
自然語言處理之文字分類
一、前言
文字分類(Text Classification或Text Categorization,TC),或者稱為自動文字分類(Automatic Text Categorization),是指計算機將載有資訊的一篇文字對映到預先給定的某一類別或某幾類別主題的過程。文字分類另外也屬於自然語言處理領域。文字分類的應用場景有:
1. 新聞主題分類(文章分類):根據文章內容(或者結合標題)給新聞等其他文章一個類別,比如財經、體育、軍事、明星等等。一般在新聞資訊方面使用比較多。
2. 情感分析:兩類(正面、負面)或者多類(例如,生氣、高興、悲傷等等),其實還是有三類(正、負、中性),不過和兩類的處理方法會有些許區別。一般在影評(比如豆瓣、淘票票)、商品評價(比如淘寶、京東的商品評價)等對商品和服務的評價方面應用比較多。
3. 輿情分析:和情感分類類似,更多的是兩分類,政府或者金融機構用的比較多。
4. 郵件過濾:比如鑑定一封郵件是否是騷擾或者廣告營銷等垃圾郵件。
5. 作為其他自然語言處理系統的一部分,比如問答系統中對問句進行主題分類。
文字分類系統如下圖所示:
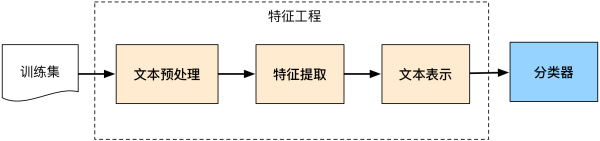
二、資料採集
資料採集是文字挖掘的基礎,主要包括爬蟲技術和頁面處理。
2.1 爬蟲技術
Web資訊檢索的第一步就是要抓取網路文件,爬蟲就承擔瞭解決這一問題的主要責任。爬蟲有很多種型別,但最典型的就是網路爬蟲。網路爬蟲通過跟蹤網頁上的超連結來搜尋並下載新的頁面。似乎聽起來該過程比較簡單,但是如何能夠高效處理Web上出現的大量新頁面,如何處理已抓取頁面的更新頁面,如何保持頁面的最新性,這些問題都成為網路爬蟲設計富有挑戰的難題。網路爬蟲抓取任務可以限定在一個比較小的範圍內,例如一個公司,一個網站,或者一所大學的站點。主題網路爬蟲與話題網路爬蟲要採用分類技術來限制所搜尋頁面屬於同一主題類別。
2.2 頁面處理
通過網路爬蟲抓取的頁面是最原始的Web頁面,它們的格式多種多樣,如HTML、XML、Adobe PDF、Microsoft Word等等。這些web頁面含有大量的噪聲資料,包括導航欄、廣告資訊、Web標籤、超連結或者其他非內容格式資料等,這些資料幾乎都成是阻礙文字下一步處理的因素。因此需要經過預處理去除上述噪音資料,將Web頁面轉化成為純淨統一的文字格式和元資料格式。Web關注內容過濾也是Web資訊處理領域的一項熱門研究課題。
另外一個普遍存在的頁面處理問題是編碼不一致。由於計算機發展、民族語言、國家地域的不同造成現在計算機儲存資料採用許多種編碼格式,例如ASCII、UTF-8、GBK、BIG5等等。在實際應用過程中,在對不同編碼格式的文件進行深入處理之前,必須要保證對它們編碼格式進行統一轉換。
三、文字預處理
文字要轉化成計算機可以處理的資料結構,就需要將文字切分成構成文字的語義單元。這些語義單元可以使句子、短語、詞語或單個的字。本文無論對於中文還是英文文字,統一將最小語義單元稱為“片語”。對於不同的語言來說處理有所區別,下面簡述最常見的中文和英文文字的處理方式。
3.1 英文處理
