
Netty ByteBuf(圖解之 2)| 秒懂
目錄
Netty ByteBuf(圖解二):API 圖解
瘋狂創客圈 Java 分散式聊天室【 億級流量】實戰系列之16 【 部落格園 總入口 】
原始碼工程
寫在前面
大家好,我是作者尼恩。
今天是百萬級流量 Netty 聊天器 打造的系列文章的第16篇,這是一個基礎篇,介紹ByteBuf 的使用。
由於關於ByteBuf的內容比較多,分兩篇文章:
第二篇:圖解 ByteBuf的具體使用
本篇為第二篇。
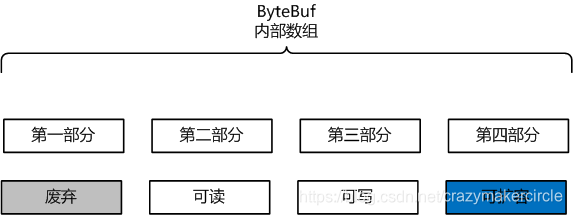
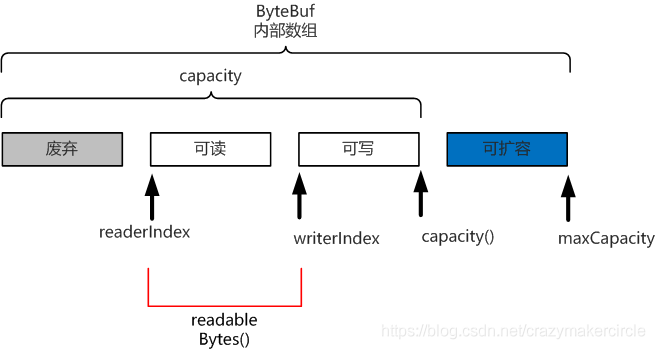
ByteBuf 的四個邏輯部分
ByteBuf 是一個位元組容器,內部是一個位元組陣列。
從邏輯上來分,位元組容器內部,可以分為四個部分:

第一個部分是已經丟棄的位元組,這部分資料是無效的;
第二部分是可讀位元組,這部分資料是 ByteBuf 的主體資料, 從 ByteBuf 裡面讀取的資料都來自這一部分;
第三部分的資料是可寫位元組,所有寫到 ByteBuf 的資料都會寫到這一段。
第四部分的位元組,表示的是該 ByteBuf 最多還能擴容的大小。
四個部分的邏輯功能,如下圖所示:
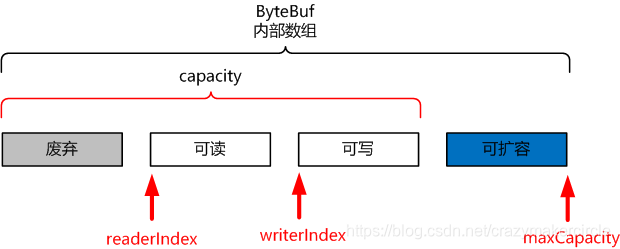
ByteBuf 的三個指標
ByteBuf 通過三個整型的指標(index),有效地區分可讀資料和可寫資料,使得讀寫之間相互沒有衝突。
這個三個指標,分別是:
- readerIndex(讀指標)
- writerIndex(寫指標)
- maxCapacity(最大容量)
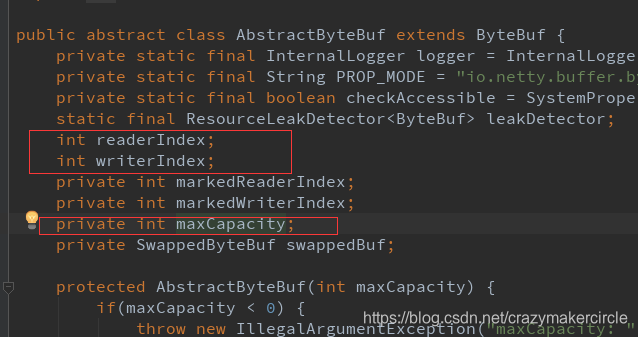
這三個指標,是三個int 型的成員屬性,定義在 AbstractByteBuf 抽象基類中。
三個指標的程式碼截圖,如下:
readerIndex 讀指標
指示讀取的起始位置。
每讀取一個位元組,readerIndex 自增1 。一旦 readerIndex 與 writerIndex 相等,ByteBuf 不可讀 。
writerIndex 寫指標
指示寫入的起始位置。
每寫一個位元組,writerIndex 自增1。一旦增加到 writerIndex 與 capacity() 容量相等,表示 ByteBuf 已經不可寫了 。
capacity()容量不是一個成員屬性,是一個成員方法。表示 ByteBuf 內部的總容量。 注意,這個不是最大容量。
maxCapacity 最大容量
指示可以 ByteBuf 擴容的最大容量。
當向 ByteBuf 寫資料的時候,如果容量不足,可以進行擴容。
擴容的最大限度,直到 capacity() 擴容到 maxCapacity為止,超過 maxCapacity 就會報錯。
capacity()擴容的操作,是底層自動進行的。
ByteBuf 的三組方法
從三個維度三大系列,介紹ByteBuf 的常用 API 方法。

第一組:容量系列
方法 一:capacity()
表示 ByteBuf 的容量,包括丟棄的位元組數、可讀位元組數、可寫位元組數。
方法二:maxCapacity()
表示 ByteBuf 底層最大能夠佔用的最大位元組數。當向 ByteBuf 中寫資料的時候,如果發現容量不足,則進行擴容,直到擴容到 maxCapacity。
第二組:寫入系列
方法一:isWritable()
表示 ByteBuf 是否可寫。如果 capacity() 容量大於 writerIndex 指標的位置 ,則表示可寫。否則為不可寫。
isWritable()的原始碼,也是很簡單的。具體如下:
public boolean isWritable() {
return this.capacity() > this.writerIndex;
