
redis的相關原理(勿進)
Redis 資料型別
Redis支援五種資料型別:string(字串),hash(雜湊),list(列表),set(集合)及zset(sorted set:有序集合)。


使用redis有什麼缺點
分析:大家用redis這麼久,這個問題是必須要了解的,基本上使用redis都會碰到一些問題,常見的也就幾個。
回答:主要是四個問題
(一)快取和資料庫雙寫一致性問題
(二)快取雪崩問題
(三)快取擊穿問題
(四)快取的併發競爭問題
這四個問題,我個人是覺得在專案中,比較常遇見的,具體解決方案,後文給出。
什麼是快取擊穿
如果黑客每次故意查詢一個在快取內必然不存在的資料,導致每次請求都要去儲存層去查詢,這樣快取就失去了意義。如果在大流量下資料庫可能掛掉。這就是快取擊穿。
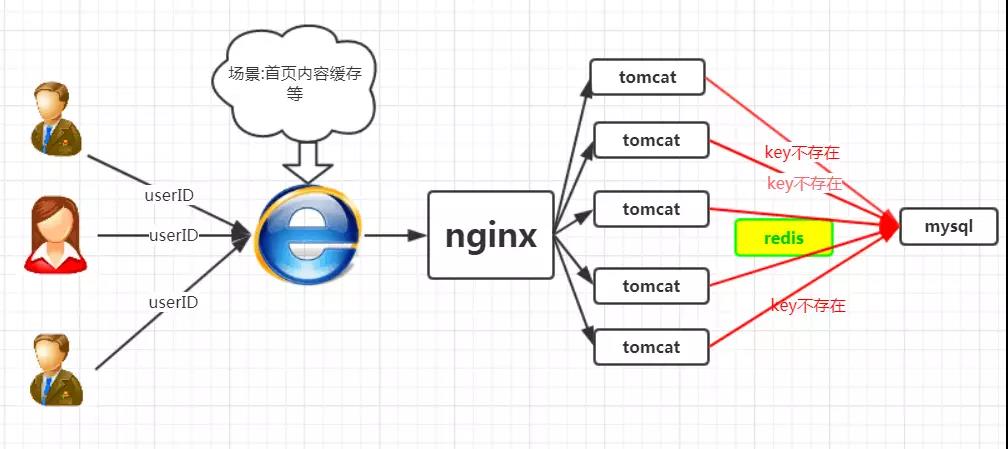
1、使用互斥鎖
該方法是比較普遍的做法,即,在根據key獲得的value值為空時,先鎖上,再從資料庫載入,載入完畢,釋放鎖。若其他執行緒發現獲取鎖失敗,則睡眠50ms後重試。
至於鎖的型別,單機環境用併發包的Lock型別就行,叢集環境則使用分散式鎖( redis的setnx)
叢集環境的redis的程式碼如下所示:
String get(String key) {
String value = redis.get(key);
if (value == null) {
if (redis.setnx(key_mutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(key_mutex, 3 * 60)
value = db.get(key);
redis.set(key, value);
redis.delete(key_mutex);
} else {
//其他執行緒休息50毫秒後重試
Thread.sleep(50);
get(key);
}
}
}
優點
-
思路簡單
-
保證一致性
缺點
-
程式碼複雜度增大
-
存在死鎖的風險
2、非同步構建快取
在這種方案下,構建快取採取非同步策略,會從執行緒池中取執行緒來非同步構建快取,從而不會讓所有的請求直接懟到資料庫上。該方案redis自己維護一個timeout,當timeout小於System.currentTimeMillis()時,則進行快取更新,否則直接返回value值。
叢集環境的redis程式碼如下所示:
String get(final String key) {
V v = redis.get(key);
String value = v.getValue();
long timeout = v.getTimeout();
if (v.timeout <= System.currentTimeMillis()) {
// 非同步更新後臺異常執行
threadPool.execute(new Runnable() {
public void run() {
String keyMutex = "mutex:" + key;
if (redis.setnx(keyMutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(keyMutex, 3 * 60);
String dbValue = db.get(key);
redis.set(key, dbValue);
redis.delete(keyMutex);
}
}
});
}
return value;
}
優點
-
性價最佳,使用者無需等待
缺點
-
