【論文解析】Cascade R-CNN: Delving into High Quality Object Detection
論文連結
CVPR2018的文章。和BPN一樣,本文主要關注的是目標檢測中IoU的閾值選取問題,但是BPN主要針對的是SSD等single-stage的detector,感興趣的童鞋可以看我的另一篇博文BPN
目標檢測中,detector經常是用低IoU閾值來train的,如果提高IoU閾值,則會導致兩個問題:
(1)IoU提高以後,訓練中positive samples的數量會指數級減少,從而導致過擬合。
(2)預測和訓練用不同閾值,會導致不匹配。
問題發現
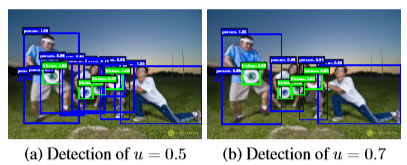
可以看到,圖a中低閾值的IoU訓出的detector會有很多close false positives,設想如果IoU閾值設為剛好0.5,那麼在0.5附近就會有很多的close false positives,我們就很難讓檢測器reject這些close false positives。
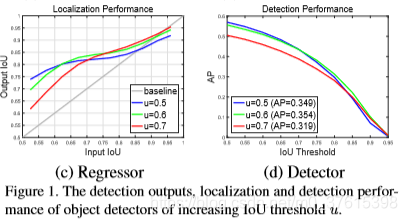
同時,在c中可以得出一個結論,一個檢測器只能在某一quality level上最優。quality level用detector的IoU設定閾值來確定。同時在d圖中可以看到,u=0.5在low IoU樣本表現得最好,但是在高IoU level時就比不過u=0.6了。所以總的來說,a detector optimized at a single IoU level is not necessarily optimal at other levels。
同時,直接用大閾值來訓練檢測器不一定會提高效果,可以看到d圖中u=0.7的時候,它會降低performance,AP只有0.319。這其中很大的一部分原因就是:和low quality的detector相比,hypotheses的分佈會改變,原因和上面提到的問題1類似。
目標檢測
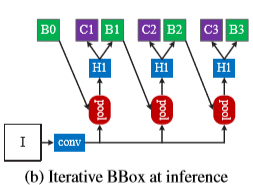
iterative BBox
論文中闡述了一下bounding box的迴歸方程,在這裡就貼一下:
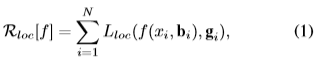 這個Lloc在R-CNN中用的時L2 loss,在fast-rcnn中就改成了smooth L1 loss了。
這個Lloc在R-CNN中用的時L2 loss,在fast-rcnn中就改成了smooth L1 loss了。
然後Lloc用來對距離向量進行操作:
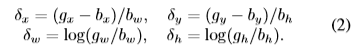
但是和classificatoin相比, 這個bounding box迴歸的梯度往往小於它,所以很多工作提出了單次迴歸對於精確的定位來說根本不夠,所以就提出了多次迴歸的方法,
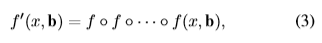
但是,它忽略的兩個問題:
- u=0.5的迴歸器對於更好的hypothese來說不是最優的,所以對於u≥0.85的bounding box來說,會降低它的效果。
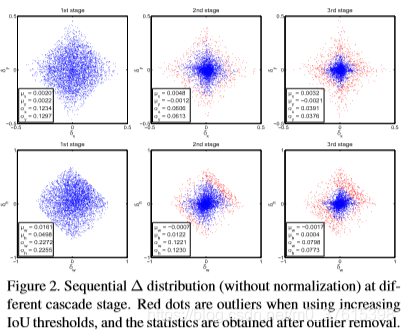
- 在圖2中,每次iteration之後,bounding box的分佈會顯著地改變,所以迴歸器如果對於初始分佈最優,那它對於其他分佈可能不是最優。
