
用gensim做LDA實踐之文字分類
之前看LDA,一直沒搞懂到底作用是什麼,公式推導了一大堆,dirichlet分佈求了一堆倒數,卻沒有真正理解精髓在哪裡。
最近手上遇到了一個文字分類的問題,採用普通的VSM模型的時候,執行的太慢,後來查詢改進策略的時候,想起了LDA,因此把LDA重新拉回我的視線,也終於弄懂了到底是做什麼的。
LDA本質是一種降維
為什麼這麼說,因為在我的文字分類問題中,文字共有290w個,根據詞項得到的維度為90w個,這樣一個巨大的矩陣【尤其是維度過多】扔到分類器裡,肯定會有各種各樣的問題【比如訓練過慢,過擬合,等等】
因此,LDA的出現,能讓VSM模型的列,由詞項變成“主題”。這也就是主題模型的來歷吧。
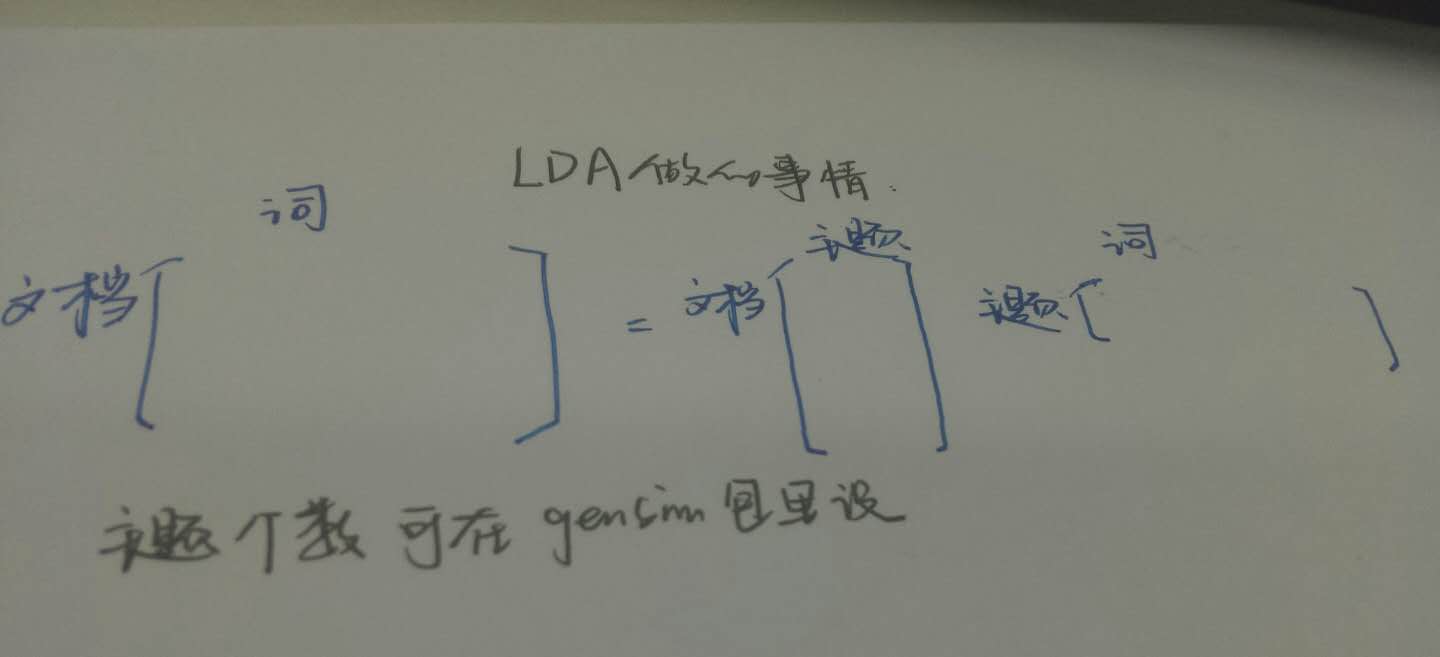
文件——主題矩陣
先看一個簡單的:LSI 隱語意索引。基本方法是SVD矩陣分解
現在我們開始分析這兩個矩陣各自長啥樣:
文件——主題矩陣求出來之後,是這樣的

在這裡,我定義了200個主題,現只截圖了前25個主題。
