
轉碼解密挖礦 顯示卡計算能力大對比
GPU通用計算髮展勢頭迅猛
泡泡網顯示卡頻道8月27日 現在的顯示卡市場,同質化已經嚴重到了什麼地步呢?不僅僅是板卡廠商之間的顯示卡效能基本沒區別,而且同價位的N卡和A卡在不同遊戲中的表現也是難分勝負,讓遊戲玩家們難以抉擇。

於是NVIDIA和AMD的競爭開始逐漸淡化遊戲,而強調功能和應用,三屏、3D、PhysX、視訊等開始大行其道。不過這些功能都難以量化,隨著CUDA和Stream的飛速發展催生了OpenCL和DirectCompute通用計算標準,使得NVIDIA和AMD在另一條道路上展開了新的競賽——平行計算。
近年來GPU已經在科學研究和超級計算領域取得突破性進展,隨著數百萬支援CUDA的GPU已經遍佈全球計算機,軟體開發人員、科學人士和研究人員正在利用CUDA探測到更多更廣的領域中,包括影象和視訊編輯、計算生物學和計算化學、流體力學模擬、CT影象重組、地震分析、光線追蹤以及其它更多。近年來超級計算機的突飛猛進很大程度上也是得益於強大的GPU加盟。

對顯示卡感興趣的朋友都知道,通用計算之所以如此熱門,根本原因在於顯示卡核心GPU的多流處理器(相當於數百核心)架構:GPU強大的並行浮點運算能力是僅僅擁有個位數核心的中央處理器CPU無法望其項背的。而通用計算技術可以發揮GPU的長處,讓其電腦運算速度飆升,一些應用程式的速度可以提高數倍甚至數十倍,讓原來因為運算量巨大而不可完成的任務變得可行。
而在家用、辦公電腦上,藉助GPU加速的軟體也越來越多,這些軟體有的可以用來轉碼,有的可以用來增強影象、視訊的畫質,有的可以將2D電影轉換成3D,有的還能智慧歸類和編輯照片……
AMD和NVIDIA通用計算解析
跟以往的GPGPU概念不同的是,CUDA是一個完整的解決方案,包含了API、C編譯器等,能夠利用顯示卡核心的片內L1 Cache共享資料,使資料不必經過記憶體-視訊記憶體的反覆傳輸,shader之間甚至可以互相通訊,對資料的儲存也不再約束於以往GPGPU的紋理方式,存取更加靈活,可以充分利用stream out(流輸出)特性,最典型的例子就是PhysX物理加速特效。PhysX最早是Aegia公司推出的硬體級物理加速技術,NVIDIA將其收購之後便通過CUDA環境將PhysX軟體化,由顯示卡中的shader單元承擔物理加速特效的運算。

對於Stream技術,AMD宣稱可讓顯示卡內數百個平行串流核心,為各種一般用途的應用帶來加速的效果,打造各種優異的平臺,並可大幅提升每瓦效能,而實現這一點的前提就依賴於AMD獨特的流處理器單元設計。
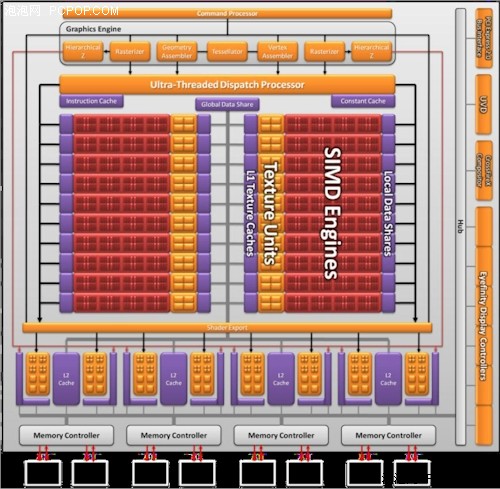
GF100的512個CUDA核心都符合IEEE 754-2008浮點演算法(Cypress也是如此)和完整的32位整數演算法,而後者在過去只是模擬的,事實上僅能計算24-bit整數乘法;同時全面引入的還有積和熔加運算(Fused Multiply-Add/FMA)。此外雙精度浮點(FP64)效能大大提升,峰值執行率可以達到單精度浮點(FP32)的1/2,而過去只有1/8,AMD從R600開始到現在的Cypress核心都是1/5,沒有做任何變化。
蛋白質摺疊分散式計算:N卡優勢巨大
其實業界第一款GPU通用計算軟體就是使用者科學計算,它就是由斯坦福大學主導的Folding @ Home分散式計算,最早支援ATI顯示卡,而NVIDIA後來者居上,目前N卡所貢獻的運算能力已經超越了所有CPU之和,A卡也不弱!

