
Dynamic Zoom-in Network for Fast Object Detection in Large Images 閱讀筆記
摘要
我們引入了一個通用框架, 它降低了物體檢測的計算成本, 同時保留了不同大小的物體在高解析度影象中出現的情況的準確性。檢測過程中以coarse-to-fine的方式進行,首先對影象的down-sampled版本,然後在一系列較高解析度區域上,識別出哪些可能提高檢測精度。在強化學習的基礎上, 我們的方法包括一個模型 (R-net), 使用粗檢測結果來預測在更高解析度下分析一個區域的潛在精度增益, 另一個模型 (Q-net), 繼續選擇區域zoom-in.在Caltech Pedestrians資料集上的實驗表明,我們的方法將處理畫素的數量減少了50%以上,而不會降低檢測精度。我們的方法的優點在從YFCC100M資料集收集的高解析度測試集中變得更加突出,其中我們的方法保持高檢測效能,同時將處理畫素的數量減少約70%,並且檢測時間減少超過50%。
1.介紹
最近的卷積神經網路(CNN)檢測器應用於具有相對低解析度的影象,例如VOC2007 / 2012(約500400)[10,11]和MS COCO(約600400)[19]。在如此低的解析度下,卷積的計算成本很低。然而,日常裝置的解析度已經快速超過標準計算機視覺資料集。例如,4K智慧手機的相機解析度為2,1603,840畫素,單反相機可以達到6,0004,000畫素。將最先進的CNN檢測器直接應用於那些高解析度影象需要大量的處理時間。另外,卷積輸出對映對於當前GPU的儲存器來說太大。在主動機器人場景中出現了相關問題,其中機器人必須機械地平移,傾斜和縮放以獲取和處理所有相關畫素以支援控制機器人所需的視覺任務。在這種情況下,將視覺檢測器應用於儘可能少的平移,傾斜和縮放設定捕獲的影象非常重要。
先前的工作通過簡化網路架構[12,30,7,18]來解決其中一些問題,以加速檢測並減少GPU記憶體消耗。但是,這些模型是針對特定網路結構量身定製的,可能無法很好地概括為新架構。更普遍的方向是將檢測器視為一個黑匣子,明智地應用該檢測器來優化精度和效率。例如,可以將影象劃分為滿足儲存器約束的子影象並將CNN應用於每個子影象。然而,這種解決方案在計算上仍然是繁重的。通過在下采樣影象上執行現有檢測器,還可以加速檢測過程並降低儲存器需求。但是,小的物件可能變得太小而無法在下采樣影象中檢測到。物件提議方法是大多數CNN探測器的基礎,將昂貴的分析限制在可能包含感興趣物件的區域[9,27,33,32]。然而,在大影象中實現對小物體的召回率所需的物件建議的數量非常高,這導致巨大的計算成本。

我們的方法如圖1所示。我們通過首先對影象的down-sampled版本執行粗略檢測,然後依次選擇以更高解析度分析的有希望提高監測的區域來加速物件檢測。我們採用強化學習在檢測精度和計算成本方面對long-term reward進行建模,並動態選擇一系列區域以便以更高的解析度進行分析。我們的方法包括兩個網路::zoom-in accuracy gain regression network(R-net)自動學習粗略和精細檢測之間的相關性,並預測Zoom in區域的準確度增益; zoom-in Q function network 學習通過分析R-net的輸出和先前分析的區域的歷史來依次選擇最佳縮放定位和縮放比例。
實驗證明,在檢測精度可以忽略不計的情況下,我們的方法在Caltech行人檢測資料集[10]上,處理的畫素減少了50%以上,平均檢測時間減少了25%,從YFCC100M [16]收集的高解析度資料集中,處理的畫素減少了約70%,平均檢測時間減少了50%以上,這些資料集具有不同大小的行人。我們還將我們的方法與最近的SSD[24,20]進行了比較,以顯示我們在處理大型影象時的優勢。
2. 相關工作
