
Hadoop的MapReduce例項講解—Python寫的WordCount Demo
MapReduce是hadoop這隻大象的核心,Hadoop 中,資料處理核心就是 MapReduce 程式設計模型。一個Map/Reduce 作業(job) 通常會把輸入的資料集切分為若干獨立的資料塊,由 map任務(task)以完全並行的方式處理它們。框架會對map的輸出先進行排序, 然後把結果輸入給reduce任務。通常作業的輸入和輸出都會被儲存在檔案系統中。因此,我們的程式設計中心主要是 mapper階段和reducer階段。 本文將通過 MapReduce中最為經典並簡單的WordCount例項來展示MapReduce工作原理。官網和各類部落格均有相關教程,內容大同小異,但在實際操作過程中還是會遇到一些未被提到的坑,最後發現能夠順利跑完這個MapReduce的簡單例項還是真的不容易的,特地將操作過程復現一遍,供大家參考。
1.前提(環境)
搭建好Hadoop的分散式叢集,並開啟Hadoop相關程序,已經啟動了必需的各項程序:namenode、datanode、resourcemanager、nodemanager、JobHistoryServer 等。並擁有Python2.7版本。Python3版本的話需要修改程式。
2.程式碼和資料集準備
1)編寫Map程式碼
這裡我們建立一個map.py指令碼,從標準輸入(stdin)讀取資料,預設以空格分隔單詞,然後按行輸出單詞機器詞頻到標準輸出(stdout),整個Map處理過程不會統計每個單詞出現的總次數,而是直接輸出“word 1”,以便作為Reduce的輸入進行統計。
import sys
for line in sys.stdin:
word_list = line.strip().split(' ')
for word in word_list:
print '\t'.join([word.strip(), str(1)])
2)編寫Reduce程式碼
這裡我們建立一個reduce.py指令碼,從標準輸入(stdin)讀取mapper.py的結果,然後統計每個單詞出現的總次數並輸出到標準輸出(stdout)。
import sys cur_word = None sum = 0 for line in sys.stdin: ss = line.strip().split('\t') if len(ss) < 2: continue word = ss[0].strip() count = ss[1].strip() if cur_word == None: cur_word = word if cur_word != word: print '\t'.join([cur_word, str(sum)]) cur_word = word sum = 0 sum += int(count) print '\t'.join([cur_word, str(sum)]) sum = 0
