
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings論文筆記
回看前幾篇筆記發現我剪貼的公式顯示很亂,雖然編輯時調整過了,但是不知道為什麼顯示的和編輯時的不一樣,為方便大家的閱讀,我開始嘗試著採用markdown的形式寫筆記,前幾篇有時間的話再修改。
這篇論文閱讀完,我依然有很多不懂的地方,對其操作不是很清晰,因為我沒做過這方面的內容,且近期估計沒時間學習其專案,所以記錄理解的可能有誤,希望大家帶著思考閱讀。
PS:感覺這篇文章的作者是這個方向的大神呢,引用裡好多都是他自己的文章
原文下載連結
專案下載連結
摘要
- 跨語種嵌入對映(cross-lingual embedding mappings)的核心思想:分別訓練單個語種語料,再通過線性變換對映到shared space。
- 方法整體分為監督的、半監督的和非監督的,監督和半監督都要依賴種子字典(seed dictionary),本文主要研究非監督的方法
- 非監督方法主要有兩種:對抗訓練(adversarial training)和自學習(self-learning)
- 對抗訓練的缺點:依賴favorable conditions(如限制在相關的語種,類似維基百科的語料)
- 自學習的缺點:初始化不好時,易陷入差的(poor)區域性最優
- 本文即使根據自學習的缺點提出了初始化的方法。
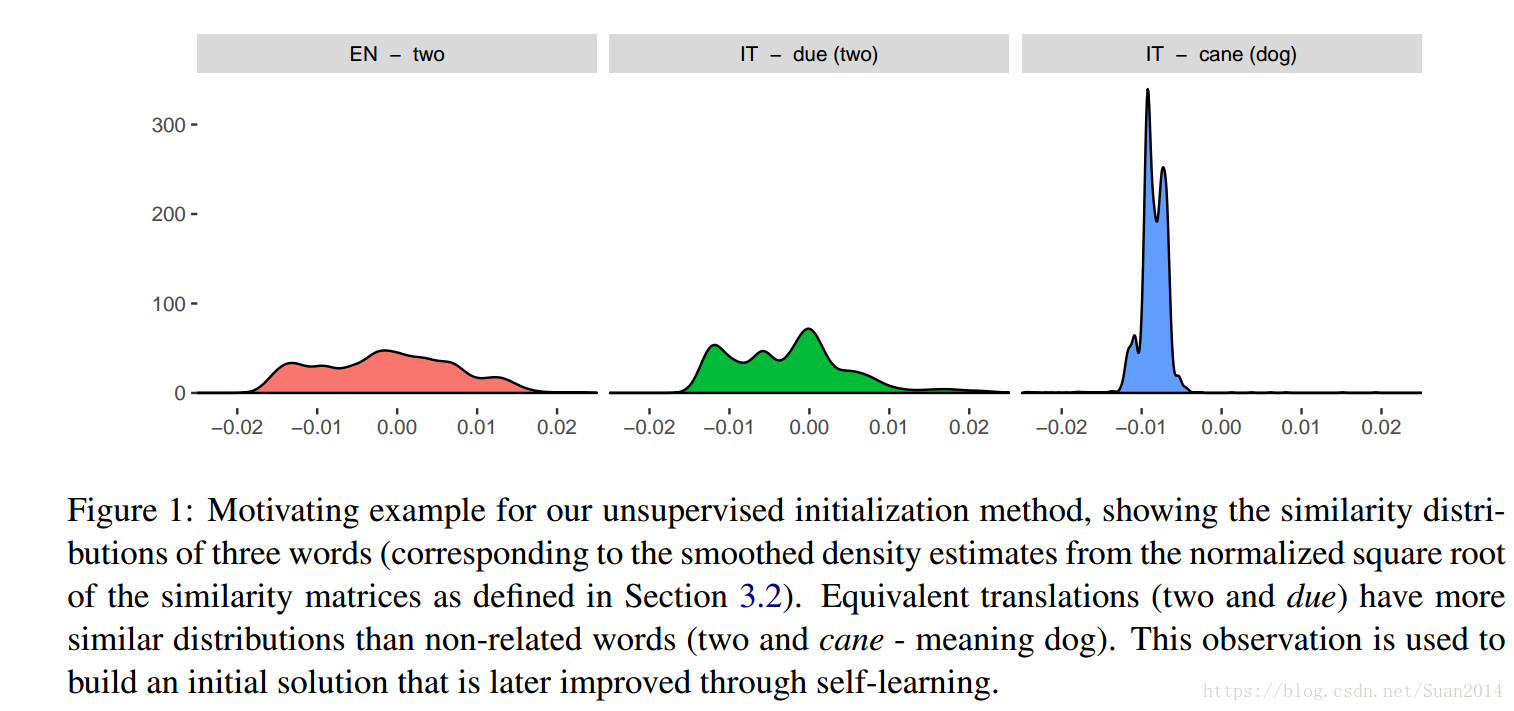
- 提出方法的依據是:觀察到不同語種中相同的詞有相似的相似度分佈,如圖1所示:
Figure 1中的第一幅圖是英文單詞two的相似度分佈,第二幅圖是義大利語due(等同於two)的相似度分佈,第三幅圖是義大利語cane(等同於dog)的相似度分佈。
本文演算法
設X和Z是兩種語言的embedding矩陣,所以他們的第
行
和
表示他們語種中的第
個詞,我們的目標就是學習變換矩陣
和
,所以對映embedding
和
在相同的跨語種空間,同時,要在兩個語種中構建一個字典即稀疏矩陣
,如果目標語言中的第j個單詞是源語言中第i個單詞的翻譯,則Dij = 1。
本文演算法主要分四步:1)normalize embedding的預處理;2)完全非監督的初始化方案;3)魯棒性強的self-learning步驟;4)最後微調通過對稱re-weighting進一步improve mapping.
1 embedding normalization
這邊具體不知道怎麼做的,只能把翻譯寫下來了(也不知道翻的對不對):長度標準化嵌入,然後平均每個維度的中心,然後長度再次標準化它們。(原文:length normalizes the embeddings, then mean centers each dimension, and then length normalizes them again.)
2 完全非監督初始化
這裡我就拷貝公式了,剩下的部分因為我也似懂非懂所以就簡單寫一下:mapping中的一個難點是X和Z並不對應,此處包含兩方面,詞不對應(反應到行),維度不對應(反應到列)。
本文的方法是首先通過
和
分別求其相似度矩陣,然後對每一行進行排序,然後在進行第一節的規範化操作;
3 Robust self-learning
這部分沒看懂啊,大家還是認真看原文吧
4 Symmetric re-weighting
同上一節(羞愧)
這篇文章沒仔細看,很多細節沒看懂,所以記得也比較草率,之所以還這樣記錄下來是為了記錄下其核心思想,等回顧時也許能用上。這篇寫的很差,大家見諒啊~~~~