CNN檢測:有效分析高解析度影象的一種方法是改進底層檢測器。 Girshick [16]通過分享proposal之間的卷積特徵來加速基於CNN的區域proposal[17]。 Ren等人提出了 Faster R-CNN [33],這是一種完全端到端的pipeline,共享proposal生成和物體檢測之間的特徵,提高了準確性和計算效率。最近,single-shot detectors[27,31,32]在實時效能方面受到了很多關注。這些方法刪除proposal生成階段並將檢測制定為迴歸問題。雖然這些檢測器在PASCAL VOC [12,13]和MS COCO [26]資料集上表現良好,這些資料集通常在解析度相對較低的影象中包含較大的物體,但它們不能在具有可變大小物體的大影象上進行概括。另外,由於大量的卷積操作,其處理成本隨著影象大小而急劇增加。
Sequential search:處理大影象尺寸的另一種策略是避免處理整個影象,而是順序地研究小區域。
然而,大多數現有工作集中在挖掘資訊區域以提高檢測準確性而不考慮計算成本。 Lu等人[28]通過適應性地關注可能包含物體的子區域來改善定位。Alexe等人[1]根據已經看到的提高檢測準確性的順序調查定位。然而,所提出的方法引入了大的開銷,導致檢測時間很長(每個影象的每個物體類別大約5s)。 張等人 [31]通過懲罰初始物件提議的不準確位置來提高檢測準確度,這為檢測時間帶來了超過15%的開銷。
Sequential search過程還可以利用來自源的上下文提示,例如場景分割。現有的方法已經為各種物體定位任務探索了這個想法[8,37,30]。這樣的線索也可以被納入我們的框架內(例如,作為預測zoom-inreward的輸入)。但是,我們專注於僅使用粗略檢測作為Sequential search的指導,併為將來的工作留下額外的上下文資訊。其他以前的工作[25]採用了coarse-to-fine的策略來加速檢測,但這項工作並沒有順序選擇有前途的區域。
Reinforcement learning (RL): RL a 是學習Sequential search策略的流行機制,因為它允許模型考慮一系列操作而不是單個操作的效果。Ba等人使用RL在[3]中訓練基於attention的模型以依次選擇最相關的區域用於物體識別,並且Jie等人[20]選擇區域以top-down的搜尋方式進行定位。但是,這些方法需要大量的選擇步驟,並可能導致執行時間過長。 Caicedo等人 [7]為物體定位設計了一個主動檢測模型,該模型利用Deep Q Networks(DQN)[29]學習一個long-term reward函式,以便順序轉換初始邊界框直到它收斂到一個物體。然而,正如文獻[7]報道的那樣,在典型的Pascal VOC image上,box transformation需要大約1.5s的檢測時間,這比最近的檢測器慢得多[33,27,32]。另外,[7]沒有明確考慮選擇成本。儘管RL隱含地迫使演算法採取最小步數,但我們需要明確懲罰成本,因為每一步都會產生高成本。例如,如果我們不懲罰成本,演算法將傾向於zoom-in整個影象。現有工作已經提出了將RL應用於RL in cost sensitive settings的方法[18,22]。我們遵循[18]的方法,將reward函式看作精度和成本的線性組合。
3. Dynamic zoom-in network
我們的工作採用了coarse-to-fine的策略,在低解析度下應用粗檢測器,並使用該檢測器的輸出來指導深度搜索高解析度物體。直覺是,雖然粗檢測器不如精細檢測器那樣準確,但它將識別需要進一步分析的影象區域,僅在有希望的區域中產生高解析度檢測的成本。我們利用兩個主要組成部分:1)學習粗略和精細探測器之間統計關係的機制,以便我們可以在得到粗略探測器輸出的情況下,預測哪些區域需要zoom-in;2)在給定粗檢測器輸出和已經由精細檢測器分析的區域的情況下,選擇以高解析度分析的區域序列的機制。
我們的流程如圖2所示。我們學習了一種策略,該策略模擬了以有限的成本最大化整體檢測精度的長期目標。
。
3.1. Problem formulation
我們的工作被制定為馬爾可夫決策過程(MDP)[4]。在每個步驟中,系統觀察當前的狀態,評估採取不同行動的潛在成本和回報,並選擇具有最大long-term cost-aware 回報的行動。