英文文字的處理相對簡單,每一個單詞之間有空格或標點符號隔開。如果不考慮短語,僅以單詞作為唯一的語義單元的話,處理英文單詞切分相對簡單,只需要分割單詞,去除標點符號。英文還需要考慮的一個問題是大小寫轉換,一般認為大小寫不具有不同的意義,這就要求將所有單詞的字幕都轉換成小寫或大寫。另外,英文文字預處理更為重要的問題是詞根的還原,或稱詞幹提取。詞根還原的任務就是將屬於同一個詞幹(Stem)的派生詞進行歸類轉化為統一形式。例如,把“computed”, “computer”, “computing”可以轉化為“compute”。通過使用一個給定的詞來代替一類中每一個元素,可以進一步增加類別與文件中的詞之間匹配度。詞根還原可以針對所有詞進行,也可以針對少部分詞進行或者不採用詞根還原。針對所有詞的詞根還原可能導致分類結果的下降,這主要的原因或許是刪除了不同形式單詞所含有的形式意義。哪些詞在哪些應用中應該詞根還原尚不清楚。McCallum等人研究工作顯示,詞根還原可能有損於分類效能。
3.2 中文分詞技術
為什麼分詞處理?因為研究表明特徵粒度為詞粒度遠遠好於字粒度,其大部分分類演算法不考慮詞序資訊,基於字粒度的損失了過多的n-gram資訊。
中文分詞主要分為兩類方法:基於詞典的中文分詞和基於統計的中文分詞。
- 基於詞典的中文分詞
核心是首先建立統一的詞典表,當需要對一個句子進行分詞時,首先將句子拆分成多個部分,將每一個部分與字典一一對應,如果該詞語在詞典中,分詞成功,否則繼續拆分匹配直到成功。
所以:字典,切分規則和匹配順序是核心。
- 基於統計的中文分詞方法
統計學認為分詞是一個概率最大化問題,即拆分句子,基於語料庫,統計相鄰的字組成的詞語出現的概率,相鄰的詞出現的次數多,就出現的概率大,按照概率值進行分詞,所以一個完整的語料庫很重要。
- 基於理解的分詞方法
基於理解的分詞方法是通過讓計算機模擬人對句子的理解,達到識別詞的效果。其基本思想就是在分詞的同時進行句法、語義分析,利用句法資訊和語義資訊來處理歧義現象。它通常包括三個部分:分詞子系統、句法語義子系統、總控部分。在總控部分的協調下,分詞子系統可以獲得有關詞、句子等的句法和語義資訊來對分詞歧義進行判斷,即它模擬了人對句子的理解過程。這種分詞方法需要使用大量的語言知識和資訊。由於漢語語言知識的籠統、複雜性,難以將各種語言資訊組織成機器可直接讀取的形式,因此目前基於理解的分詞系統還處在試驗階段。
3.3 去停用詞
停用詞(Stop Word)是一類普遍純在與文字中的常用詞,並且脫離語境它們本身並不具有明顯的意義。最常用的詞是一些典型的功能詞,這些詞構成句子的結構,但對於描述文字所表述的意義幾乎沒有作用,並且容易造成統計偏差,影響機器學習效果。在英文中這詞如:“the”、“of”、“for”、“with”、“to”等,在中文中如:“啊”、“了”、“並且”、“因此”等。由於這些詞的用處太普遍,去除這些詞,對於文字分類來說沒有什麼不利影響,相反可能改善機器學習效果。停用詞去除元件的任務比較簡單,只需從停用詞表中剔除定義為停用詞的常用詞就可以了。儘管停用詞去除簡單,含有潛在優勢,但是停用詞去除與詞根還原具有同樣的問題,定義停用詞表中應該包含哪些詞確是比較困難,一般科研中停用詞表的規模為幾百。
四、文字特徵提取
4.1 詞袋模型
思想:
建立一個詞典庫,該詞典庫包含訓練語料庫的所有詞語,每個詞語對應一個唯一識別的編號,利用one-hot文字表示。
文件的詞向量維度與單詞向量的維度相同,每個位置的值是對應位置詞語在文件中出現的次數,即詞袋模型(BOW)
問題:
(1)容易引起維度災難問題,語料庫太大,字典的大小為每個詞的維度,高維度導致計算困難,每個文件包含的詞語數少於詞典的總詞語數,導致文件稀疏。(2)僅僅考慮詞語出現的次數,沒有考慮句子詞語之間的順序資訊,即語義資訊未考慮