integral loss

只是單純地多次分類提高分類精度,每次分類針對的IoU閾值變高,但是這樣對定位毫無幫助,並且容易過擬合。
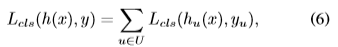
Cascade R-CNN
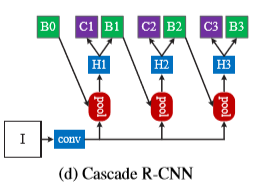
級聯R-CNN,總的來說就是多次迴歸,但是每次迴歸的迴歸器都是不一樣的,所用的閾值不斷提高,同時迴歸器訓練時也是用提高的閾值訓練的(和iterative BBox不同)
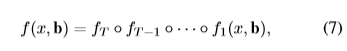
T時級聯的總數。
級聯R-CNN和iterative BBox的不同:
- 首先,iterative BBox時後處理過程,用了改善bounding box,但是級聯迴歸是一個重取樣過程,它會改變預測值的分佈。
- 其次,因為它在訓練和預測中都有使用,所以不會導致預測和訓練分佈的不同
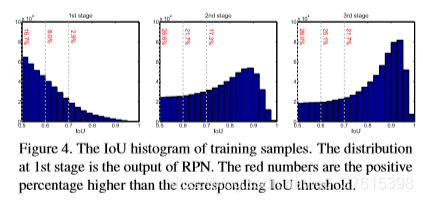
- 各個迴歸器都在其stage上是最優的,因為不同stage的分佈都重取樣了。這在圖4中也有體現
loss
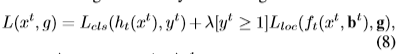
bt是上個stage迴歸後的bounding box。值得注意的是,有幾個stage就有幾個loss,t指的是stage的級數。
實驗
本文選擇的三個stage是{0.5,0.6,0.7}。本文實驗了三個baseline,faster rcnn(VGG),R-FCN和FPN。
Quality mismatch
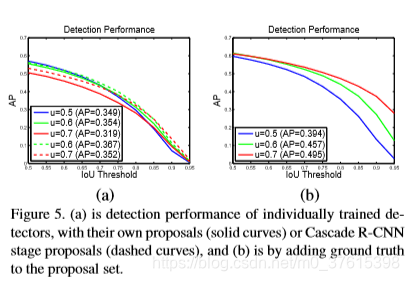
圖5(a)中,三條實線是用不同閾值訓練的單一的檢測器,可以看出u=0.5在低IoU閾值表現得好,在高IoU閾值比不過u=0.6. 然後我們為了理解這是怎麼發生的,在b中我們加入了一些ground truth bounding boxes。 可以看到,u=0.7有了很大的提高。所以說,高閾值的檢測器所需的樣本必須匹配quality。虛線表示用cascade裡面的proposals代替原樣本,可以發現檢測器得到了很好的提高。
和iterative BBox和integral loss的比較
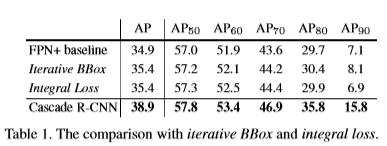
雖然都超過了baseline,但是cascade r-cnn的提升還是大了很多。
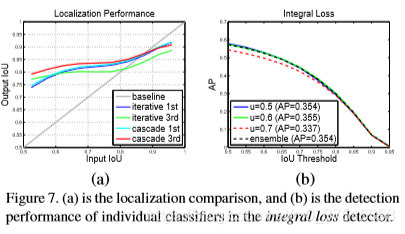
圖7(a)是和iterative BBox定位的比較,可以看出單一回歸器的使用會降低高IoU的hypotheses,這個影響在iterative BBox中會累計,但是cascade中later stages的表現在all levels都比BBox好。
圖7(b)則是integral loss的分類AP,u=0.6在all IoU表現得最好,u=0.7最差,融合也沒效果。
消融實驗
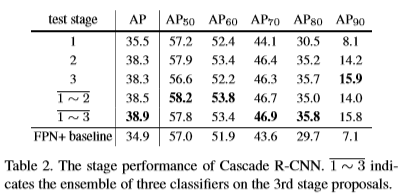
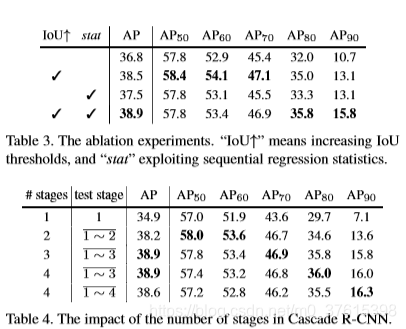
(這裡有個小小的疑問,Table 標號不應該放在表的上方嗎)
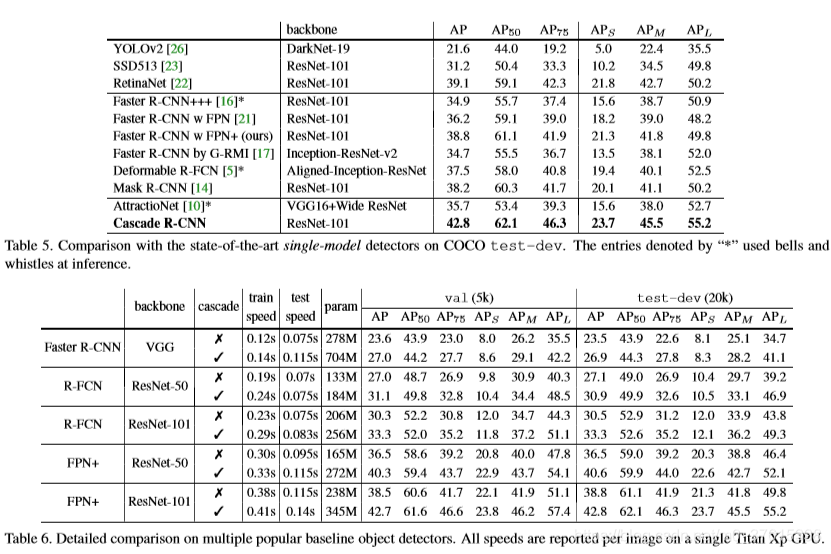
和state-of-the-art的比較