Action: 我們的演算法順序的分析每個區域zoom-in成高解析度的回報。在這種情況下,action對選擇要以高解析度分析的區域。每個action a, 由元組(x,y,w,h)表示,(x,y)表示的是位置,(w,h)指定區域的大小。在每一步,演算法對潛在的action評分(一個矩形列表區域)(採取這些action潛在的長期回報)(即把這些區域用於高解析度分析的回報)。
**State:**資訊表示的兩種編碼種類:
1)尚待分析的區域的預測準確度增益;
2)已經以高解析度分析的區域的歷史(同一區域不應多次放大)。
我們設計了一個zoom-in accuracy gain regression network(R-net)學習資訊精度增益圖(AG圖)作為可以成功學習zoom in Q函式的狀態表示。AG map的長寬尺寸跟原始輸入影象一樣大。AG map每個畫素的值是如果輸入影象中對應位置的畫素被放大區域包括,則可以提高檢測精度的估計值。結果,AG map提供用於選擇不同action對檢測準確度增益。在採取動作之後,與AG map中的所選區域相對應的值相應地減小,因此AG map可以動態地記錄動作歷史。
Cost-aware reward function:(具有成本意識的獎勵函式)狀態表示對在每個影象子區域上放大的預測精度增益進行編碼。為了在計算有限的情況下保持高精度,我們為action定義了Cost-aware reward function。給定一個state S,一個action a,Cost-aware reward function同時考慮成本增加和準確性改進為每個action(放大區域)打分。根據【15】,我們定義獎勵函式
R(s,a)為:
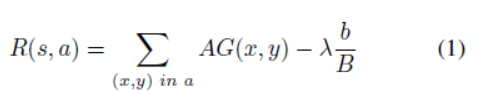
其中(x,y)表示點(x,y)在action a選擇的區域內,變數b表示action a 選擇的區域內包含的畫素的總數,B是整個影象畫素的總數。第一項(見方程3)衡量檢測精度的提升。第二項表示放大成本。精度和計算之間的權衡取決於引數。在訓練期間,Q-net使用此獎勵函式來計算採取行動的直接獎勵,並通過Q-learning來學習長期獎勵函式[28]。

圖2:給定一個down-sampled影象作為輸入,R-net生成一個initial accuracy gain(AG)對映,指示不同區域(初始狀態)的潛在zoom-in精度增益。迭代地在AG圖上應用Q-net來選擇區域。一旦選擇了一個區域,AG對映將被更新以反映action的歷史。對於Q-net,使用兩條並行pipelines,每條pipeline輸出一個動作reward對映,對應於選擇具有特定大小的zoom-in區域。對映的價值表示action以低成本提高準確性的可能性。來自所有對映的action reward被認為是在每次迭代中選擇最佳zoom-in區域。符號128×15×20:(7,10)表示128個大小為15×20的卷積核,高度/寬度為7/10的步長。輸出對映中的每個網格單元都被賦予一種獨特的顏色,並且在影象上繪製相同顏色的邊界框以表示相應的縮放區域大小和定位。
3.2. Zoom-in accuracy gain regression network
The zoom-in accuracy gain regression network (R-net)基於粗略檢測結果預測放大特定區域的準確度增益。R-net在成對的粗略和精細檢測上進行訓練,以便它可以觀察它們如何相互關聯以獲得合適的精度增益。為此,我們將兩個預先訓練好的Faster-RCNN [25]探測器應用於一組訓練影象,並獲得兩組影象檢測結果:1)在下采樣影象中用低解析度的檢測,在每張影象的原始版本用高解析度的檢測,其中d是監測的bounding box,p是為目標的概率,是從Faster R-CNN網路的fc7層獲得的高維特徵向量。我們使用上標h和l來表示原始(高解析度)和下采樣(低解析度)影象。我們使用上標i和h來表示原始(高解析度)和下采樣(低解析度)影象。對於模型來了解高解析度檢測是否改善了整體結果,在訓練時給定一組粗略檢測,我們引入了match layer匹配層,該匹配層將兩個檢測器產生的檢測結果相關聯。在這一層中,我們將粗略和精細檢測proposal配對,並在它們之間生成一組對應關係。下采樣影象中的proposals i 和原始影象中的proposal j 被定義為相關,如果他們有足夠大重疊,即IOU>0.5。
