
MapReduce分散式計算
阿新 • • 發佈:2018-12-22
MapReduce-分散式計算筆記
簡介
1.什麼是MapReduce
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
2.MapReduce組成
Map端
Reduce端
3.MapReduce核心思想
“相同”的key為一組,呼叫一次Reduce方法,方法內迭代這一組資料進行計算
原理
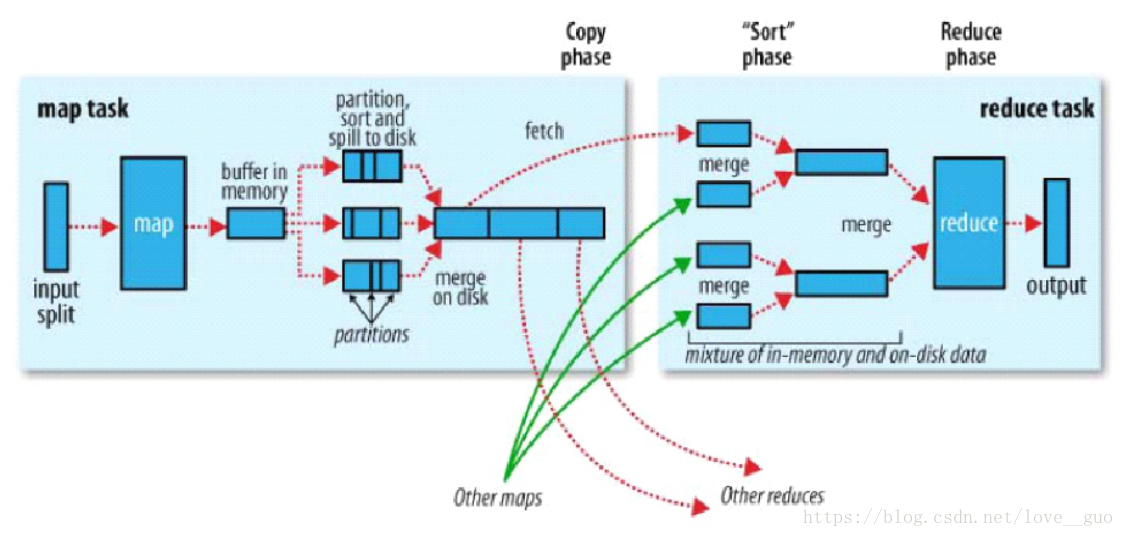
1.map task
1.1.map task端從HDFS叢集上拿資料
一個map task由一個split切片,因為HDFS叢集上是block塊(按位元組切割)儲存資料,可能回導致亂碼,預設情況下,1個split切片 ≈ 1個block塊
目的:防止資料被分開
1.2.map task將資料拉入記憶體
1.將處理後的每條記錄打上標籤,目的是明確這一條記錄將來被哪一個reduce task處理 打標籤由分割槽完成,預設的分割槽器是HashPartitioner。 分割槽策略是根據key的HashCode與reduce task NUM 取模 進入記憶體中的每一條記錄都由分割槽號、key、value組成 2.記憶體中的資料超過預設的80M後,這80M記憶體回被封鎖,然後對這80M的資料進行combiner(小聚合)
1.3.將記憶體中的資料寫入磁碟小檔案中
1.將相同分割槽的資料放在一起,分割槽內的資料按照key值進行一定的排序
1.4.磁碟小檔案合併成一個大檔案
1.在map task計算完畢後進行合併
2.合併時使用歸併排序演算法
3.產生一個有分割槽且分割槽內部有序的大檔案
1.2-1.4又稱為shuffle write階段
有序大檔案:提高分組的分組效率
2.reduce task
1.去map端讀取相應的分割槽資料,
2.將分割槽資料寫入記憶體中,記憶體滿時回溢寫,溢寫之前會排序,寫入磁碟小檔案中
3.當資料讀取、排序完畢後,將磁碟小檔案合併、排序成一個大檔案
2.1-2.2,又被稱為shuffle read階段
3.總結
3.1Map
1.讀懂資料
2.對映為hey-value模型
3.並行分散式
4.計算向資料移動
3.2Reduce
1.Reduce中可以包含不同的key
2.相同的key匯聚到一個Reduce中,相同的key呼叫一次reduce方法
YARN
1.前身
在hadoop1.x版本中,MapReduce框架中自帶了一個資源排程器。
1.MapReduce執行流程
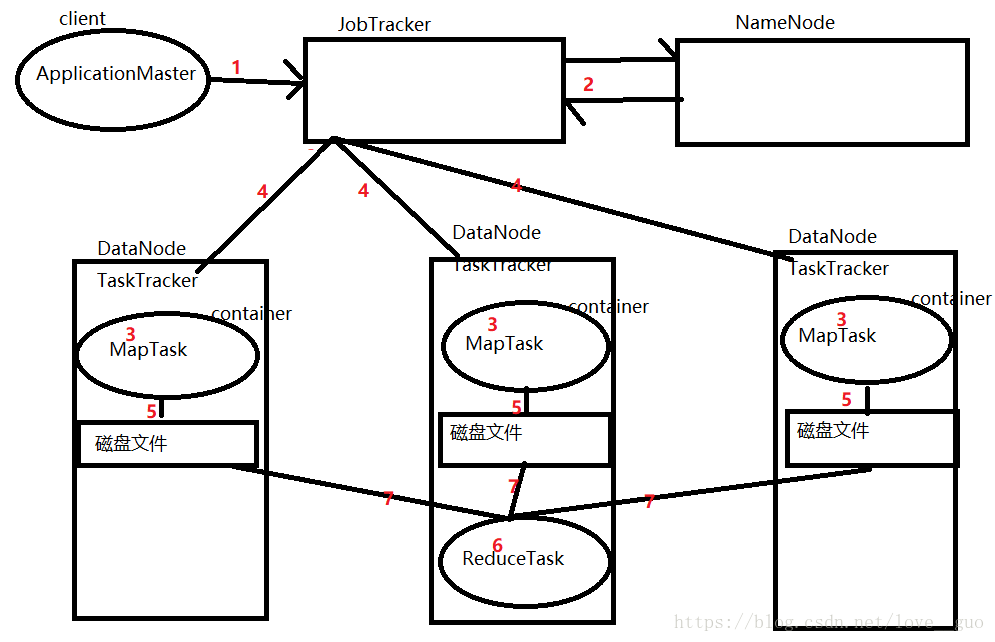