無法保證快取一致性
3、布隆過濾器
1、原理
布隆過濾器的巨大用處就是,能夠迅速判斷一個元素是否在一個集合中。因此他有如下三個使用場景:
-
網頁爬蟲對URL的去重,避免爬取相同的URL地址
-
反垃圾郵件,從數十億個垃圾郵件列表中判斷某郵箱是否垃圾郵箱(同理,垃圾簡訊)
-
快取擊穿,將已存在的快取放到布隆過濾器中,當黑客訪問不存在的快取時迅速返回避免快取及DB掛掉。
OK,接下來我們來談談布隆過濾器的原理
其內部維護一個全為0的bit陣列,需要說明的是,布隆過濾器有一個誤判率的概念,誤判率越低,則陣列越長,所佔空間越大。誤判率越高則陣列越小,所佔的空間越小。
假設,根據誤判率,我們生成一個10位的bit陣列,以及2個hash函式((f_1,f_2)),如下圖所示(生成的陣列的位數和hash函式的數量,我們不用去關心是如何生成的,有數學論文進行過專業的證明)。

假設輸入集合為((N_1,N_2)),經過計算(f_1(N_1))得到的數值得為2,(f_2(N_1))得到的數值為5,則將陣列下標為2和下表為5的位置置為1,如下圖所示
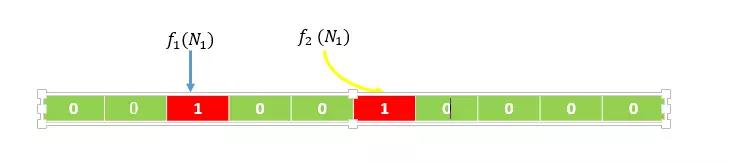
同理,經過計算(f_1(N_2))得到的數值得為3,(f_2(N_2))得到的數值為6,則將陣列下標為3和下表為6的位置置為1,如下圖所示

這個時候,我們有第三個數(N_3),我們判斷(N_3)在不在集合((N_1,N_2))中,就進行(f_1(N_3),f_2(N_3))的計算
-
若值恰巧都位於上圖的紅色位置中,我們則認為,(N_3)在集合((N_1,N_2))中
-
若值有一個不位於上圖的紅色位置中,我們則認為,(N_3)不在集合((N_1,N_2))中
以上就是布隆過濾器的計算原理,下面我們進行效能測試,
2、效能測試
程式碼如下:
(1)新建一個maven工程,引入guava包
<dependencies>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>
</dependencies>
(2)測試一個元素是否屬於一個百萬元素集合所需耗時
package bloomfilter;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.Charset;
public class Test {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter =BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
long startTime = System.nanoTime(); // 獲取開始時間
//判斷這一百萬個數中是否包含29999這個數
if (bloomFilter.mightContain(29999)) {
System.out.println("命中了");
}
long endTime = System.nanoTime(); // 獲取結束時間
System.out.println("程式執行時間: " + (endTime - startTime) + "納秒");
}
}
輸出如下所示
命中了
程式執行時間: 219386納秒
也就是說,判斷一個數是否屬於一個百萬級別的集合,只要0.219ms就可以完成,效能極佳。
(3)誤判率的一些概念
首先,我們先不對誤判率做顯示的設定,進行一個測試,程式碼如下所示
package bloomfilter;
import java.util.ArrayList;