給定一組相關關係我們估計粗略檢測proposal的放大精度增益。檢測器只能處理一系列尺寸的物體,因此將檢測器應用於原始影象並不總能產生最佳精度。例如,如果檢測器在大多數較小的物體上進行訓練,則可以在較低解析度下以較高的準確度檢測較大的物體。因此,我們使用度量來衡量哪個檢測(粗略或精細)更接近於ground truth。其中。當高解析度的而檢測結果比低解析度的檢測結果更接近ground truth時。該函式表明此proposal值得放大。否則,檢測下采樣影象可能會產生更高的準確度,因此我們應該避免放大此proposal。我們使用Correlation Regression相關回歸(CR)層來估計proposal k的放大準確度增益:
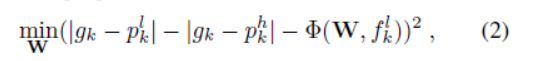
其中代表迴歸函式,W表示引數,該層的輸出是估計的準確度增益。CR層包含兩個完全連線的層,其中第一層具有1,024個單元,第二層僅具有一個輸出單元。根據每個proposal的學習精度增益,可以生成AG圖。我們假設proposal邊界框內的每個畫素對其準確度增益具有相同的貢獻。因此,AG圖生成為:
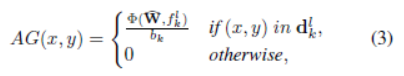
其中(x,y)in 表示點(x,y)在邊界框中。表示中畫素點的個數。表示CR層的引數。AG圖用作狀態表示,它自然包含粗檢測質量的資訊。放大並對區域執行檢測後,放大區域內的所有值都將設定為0,以防止將來放大同一區域。
3.3. Zoom in Q function learning network
R-net提供影象的哪個區域可能最具資訊量,用來指導下一步的檢測。由於R-net嵌入在順序過程中,我們使用強化學習來訓練第二個網路Q-net,以學習長期放大獎勵功能。在每個步驟中,系統通過考慮即時(等式1)和未來獎勵來採取行動。我們在Q學習框架中闡述我們的問題,該框架通過學習Q函式來近似於行為的長期獎勵函式。我們在Q學習框架中闡述我們的問題,該框架通過學習Q函式來近似於action的長期獎勵函式。基於Bellman方程,Q優化方程程服從一個重要的定義。在給定當前狀態的情況下,採取action的最佳獎勵等於其直接獎勵與此行動觸發的下一個狀態的折扣最優獎勵的組合(4)。
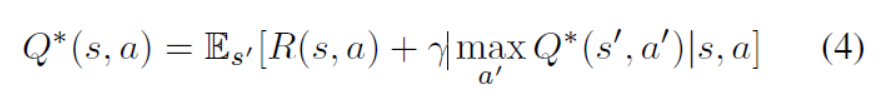
其中s是state,a 是 action。根據【21】我們通過最小化第i次迭代的損失函式來學習候選動作的Q函式。
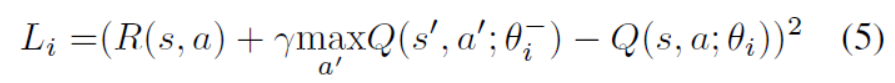
其表示Q網路的引數。表示在第i次迭代中,計算未來reward所需的引數。
等式5意味著如果為action - state 對提供直接獎勵R(s; a),則可以迭代地學習最佳long-term。由於R(s,a)是一個cost-aware reward,所以Q-net可以在action集中直接學出cost-aware reward函式。
在實踐中,,其中C是恆定的引數是未來獎勵折扣因子。我們根據經驗選擇C=10和。我們同樣使用了-greedy策略來訓練來平衡exploration and exploitation。的設定同【5】一樣。
Q-net的結構在圖2中所示。輸入是當前狀態表示(當前AG圖具有與輸入影象相同的寬度和高度),如果輸入影象中該位置的畫素包括在縮放區域中,則AG圖中的每個畫素衡量預測的精度增益。輸出是一組map,並且地圖的每個值衡量在該狀態下采取相應action(在具有指定大小的位置處選擇縮放區域)的長期獎勵。為了允許Q-net選擇具有不同尺寸的放大區域,我們使用多個管道,每個管道輸出對應於特定尺寸的放大區域的map。這些管道共享從狀態表示中提取的相同特徵。在訓練階段,來自所有map的action被連線起來以產生統一的action集,並通過最小化損失函式(5)來端對端地訓練,以便所有action價值相互競爭.
