幫助的——保費金額和保險狀態。
Meanwhile呢,我們也討論了下這個賽題的意義,無外乎就是吹捧了一下評委多棒啊,公司多牛逼,對,就是這樣了。
那麼最後肯定都是要討論一下 future work的啦~對不對!自然就是說如何再提升F1-score啦,比如引入更多的特徵,等等。
覆盤到這裡,其實覺得這次比賽真的做的非常一般,都沒有pandas分析一下資料的分佈和標籤的關聯性(隊友們我錯了,我一定加強我的資料分析能力),甚至最基礎的特徵交叉也沒嘗試過,只是做了簡單的特徵合併。不過整個比賽過程還是很享受的,每一步大家pace都很一致,所以整個比賽還是很愉快的。
不過最後的最後,我個人有一點小感想,包括做的別的比賽。在真實資料下的真實場景的資料探勘競賽,一定要深度理解場景背後的資料意義,不然這個資料就算用經驗處理出來最後的結果,也不會有太好的表達性。但是,如果一味的挖掘背後的真實意義,有時候反而會忽略一些小的細節點,這些是可以用傳統的暴力的特徵交叉的方法做到的。
所以,這個小的總結寫了不少,是本人在資料探勘競賽上的第一次比賽啦,也希望之後和隊友們能越走越遠,獲得更好的成績。歡迎大家留言交流。
以上。