[email protected]是一個研究蛋白質摺疊、誤折、聚合及由此引起的相關疾病的分散式計算工程。最開始[email protected]僅支援CPU,後來加入了對PS3遊戲機的支援,但同樣是使用內建的CELL處理器做運算。[email protected]因ATI的加入為GPU計算翻開了新的一頁,如今[email protected]第二代GPU客戶端已經能夠支援ATI和NVIDIA的全系列DX10 11 GPU

針對Fermi核心的平衡運算優勢,《[email protected]》最新版本GPU3,專為新一代Fermi系列顯示卡而設,進一步善用Fermi核心架構之優勢。
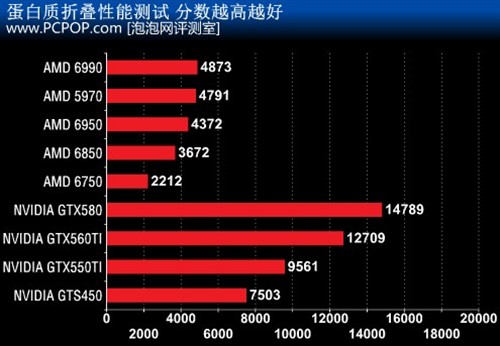
據官方介紹,新版的蛋白質摺疊運算速度及穩定性已經大幅提高,而且加入更加科學計算專案,希望能籍Fermi核心的架構優勢,加快《[email protected]》內的各項複雜運算。Shader的頻率對影響運算效能非常大,所以NVIDIA可以領先AMD很多。
GPU暴力破解密碼:A卡遙遙領先
遺失密碼是一件令人相當煩惱的事,尤其因忘記工作文件密碼所做造成的金錢損失更是十分“杯具”,如何快捷高效地找回密碼是件難事。現行GPU的發展越來越強勢,通用執行能力已經遠超於CPU,而CPU的執行能力卻是有限的,所以能夠發揮出GPU強大的通用運算能力定必會大大縮短破解密碼的時間。
GPU就是顯示卡的“心臟”,也就相當於CPU在電腦中的作用,它決定了該顯示卡的檔次和大部分效能外,還有著大規模的平行計算能力,可以讓開發人員領先出引人入用的消費級和專業級的計算應用程式。無論是NVIDIA的CUDA或者是AMD的Stream運算,都是眾多軟體廠商所追捧的。

我們找來了Elcomsoft出品的ADVanced Office Password Recovery,是一款同時支援CPU與GPU的Office密碼恢復軟體。最多可支援32個CPU或核心和8個GPU同樣執行,也可以指定全部或者是部分CPU/GPU核心進行恢復密碼的工作。
測試中我們關閉所有CPU核心,完全由GPU獨立工作來破解一個由6位數字加密的Word檔案。
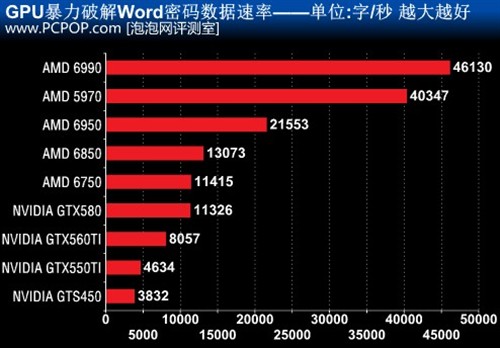
密碼破解對於流處理器數量非常敏感。AMD的GPU由於SIMD架構的龐大流處理器優勢遙遙領先於NVIDIA GPU。
高清視訊轉碼:N卡略快於A卡
Cyberlink(訊連科技)旗下大名鼎鼎PowerDVD相信大家都非常熟悉,作為一家專注視訊與多媒體的軟體開發商,Cyberlink不久前推出了一款專業的快速視訊轉換軟體——MediaShow Espresso,需要注意的是MediaShow(魅力四射)是一款視訊編輯軟體,而MediaShow Espresso才是視訊轉換軟體。