放大選定區域後,我們在該區域上獲得粗略和精細檢測。我們只是在每個放大區域中用精細的檢測替換粗略檢測。
**Window selection refinement:**Q-net的輸出可以直接用作放大視窗。但是,由於稀疏取樣候選縮放視窗,因此可以稍微調整視窗以增加預期的獎勵。Refine模組將Q-net輸出作為粗略選擇,並將視窗區域性移動到更好的位置,由精度增益圖得到:
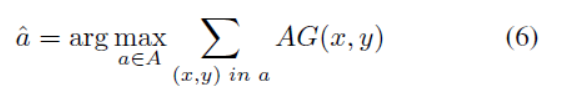
選擇微調的視窗,A=(,,w,h)對應於由引數控制的區域性細化區域.其中()代表Q—net輸出的視窗。我們在圖3中展示了細化的定性示例。

圖3:使用和不使用區域細化的定性比較。紅色框表示縮放區域,步驟編號表示選擇縮放視窗的順序。在細化之前,由於取樣網格,視窗可能會將人減少一半,從而導致檢測效能不佳。細化在本地調整視窗的位置,併產生更好的結果。
4. Experiments
我們在加州理工學院行人檢測資料集(CPD)[8]和從YFCC100M [16]收集的Web行人資料集(WP)上進行實驗。
**Caltech Pedestrian Detection (CPD):**這個資料集包含25萬個標籤框,其中包含35萬個邊框,註釋了大約23000個獨特的行人。根據不同的註釋型別有不同的設定,即總體而言,近尺度,中等尺度,無遮擋,部分遮擋和合理[8]。在測試集中,我們使用Reasonable設定(行人至少50畫素高,沒有或部分遮擋)。我們從訓練集中稀疏地取樣影象(每30幀)。訓練集中4,321個影象,測試集中有4,088個影象。在訓練和測試期間,我們將原始影象的大小調整為最短的600畫素。我們所有的模型元件都在此培訓集上進行了培訓。
**Web Pedestrian (WP) dataset:**CPD資料集中的影象解析度很低(640*480)。為了更好地展示我們的方法,我們從YFCC100M [16]資料集中收集了100個具有更高解析度的測試影象。通過搜尋關鍵詞“Pedestrian”,“Campus”和“Plaza”來收集影象。圖4中示出了一個例子。行人具有不同的尺寸並且在影象中密集地分佈。對於此資料集,我們註釋所有行人至少16畫素寬度和小於50%的遮擋。原始影象在最長側調整為2,000畫素,以適合我們的GPU記憶體。
4.1. Baseline methods
我們將與以下baseline演算法進行比較:
Fine-detection-all: 這個baseline 將精細檢測器應用於原始影象(高)解析度。該方法導致高檢測精度和高計算成本。所有其他方法都旨在以較少的計算來維持該檢測精度。
Coarse-detection-all: 這個baseline 將粗檢測器應用於下采樣影象而不進行縮放。
GS+Rnet: 給定R-net生成的初始狀態表示,我們使用貪婪搜尋策略(GS)每次基於當前狀態密集搜尋最佳視窗,而不考慮長期獎勵。
ER+Qnet: 檢測器輸出的熵(物件與無物件)是另一種測量粗略檢測質量的方法。[2]使用熵來衡量分類任務的區域質量。較高的熵意味著較低的粗略檢測質量。因此,如果我們忽略精細和粗略檢測之間的相關性,則區域的精度增益也可以計算為
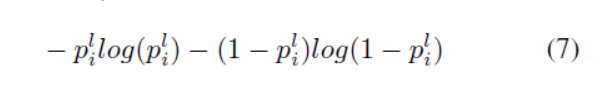
其中是粗略監測的得分,為了公平比較,我們修復了管道的所有引數,除了用其熵替換proposal的R-net輸出。