1.客戶端將MapReduce任務提交給JobTracker
hadoop jar
2.JobTracker向NameNode請求計算檔案的block位置
3.通知各個TaskTracker在各自節點上啟動一個container(容器)
4.JobTracker向TaskTracker上按照資料位置分發任務MapTask(資料本地化)
5.MapTask計算完畢後,每一個MapTask都會產生一個大檔案
6.JobTracker告訴某一臺TaskTracker節點啟動一個container,在container中啟動一個ReduceTask程序
7.ReduceTask將MapTask產生的檔案拉取過來,計算完畢後,傳到HDFS叢集上
資料本地化是指資料不移動,計算移動(即計算向資料移動)
目的是為了減少網路IO
ReduceTask最好是與MapTask在同一節點上,減少網路IO
2.總結
2.1JobTracker
1.核心,單點,主節點
2.排程所有的作業
3.監控整個叢集的資源負載
2.2TaskTracker
1.從節點,自身節點資源管理
2.向JobTracker彙報資源,獲取Task
2.3弊端
1.JobTracker負載過高,容易出現單點故障
2.資源管理與計算排程強耦合,其他計算框架需要重複實現資源管理
3.不同框架對資源不能全域性管理,存在資源強度和資源隔離問題
2.YARN
1.核心思想
將JobTracker的資源管理和任務排程兩個功能分開,分別由ResourceManager和ApplicationMaster程序實現。
2.角色
2.1ResourceManager
1.主節點、資源排程器的核心
2.叢集節點資源管理
2.2NodeManager
1.向ResourceManager彙報資源
2.管理Container生命週期
2.3Container
1.預設NodeManager啟動執行緒監控COntainer大小,超出申請資源額度就kill
2.支援Linux核心的Cgroup
2.4ApplicationMaster
負責應用程式相關的事務,比如任務排程、任務監控和容錯等
3.流程
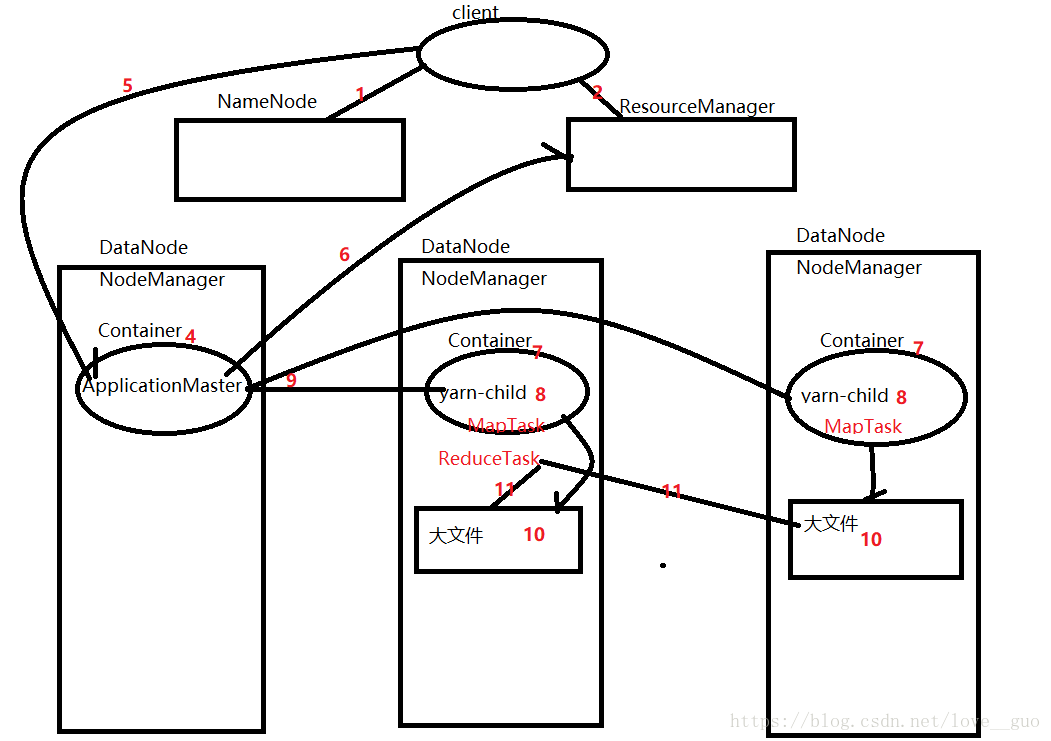
1.client拿到MR Application計算檔案的路徑,從NameNode獲取每一個block的位置,形成一個報表
2.client向ResourceManager請求,申請ApplicationMaster資源
3.ResourceManager接受client請求,然後檢視哪一個節點資源充足,如果大部分節點資源充足,那就隨機找一臺節點(例如node01)啟動Container容器