}注意:如果 isWritable() 返回 false,並不代表不能往 ByteBuf 中寫資料了。 如果Netty發現往 ByteBuf 中寫資料寫不進去的話,會自動擴容 ByteBuf。
方法二:writableBytes()
返回表示 ByteBuf 當前可寫入的位元組數,它的值等於 capacity()- writerIndex。
如下圖所示:
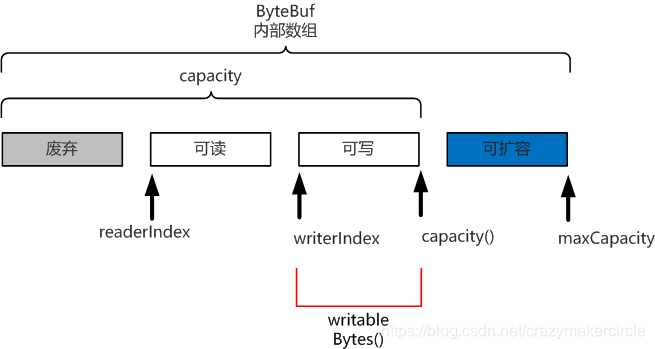
方法三:maxWritableBytes()
返回可寫的最大位元組數,它的值等於 maxCapacity-writerIndex 。
方法四:writeBytes(byte[] src)
把位元組陣列 src 裡面的資料全部寫到 ByteBuf。
這個是最為常用的一個方法。
方法五:writeTYPE(TYPE value) 基礎型別寫入方法
基礎資料型別的寫入,包含了 8大基礎型別的寫入。
具體如下:writeByte()、 writeBoolean()、writeChar()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble() ,向 ByteBuf寫入基礎型別的資料。
方法六:setTYPE(TYPE value)基礎型別寫入,不改變指標值
基礎資料型別的寫入,包含了 8大基礎型別的寫入。
具體如下:setByte()、 setBoolean()、setChar()、setShort()、setInt()、setLong()、setFloat()、setDouble() ,向 ByteBuf 寫入基礎型別的資料。
setType 系列與writeTYPE系列的不同:
setType 系列 不會 改變寫指標 writerIndex ;
writeTYPE系列 會 改變寫指標 writerIndex 的值。
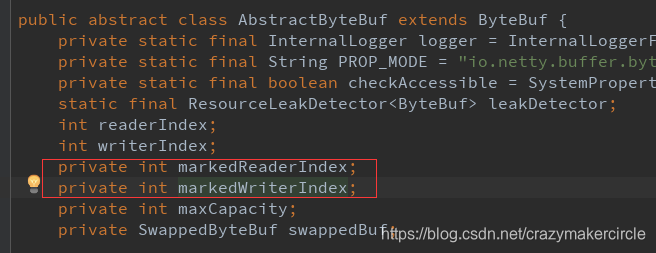
方法七:markWriterIndex() 與 resetWriterIndex()
這裡兩個方法一起介紹。
前一個方法,表示把當前的寫指標writerIndex 儲存在 markedWriterIndex 屬性中;
後一個方法,表示把當前的寫指標 writerIndex 恢復到之前儲存的 markedWriterIndex 值 。
標記 markedWriterIndex 屬性, 定義在 AbstractByteBuf 抽象基類中。
截圖如下:
第三組:讀取系列
方法一:isReadable()
表示 ByteBuf 是否可讀。如果 writerIndex 指標的值大於 readerIndex 指標的值 ,則表示可讀。否則為不可寫。
isReadable()的原始碼,也是很簡單的。具體如下:
public boolean isReadable() {
return this.writerIndex > this.readerIndex;
}方法二:readableBytes()
返回表示 ByteBuf 當前可讀取的位元組數,它的值等於 writerIndex - readerIndex 。
如下圖所示:
方法三: readBytes(byte[] dst)
把 ByteBuf 裡面的資料全部讀取到 dst 位元組陣列中,這裡 dst 位元組陣列的大小通常等於 readableBytes() 。 這個方法,也是最為常用的一個方法。
方法四:readType() 基礎型別讀取
基礎資料型別的讀取,可以讀取 8大基礎型別。
具體如下:readByte()、readBoolean()、readChar()、readShort()、readInt()、readLong()、readFloat()、readDouble() ,從 ByteBuf讀取對應的基礎型別的資料。
方法五:getTYPE(TYPE value)基礎型別讀取,不改變指標值
基礎資料型別的讀取,可以讀取 8大基礎型別。