SSD and YOLOv2: 我們還將我們的方法與SSD [20]和YOLOv2 [24]進行了比較,以表明在我們的場景中將最先進的高效探測器應用於整個影象是不夠的。
4.2. Variants of our framework
我們使用Qnet-CNN來表示使用完全卷積網路開發的Q-net(見圖2)。為了分析不同元件對效能增益的貢獻,我們評估了我們框架的三種變體: ,Qnet-FC和Rnet 。
net : 這種方法使用Q-net進行細化以在區域性調整由Q-net選擇的zoom-in window。
**Qnet-FC:**QNET-FC。 [7]之後,我們為Q-net開發了兩個完全連線(FC)層的變體。對於Qnet-FC,狀態表示被調整為長度為1,200的向量作為輸入。第一層有128個單元,第二層有34個單元(9 + 25)。每個輸出單位表示影象上的取樣視窗。我們在CPD資料集上統一取樣25個尺寸為320×240的視窗和9個尺寸為214×160的視窗。由於無法更改Qnet-FC的輸出數量,因此將Qnet-FC應用於WP資料集時,視窗大小會成比例地增加。
Rne: 這是使用reward函式學習的R-net,其沒有明確編碼成本(方程式1中的λ= 0)。
4.3. Evaluation metric
與Finedetection-all策略進行比較時,我們使用三個指標:AP百分比(Aperc),處理的畫素數百分比(Pperc)和平均檢測時間百分(Tperc)。 與精細檢測全部策略策略相比,Aperc量化了我們獲得的mAP百分比。Pperc和Tperc將計算成本表示為精細檢測全部基線策略的百分比。
4.4. Implementation details
我們將原始影象下采樣兩倍,以形成我們所有實驗的下采樣影象,並僅處理原始解析度的放大區域。對於Q-net,我們在空間上對具有兩種不同視窗(320 240 and 214 * 160)大小的放大候選區域進行取樣。對於HW的視窗大小,我們使用水平步幅 = W/2,垂直步幅 = H/2畫素統一取樣視窗;當AG圖的所有值的總和小於0:01時,Q-net停止採取行動。
我們使用[8]中的訓練集在精細和粗略解析度上訓練兩個更Faster R-CNN探測器,然後將它們用作黑盒的粗略和精細探測器。YOLOv2和SSD使用與作者釋出的官方程式碼中的預設引數設定相同的訓練集進行訓練。所有實驗均使用K-80 GPU進行。
4.5. Qualitative results
定性比較顯示了細化對所選放大區域的影響,如圖3所示。我們觀察到,細化顯著減少了行人僅在所選視窗中部分出現的情況。由於Q-net的稀疏視窗取樣,任何視窗候選可能不會覆蓋最佳區域,尤其是當視窗大小與影象大小相比相對較小時。
我們展示了我們的方法(Q-net * -CNN + Rnet)和圖4中的貪婪策略(GS + Rnet)之間的比較。GS傾向於在影象的相同部分上選擇重複縮放。雖然Q-net可能在短期內選擇次優視窗,但從長遠來看,它會帶來更好的整體效能。如圖4的第一個例子所示,這有助於Q-net以較少的縮放終止。
圖5顯示了R-net和ER的定性比較。第一行中的示例是不需要放大的檢測,因為粗略檢測足夠好。R-net對這些區域的準確度增益要低得多。另一方面,R-net在第二行輸出更高的增益,其中包括需要以更高解析度進行分析的區域。第三行包含在更高解析度下得到更差結果的示例。正如我們之前提到的,熵不能確定放大是否有幫助,而R-net會為