4. node01上的NodeManager會在Container容器中啟動一個ApplicationMaster(負責任務排程)
5.client將報表交給ApplicationMaster
6.ApplicationMaster根據報表向ResourceManager申請資源
7.ResourceManager根據申請檢視節點資源是否充足,在資源充足的節點上啟動Container容器
8.對應的NodeManager在Container中啟動yarn-child程序
9.ApplicationMaster向各個yarn-child中分發MapTask執行緒
10.MapTask計算完畢後,會生成對應的磁碟檔案
11.ApplicationMaster分發ReduceTask執行緒
最好是在MapTask執行緒所在的節點上,減少網路IO
12.ReduceTask執行緒執行完畢後,將結果寫入HDFS叢集上
4.優勢
1.避免了單點故障
2.使得多個計算框架可以執行在一個叢集中
環境搭建
1.叢集規劃
在之前搭建的高可用叢集上搭建YARN叢集
| NameNode1 | NameNode2 | DataNode | Zookeeper | ZKFC | JournalNode | ResourceManager | NodeManager | |
|---|---|---|---|---|---|---|---|---|
| node01 | √ | √ | √ | √ | ||||
| node02 | √ | √ | √ | √ | √ | √ | √ | |
| node03 | √ | √ | √ | √ | ||||
| node04 | √ | √ | √ |
2.修改配置檔案
2.1mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2.2yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node02</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
3.啟動yarn叢集
3.1在node01上執行
start-yarn.sh
3.2在node02上執行
yarn-daemon.sh start resourcemanager
4.測試
4.1進入hadoop_home下的share/hadoop/mapreduce目錄
4.2執行用例
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /input /output
/input是HDFS叢集下的目錄,目錄下需要放一個或多個存有英文單詞或語句的檔案