具體如下:getByte()、 getBoolean()、getChar()、getShort()、getInt()、getLong()、getFloat()、getDouble() ,從 ByteBuf讀取對應的基礎型別的資料。
getType 系列與readTYPE系列的不同:
getType 系列 不會 改變讀指標 readerIndex ;
readTYPE系列 會 改變讀指標 readerIndex 的值。
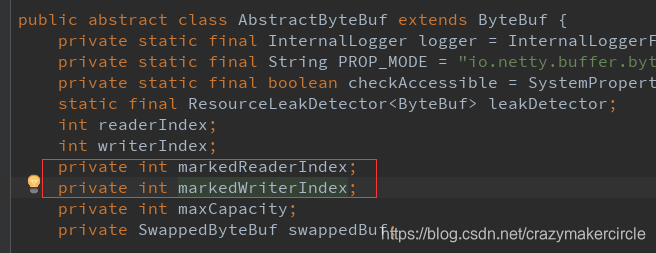
方法六:markReaderIndex() 與 resetReaderIndex()
這裡兩個方法一起介紹。
前一個方法,表示把當前的讀指標ReaderIndex 儲存在 markedReaderIndex 屬性中。
後一個方法,表示把當前的讀指標 ReaderIndex 恢復到之前儲存的 markedReaderIndex 值 。
標記 markedReaderIndex 屬性, 定義在 AbstractByteBuf 抽象基類中。
截圖如下:
ByteBuf 的引用計數
Netty 的 ByteBuf 的記憶體回收工作,是通過引用計數的方式管理的。
大致的引用計數的規則如下:
- 預設情況下,當建立完一個 ByteBuf 時,它的引用為1。
- 每次呼叫 retain()方法, 它的引用就加 1 ;
- 每次呼叫 release() 方法,是將引用計數減 1。
如果引用為0,再次訪問這個 ByteBuf 物件,將會丟擲異常。
如果引用為0,表示這個 ByteBuf 沒有地方被引用到,需要回收記憶體。
Netty的記憶體回收分為兩種情況:
- Pooled 池化的記憶體,放入可以重新分配的 ByteBuf 池子,等待下一次分配。
- Unpooled 未池化的 ByteBuf 記憶體,確保GC 可達,確保 能被 JVM 的 GC 回收器回收到。
ByteBuf 的淺層複製
ByteBuf 的淺層複製分為兩種,有切片slice 淺層複製,和duplicate 淺層複製。

slice 切片淺層複製
首先說明一下,這是一種非常重要的操作。可以很大程度的避免記憶體拷貝。這一點,對於大規模訊息通訊來說,是非常重要的。
slice 操作可以獲取到一個 ByteBuf 的一個切片。一個ByteBuf,可以進行多次的切片操作,多個切片可以共享一個儲存區域的 ByteBuf 物件。
slice 操作方法有兩個過載版本:
- public ByteBuf slice();
public ByteBuf slice(int index, int length);
兩個版本有非常緊密的聯絡。
不帶引數的 slice 方法,等同於 buf.slice(buf.readerIndex(), buf.readableBytes()) 呼叫, 即返回 ByteBuf 例項中可讀部分的切片。
而帶引數 slice(int index, int length) 方法,可以通過靈活的設定不同的引數,來獲取到 buf 的不同區域的切片。
呼叫slice()方法後,返回的 ByteBuf 的切片,大致如下圖:
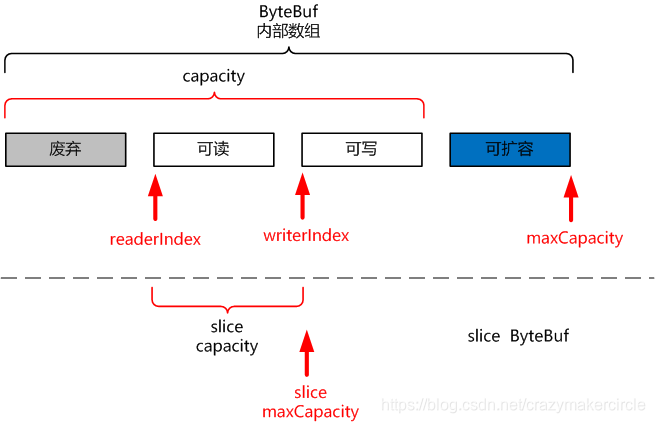
呼叫slice()方法後,返回的ByteBuf 切片的屬性,大致如下:
slice 的 readerIndex(讀指標)的值為 0
slice 的 writerIndex(寫指標) 的 值為源Bytebuf的 readableBytes() 可讀位元組數。
slice 的 maxCapacity(最大容量) 的值為源Bytebuf的 readableBytes() 可讀位元組數。maxCapacity 與 writerIndex 值相同,切片不可以寫。
切片的可讀位元組數,為自己的 writerIndex - readerIndex。所有,切片和源Bytebuf的 readableBytes() 可讀位元組數相同。
也就是說,切片可讀,不可寫。
slice()切片和原ByteBuf的聯絡:
- 切片不會拷貝原ByteBuf底層資料,底層陣列和原ByteBuf的底層陣列是同一個