import java.util.List;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class Test {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter =BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>(1000);
//故意取10000個不在過濾器裡的值,看看有多少個會被認為在過濾器裡
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("誤判的數量:" + list.size());
}
}
輸出結果如下
誤判對數量:330
如果上述程式碼所示,我們故意取10000個不在過濾器裡的值,卻還有330個被認為在過濾器裡,這說明了誤判率為0.03.即,在不做任何設定的情況下,預設的誤判率為0.03。
下面上原始碼來證明:
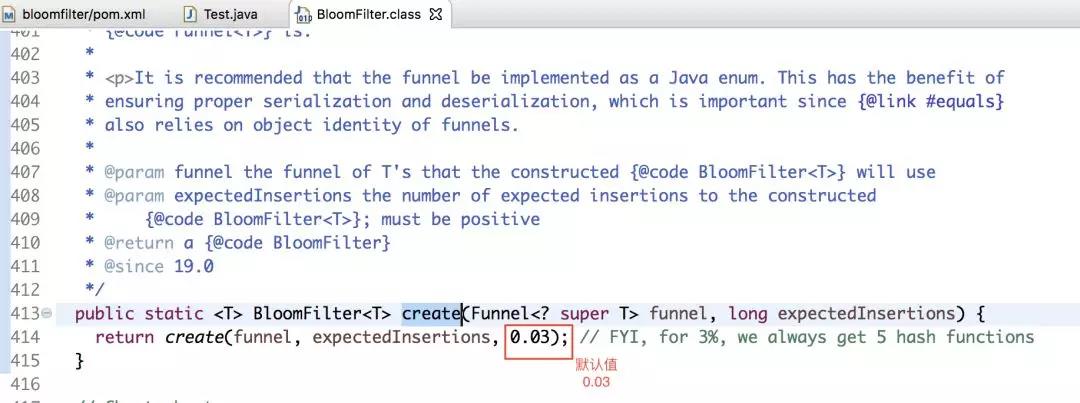
接下來我們來看一下,誤判率為0.03時,底層維護的bit陣列的長度如下圖所示
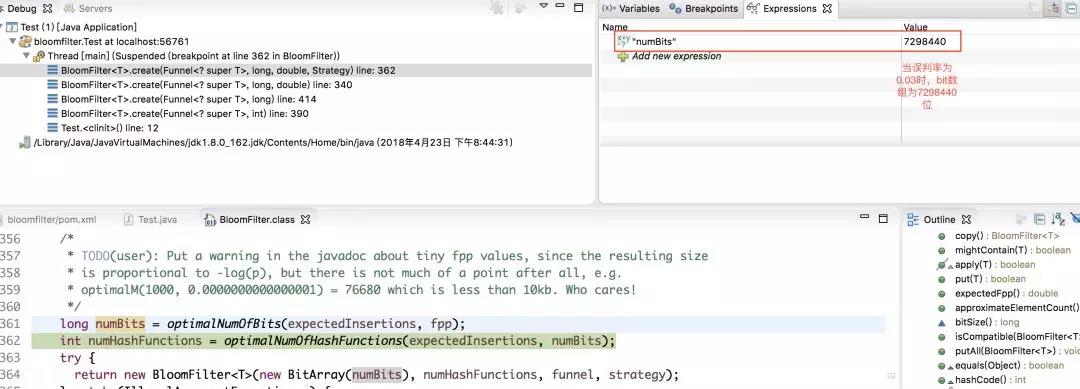
將bloomfilter的構造方法改為
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size,0.01);
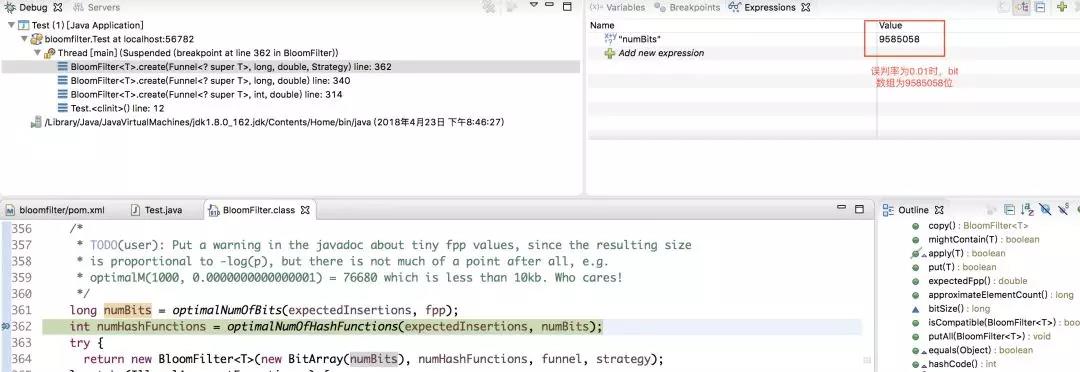
即,此時誤判率為0.01。在這種情況下,底層維護的bit陣列的長度如下圖所示
由此可見,誤判率越低,則底層維護的陣列越長,佔用空間越大。因此,誤判率實際取值,根據伺服器所能夠承受的負載來決定,不是拍腦袋瞎想的。
3、實際使用
redis虛擬碼如下所示
String get(String key) {
String value = redis.get(key);
if (value == null) {
if(!bloomfilter.mightContain(key)){
return null;
}else{
value = db.get(key);
redis.set(key, value);
}
}
return value;
}
優點
-
思路簡單
-
保證一致性
-
效能強
缺點
-
程式碼複雜度增大
-
需要另外維護一個集合來存放快取的Key
-
布隆過濾器不支援刪值操作
=====================================================================================
(1)首先進入redis,如果沒有開啟redis則需要先開啟:
[[email protected] bin]# redis-cli -p 6379
127.0.0.1:6379>
(2)檢視當前redis有沒有設定密碼:
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) ""
(3)為以上顯示說明沒有密碼,那麼現在來設定密碼:
127.0.0.1:6379> config set requirepass abcdefg
OK
127.0.0.1:6379>
(4)再次檢視當前redis就提示需要密碼:
127.0.0.1:6379> config get requirepass
(error) NOAUTH Authentication required.
127.0.0.1:6379>