
Kmeans、Kmeans++和KNN演算法比較
K-Means介紹
K-means演算法是聚類分析中使用最廣泛的演算法之一。它把n個物件根據他們的屬性分為k個聚類以便使得所獲得的聚類滿足:同一聚類中的物件相似度較高;而不同聚類中的物件相似度較小。其聚類過程可以用下圖表示:

如圖所示,資料樣本用圓點表示,每個簇的中心點用叉叉表示。(a)剛開始時是原始資料,雜亂無章,沒有label,看起來都一樣,都是綠色的。(b)假設資料集可以分為兩類,令K=2,隨機在座標上選兩個點,作為兩個類的中心點。(c-f)演示了聚類的兩種迭代。先劃分,把每個資料樣本劃分到最近的中心點那一簇;劃分完後,更新每個簇的中心,即把該簇的所有資料點的座標加起來去平均值。這樣不斷進行”劃分—更新—劃分—更新”,直到每個簇的中心不在移動為止。
該演算法過程比較簡單,但有些東西我們還是需要關注一下,此處,我想說一下"求點中心的演算法"
一般來說,求點群中心點的演算法你可以很簡的使用各個點的X/Y座標的平均值。也可以用另三個求中心點的的公式:
1)Minkowski Distance 公式 —— λ 可以隨意取值,可以是負數,也可以是正數,或是無窮大。

2)Euclidean Distance 公式 —— 也就是第一個公式 λ=2 的情況
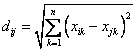
3)CityBlock Distance 公式 —— 也就是第一個公式 λ=1 的情況
![]()
這三個公式的求中心點有一些不一樣的地方,我們看下圖(對於第一個 λ 在 0-1之間)

上面這幾個圖的大意是他們是怎麼個逼近中心的,第一個圖以星形的方式,第二個圖以同心圓的方式,第三個圖以菱形的方式。
Kmeans演算法的缺陷
- 聚類中心的個數K 需要事先給定,但在實際中這個 K 值的選定是非常難以估計的,很多時候,事先並不知道給定的資料集應該分成多少個類別才最合適
- Kmeans需要人為地確定初始聚類中心,不同的初始聚類中心可能導致完全不同的聚類結果。(可以使用Kmeans++演算法來解決)
針對上述第2個缺陷,可以使用Kmeans++演算法來解決
K-Means ++ 演算法
k-means++演算法選擇初始seeds的基本思想就是:初始的聚類中心之間的相互距離要儘可能的遠。
- 從輸入的資料點集合中隨機選擇一個點作為第一個聚類中心
- 對於資料集中的每一個點x,計算它與最近聚類中心(指已選擇的聚類中心)的距離D(x)
- 選擇一個新的資料點作為新的聚類中心,選擇的原則是:D(x)較大的點,被選取作為聚類中心的概率較大
- 重複2和3直到k個聚類中心被選出來
- 利用這k個初始的聚類中心來執行標準的k-means演算法
從上面的演算法描述上可以看到,演算法的關鍵是第3步,如何將D(x)反映到點被選擇的概率上,一種演算法如下:
- 先從我們的資料庫隨機挑個隨機點當“種子點”
- 對於每個點,我們都計算其和最近的一個“種子點”的距離D(x)並儲存在一個數組裡,然後把這些距離加起來得到Sum(D(x))。
- 然後,再取一個隨機值,用權重的方式來取計算下一個“種子點”。這個演算法的實現是,先取一個能落在Sum(D(x))中的隨機值Random,然後用Random -= D(x),直到其<=0,此時的點就是下一個“種子點”。
- 重複2和3直到k個聚類中心被選出來
- 利用這k個初始的聚類中心來執行標準的k-means演算法
可以看到演算法的第三步選取新中心的方法,這樣就能保證距離D(x)較大的點,會被選出來作為聚類中心了。至於為什麼原因比較簡單,如下圖 所示:

假設A、B、C、D的D(x)如上圖所示,當演算法取值Sum(D(x))*random時,該值會以較大的概率落入D(x)較大的區間內,所以對應的點會以較大的概率被選中作為新的聚類中心。
KNN(K-Nearest Neighbor)介紹
演算法思路:如果一個樣本在特徵空間中的k個最相似(即特徵空間中最鄰近)的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別。該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
看下面這幅圖:
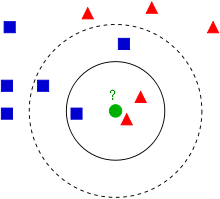
KNN的演算法過程是是這樣的:
從上圖中我們可以看到,圖中的資料集是良好的資料,即都打好了label,一類是藍色的正方形,一類是紅色的三角形,那個綠色的圓形是我們待分類的資料。
如果K=3,那麼離綠色點最近的有2個紅色三角形和1個藍色的正方形,這3個點投票,於是綠色的這個待分類點屬於紅色的三角形
如果K=5,那麼離綠色點最近的有2個紅色三角形和3個藍色的正方形,這5個點投票,於是綠色的這個待分類點屬於藍色的正方形
我們可以看到,KNN本質是基於一種資料統計的方法!其實很多機器學習演算法也是基於資料統計的。
KNN是一種memory-based learning,也叫instance-based learning,屬於lazy learning。即它沒有明顯的前期訓練過程,而是程式開始執行時,把資料集載入到記憶體後,不需要進行訓練,就可以開始分類了。
具體是每次來一個未知的樣本點,就在附近找K個最近的點進行投票。
再舉一個例子,Locally weighted regression (LWR)也是一種 memory-based 方法,如下圖所示的資料集。
用任何一條直線來模擬這個資料集都是不行的,因為這個資料集看起來不像是一條直線。但是每個區域性範圍內的資料點,可以認為在一條直線上。每次來了一個位置樣本x,我們在X軸上以該資料樣本為中心,左右各找幾個點,把這幾個樣本點進行線性迴歸,算出一條區域性的直線,然後把位置樣本x代入這條直線,就算出了對應的y,完成了一次線性迴歸。也就是每次來一個數據點,都要訓練一條區域性直線,也即訓練一次,就用一次。LWR和KNN很相似,都是為位置資料量身定製,在區域性進行訓練。
KNN和K-Means的區別

參考:
http://blog.csdn.net/chlele0105/article/details/12997391