- 切片不會改變原 ByteBuf 的引用計數。
根本上,呼叫slice()方法生成的切片,是 源Bytebuf 可讀部分的淺層複製。
下面的例子展示了 ByteBuf.slice 方法的演示:
public static void testSlice() {
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(9, 100);
print("allocate ByteBuf(9, 100)", buffer);
buffer.writeBytes(new byte[]{1, 2, 3, 4});
print("writeBytes(1,2,3,4)", buffer);
ByteBuf buffer1= buffer.slice();
print("buffer slice", buffer1);
}結果如下:
after ===========allocate ByteBuf(9, 100)============
capacity(): 9
maxCapacity(): 100
readerIndex(): 0
readableBytes(): 0
isReadable(): false
writerIndex(): 0
writableBytes(): 9
isWritable(): true
maxWritableBytes(): 100
after ===========writeBytes(1,2,3,4)============
capacity(): 9
maxCapacity(): 100
readerIndex(): 0
readableBytes(): 4
isReadable(): true
writerIndex(): 4
writableBytes(): 5
isWritable(): true
maxWritableBytes(): 96
after ===========buffer slice============
capacity(): 4
maxCapacity(): 4
readerIndex(): 0
readableBytes(): 4
isReadable(): true
writerIndex(): 4
writableBytes(): 0
isWritable(): false
maxWritableBytes(): 0
duplicate() 淺層複製
duplicate() 返回的是源ByteBuf 的整個物件的一個淺層複製,包括如下內容:
- duplicate() 會建立自己的讀寫指標,但是值與源ByteBuf 的讀寫指標相同;
- duplicate() 不會改變源 ByteBuf 的引用計數
- duplicate() 不會拷貝 源ByteBuf 的底層資料
duplicate() 和slice() 方法,都是淺層複製。不同的是,slice() 方法是切取一段的淺層複製,duplicate() 是整個的淺層複製。
淺層複製的問題
淺層複製方法不會拷貝資料,也不會改變 ByteBuf 的引用計數,這就會導致一個問題。
在源 ByteBuf 呼叫 release() 之後,引用計數為零,變得不能訪問。這個時候,源 ByteBuf 的淺層複製例項,也不能進行讀寫。如果再對淺層複製例項進行讀寫,就會報錯。
因此,在呼叫淺層複製例項時,可以通過呼叫一次 retain() 方法 來增加引用,表示它們對應的底層的記憶體多了一次引用,引用計數為2,在淺層複製例項用完後,需要呼叫兩次 release() 方法,將引用計數減一,不影響源ByteBuf的記憶體釋放。
寫在最後
至此為止,終於完成ByteBuf的具體使用B介紹。
如果想知道ByteBuf的分配、釋放, 請看:
瘋狂創客圈 Java 死磕系列
Java (Netty) 聊天程式【 億級流量】實戰 開源專案實戰
- Netty 原始碼、原理、JAVA NIO 原理
- Java 面試題 一網打盡