現在編碼解碼軟體滿天飛,但是MediaShow Espresso卻有它的獨到之處。它是第一款同時支援CUDA與Stream加速的視訊轉換軟體,除此之外它還對IntelCorei7處理器的超執行緒及SSE4指令集做了優化,因此無論純CPU轉碼還是GPU加速,其速度比傳統軟體都要快。
測試視訊檔案為長度為3分42秒位元速率22M的H.264編碼的M2TS檔案。測試中我們開啟GPU解碼與GPU編碼選項,將編解碼工作交由GPU來完成。
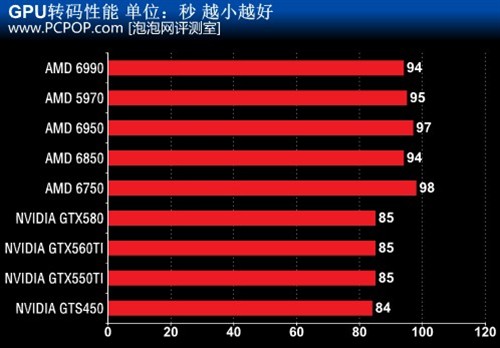
可以看出,GPU視訊轉碼時,CPU和GPU都要參加計算,而且GPU不需要盡全力,所以高階GPU和中端GPU的效能是差不多的。總體來看N卡的CUDA效能要優於A卡的Stream效能。
值得注意的是,本次測試使用的是同時支援CUDA和Stream的MediaShow Espresso進行測試,如果使用僅支援CUDA的MediaCoder軟體的話,N卡的視訊轉碼速度還能更快,這方面A卡無論效能還是軟體支援度都不如N卡。
DirectCompute理論效能:A卡略佔優勢
ComputeMark由捷克硬體和遊戲網站CzechGamer.com的Robert Varga開發製作,引擎是基於Jan Vlietinck的Fluid3D Demo。軟體能夠使顯示卡佔用率達到99%,而CPU佔用率僅0-1%,避免由CPU效能造成對測試成績的影響。同時該軟體還有功耗測量的功能,測試時間可以隨意設定。
ComputeMark需要在純DX11環境下執行,包括Windows 7 32/64位作業系統、DX11 API和DX11顯示卡。