3)寫資料集。隨便寫一個src.txt的測試資料。
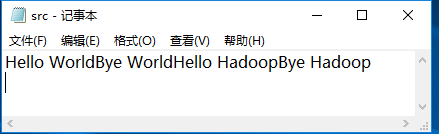
3.在Hadoop本地除錯
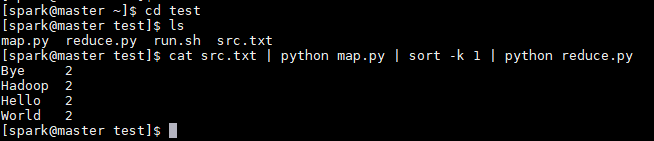
將三個檔案放在Hadoop伺服器的一個喜歡的位置,比如放在新建的test資料夾下,並通過以下命令在本地測試。
$ cat src.txt | python map.py | sort -k 1 | python reduce.py
執行結果如下,成功地顯示了每個詞出現的次數。
4.在Hadoop叢集上執行
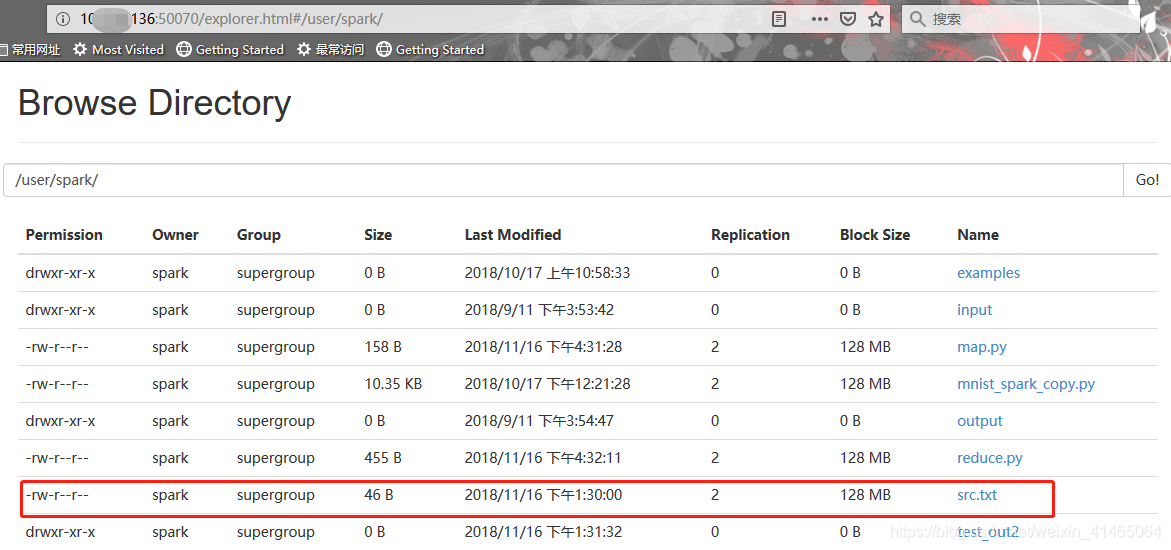
1)叢集上執行第一步就是把測試資料上傳到HDFS,我的上傳路徑是“/”,也就是當前使用者的根目錄。
$ hadoop fs -put src.txt /
檢視上傳結果如下
 2)接下來把我們的程式碼放到Hadoop上執行,由於Hadoop是java編寫的,執行時需要匯入程式的jar包才行,正常情況下,可以用eclipse自帶的打包工具打包寫好的java程式碼。然而,我們是用python編寫的,怎麼辦呢?這個時候就需要用到Hadoop自帶的工具streaming了,它可以自動幫我們將標準輸入輸出流串起來。且streaming.jar是Hadoop可執行的。首先cd到Hadoop-streaming-2.7.4.jar所在目錄。然後執行以下指令(注意其中的程式路徑需要根據自己情況修改):
2)接下來把我們的程式碼放到Hadoop上執行,由於Hadoop是java編寫的,執行時需要匯入程式的jar包才行,正常情況下,可以用eclipse自帶的打包工具打包寫好的java程式碼。然而,我們是用python編寫的,怎麼辦呢?這個時候就需要用到Hadoop自帶的工具streaming了,它可以自動幫我們將標準輸入輸出流串起來。且streaming.jar是Hadoop可執行的。首先cd到Hadoop-streaming-2.7.4.jar所在目錄。然後執行以下指令(注意其中的程式路徑需要根據自己情況修改):
$ hadoop jar hadoop-streaming-2.7.5.jar -input ./src.txt -output ./testout3 -mapper "python map.py" -reducer "python reduce.py" -file ~/test/map -file ~/test/reduce.py
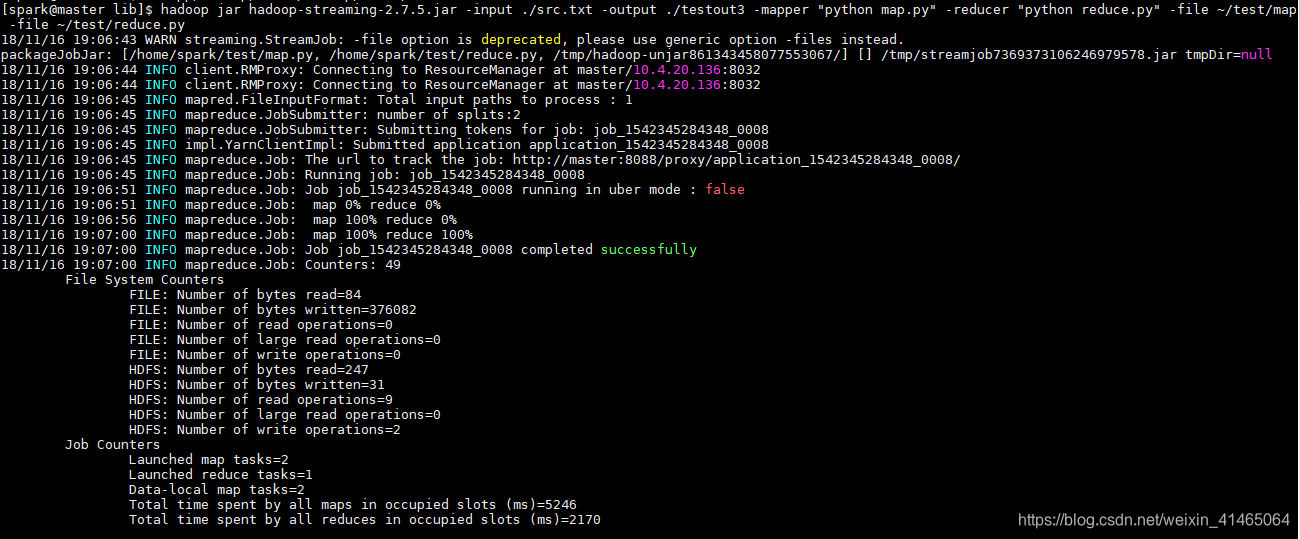
 執行成功後通過 hdfs 的cat指令檢視輸出結果。
執行成功後通過 hdfs 的cat指令檢視輸出結果。