需要說明的是,這個是第一個文件的主題分佈。我們可以看到,第一個樣本的第6,第7個主題明顯得分更高一些。至於主題都是“什麼主題”,需要人自己通過“主題——詞”矩陣觀看,並給出
【其實,並不需要定義每個主題是什麼,其實只是一列,並放在分類器裡用就可以了。】
其實,我們降維得到的這個矩陣,就可以放在分類器裡面用了。
LDA得到的主題表徵:
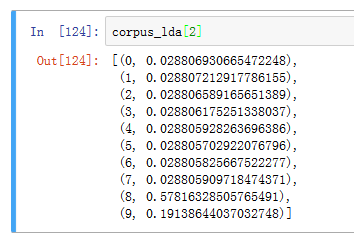
LDA神奇之處在於,如果我定義了200個主題,那麼我得到corpus_lda的時候,比如要看第二個樣本的主題,它不會像LSI一樣全部顯示出來,而是選擇性地顯示幾個大的。
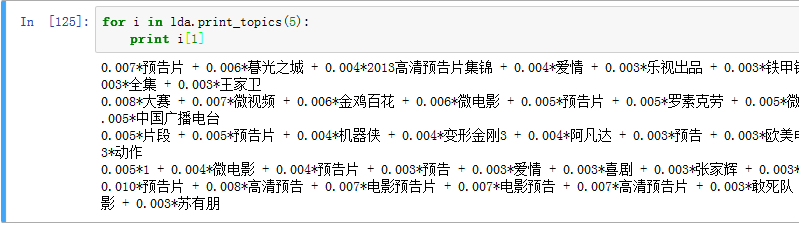
主題——詞矩陣
同樣地,如果想看每個主題都有哪些詞,也就是主題——詞矩陣,那麼可以看到:
總結
最後,【在文字分類中】其實我們要做的,就是從文字——詞項矩陣變為文字——主題【維度為200】矩陣,通過降維的方式,對文字分類。其中的值由詞項的TF-IDF值變為了主題的權重得分值。
附上整個lda的過程的步驟和程式碼:
第一步,把待轉換成詞袋的詞變成需要的型別
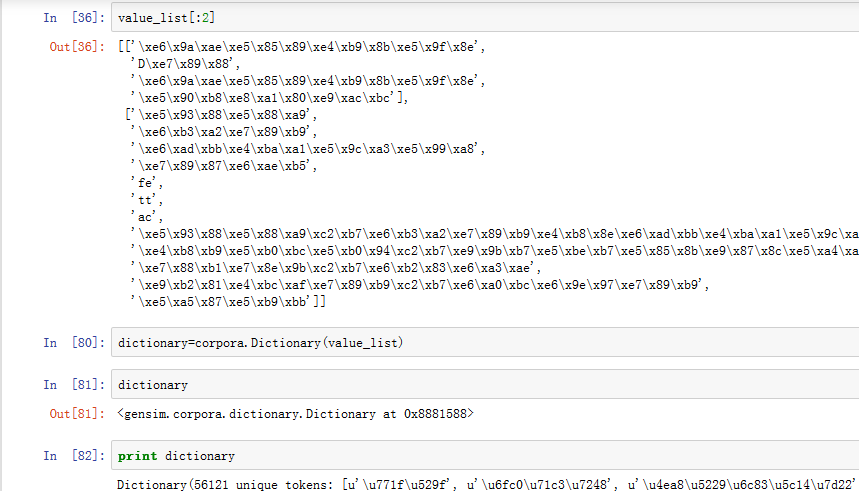