最終結果很和諧,雖然A卡的理論浮點運算能力很高,但在DirectCompute理論測試當中,同級別的A卡並不比N卡高多少。因為DirectCompute現階段主要還是在遊戲當中使用,因此意義不是很大。
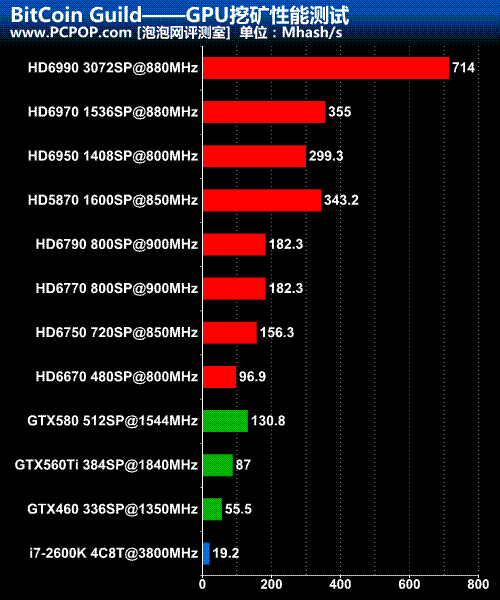
Bitcoin挖礦效能測試:A卡絕對優勢
如果您還不瞭解比特幣的話,不妨看看前不久我們的評測文章《掛機也能賺錢?教你用顯示卡挖礦賺美元》。這裡就直接引用測試資料:
下面筆者做個簡要分析:
1. HD6990擁有兩顆GPU,核心頻率與單核心的HD6970完全相同,所以挖礦效能正好翻倍。事實上HD6990就是需要開兩個挖掘器分配給兩顆GPU一起計算。
2. AMD上代HD5870流處理器稍多於HD6970,但核心頻率稍低,最終兩代旗艦單卡的挖礦效能差不多。要知道VLIW4架構的HD6970遊戲效能要強於VLIW5架構的HD5870,但挖礦效能似乎只取決於理論浮點運算能力,跟架構和效率毫無關係。
3. Barts核心的HD6790擁有256Bit視訊記憶體位寬,比128Bit的HD6770大一倍。但兩者的挖礦效能完全相同,所以視訊記憶體位寬頻率對效能沒有任何影響,影響效能的唯一因素就是流處理器數量及頻率。
4. NV頂級單卡GTX580還不如HD6750,但要比CPU強很多,畢竟它也有數百顆核心。
那為什麼A卡和N卡的差距如此之大呢?比特幣挖掘器採用的是SHA-256,這是由美國國家安全域性發明的一種安全雜湊函式,一般用於密碼加密與解密。這種演算法會進行大量32位整數迴圈右移運算,這個操作在AMD GPU那裡可以通過單一硬體指令實現,而在NVIDIA GPU那裡需要三次硬體指令來模擬(2移+1加),僅這一條就為AMD帶來額外的1.7倍運算效率優勢(大約1900指令來執行SHA-256壓縮操作,而不是NVIDIA的大約3250指令)。
如此一來,AMD較高的浮點運算能力再加上演算法效率優勢,AMD GPU在密碼破解與比特幣挖掘時的效能,大概是NVIDIA GPU的3倍以上!
總結:GPU的未來不是遊戲而是計算
通過前面幾項不同型別的通用計算應用來看,A卡和N卡之間的效能差距是相當大的,而且動不動就是幾倍以上的差距。A卡恐怖的理論效能有時候確實有效果,但有時候還是要大幅落後於N卡,這與雙方在3D遊戲中和諧愉快的表現截然相反!
這種奇怪的現象,一方面是由雙方截然不同的架構所造成的,另一方面是不同應用的演算法不同,可能會比較“偏愛”某一種架構。最終,就要看誰在軟體優化方面做得好,誰就能勝出。目前來看CUDA還是佔有明顯的上風,已經有很多超級計算機配備了NVIDIA Tesla加速卡,CUDA的應用軟體還是要比Stream多很多的。

不管CUDA和Stream孰強孰弱,OpenCL和DirectCompute標準誰能笑到最後,GPU的地位顯然在迅速攀升。超級計算機想要在效能上取得突破,使用GPU+CPU的異構架構是唯一選擇,未來高效能運算已經離不開GPU的支援了。
NVIDIA和ATI從3D遊戲戰場打到了通用平行計算領域,到底誰能笑到最後現在還是個未知數。

對於普通使用者來說,顯示卡已經不再是一塊單純的3D遊戲加速卡,以視訊應用為代表的高效能運算軟體率先步入GPU通用計算的大門,未來將會有更多計算軟體使用GPU強大的運算能力來加速,CPU和GPU的地位將變得同等重要。現在,玩家們因一兩款特別喜愛的遊戲而升級顯示卡;將來,或許很多不玩遊戲的人,也會加入到獨立顯示卡的行列!■