通過學習value_list得到我們的字典。【注意:value_list的格式】
第二步:把所有文件根據字典轉換成VSM
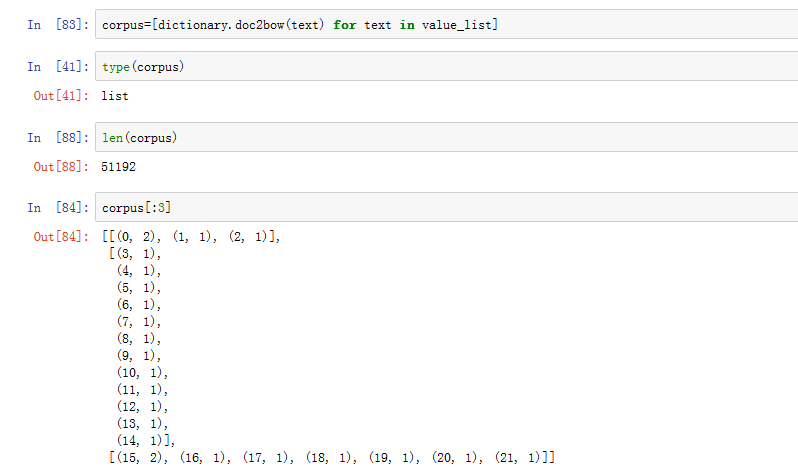
現在得到的corpus利用了字典,把每一個文件變成了一個一個tuple組合的形式,key為ID,value為出現的頻數
第三步,把頻數變為tfidf值【用corpus訓練】
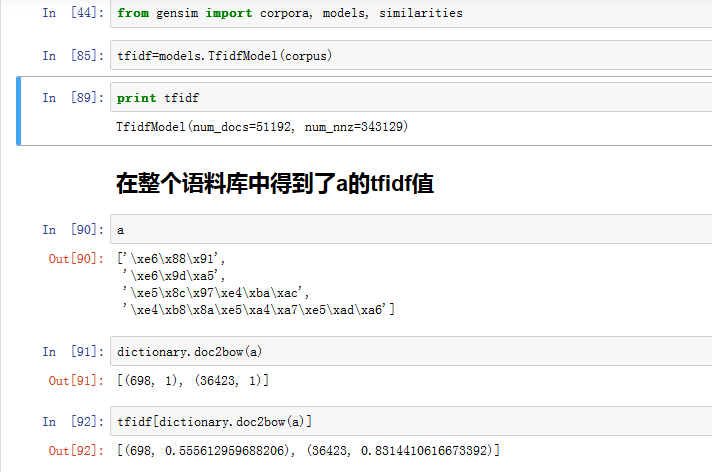
此時,可以轉換一個文件,方法:先用dictionary的dic2bow方法變成詞頻,再把詞頻變為tfidf頻率
第四步:用訓練好的tfidf把測試文件變為tfidf格式

第五步:把規整後的tfidf矩陣放進LSI,LDA模型中
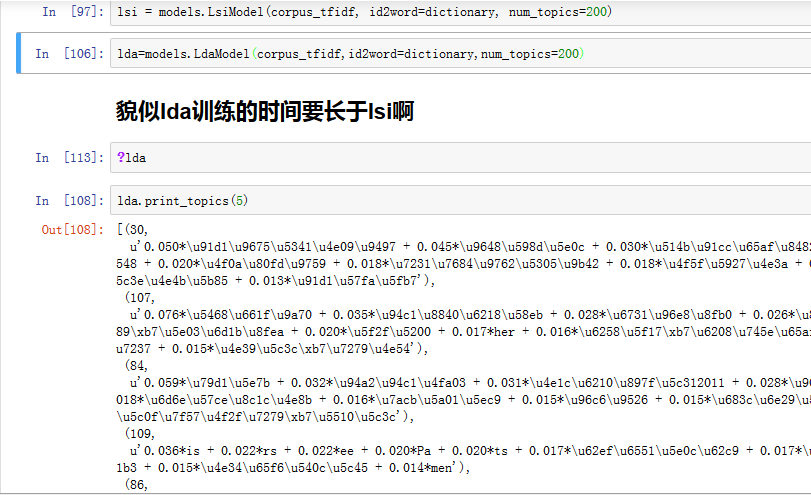
所以說實際上沒有做輿情的話,我是沒有用到主題——詞項矩陣的。這個充其量是讓我理解“這個主題是講的什麼東西”。
另外,多說一句。短文字【標籤,名稱】並不適合做LDA,因為一個文件裡的標籤太少了,LDA並不能發揮其真正效果