4.2 TF-IDF文字特徵提取
利用TF和IDF兩個引數來表示詞語在文字中的重要程度。
TF是詞頻:指的是一個詞語在一個文件中出現的頻率,一般情況下,每一個文件中出現的詞語的次數越多詞語的重要性更大,例如BOW模型一樣用出現次數來表示特徵值,即出現文件中的詞語次數越多,其權重就越大,問題就是在長文件中 的詞語次數普遍比短文件中的次數多,導致特徵值偏向差異情況。
TF體現的是詞語在文件內部的重要性。
IDF是體現詞語在文件間的重要性:即如果某個詞語出現在極少數的文件中,說明該詞語對於文件的區別性強,對應的特徵值高,IDF值高,IDFi=log(|D|/Ni),D指的是文件總數,Ni指的是出現詞語i的文件個數,很明顯Ni越小,IDF的值越大。
最終TF-IDF的特徵值的表示式為:$TF-IDF(i,j)=TF_{ij}*IDF_{i}$
4.3 基於詞向量的特徵提取模型
想基於大量的文字語料庫,通過類似神經網路模型訓練,將每個詞語對映成一個定維度的向量,維度在幾十到化百維之間,每個向量就代表著這個詞語,詞語的語義和語法相似性和通過向量之間的相似度來判斷。
常用的word2vec主要是CBOW和skip-gram兩種模型,由於這兩個模型實際上就是一個三層的深度神經網路,其實NNLM的升級,去掉了隱藏層,由輸入層、投影層、輸出層三層構成,簡化了模型和提升了模型的訓練速度,其在時間效率上、語法語義表達上效果明顯都變好。word2vec通過訓練大量的語料最終用定維度的向量來表示每個詞語,詞語之間語義和語法相似度都可以通過向量的相似度來表示。
五、分類模型
5.1 傳統機器學習方法
大部分機器學習方法都在文字分類領域有所應用,比如樸素貝葉斯分類演算法(Naïve Bayes)、KNN、SVM、最大熵和神經網路等等。
5.2 深度學習文字分類模型
5.2.1 FastText
5.2.1.1 FastText使用場景
FastText是Facebook AI Research在16年開源的一種文字分類器。 其特點就是fast。相對於其它文字分類模型,如SVM,Logistic Regression等模型,fastText能夠在保持分類效果的同時,大大縮短了訓練時間。
5.2.1.2 FastText的幾個特點
- 適合大型資料+高效的訓練速度:能夠訓練模型“在使用標準多核CPU的情況下10分鐘內處理超過10億個詞彙。
- 支援多語言表達:利用其語言形態結構,FastText能夠被設計用來支援包括英語、德語、西班牙語、法語以及捷克語等多種語言。FastText 的效能要比 Word2Vec 工具明顯好上不少。
- FastText專注於文字分類。它適合類別特別多的分類問題,如果類別比較少,容易過擬合
5.2.1.3 FastText原理
FastText方法包含三部分,模型架構,層次SoftMax和N-gram特徵。
5.2.1.4 模型架構
FastText模型架構和 Word2Vec 中的 CBOW 模型很類似,因為它們的作者都是Facebook的科學家Tomas Mikolov。不同之處在於,FastText預測標籤,而CBOW 模型預測中間詞。
-
CBOW的架構:輸入的是w(t)的上下文2d個詞,經過隱藏層後,輸出的是w(t)。
CBOW模型架構
-
FastText的架構:將整個文字作為特徵去預測文字的類別。
FastText模型架構
5.2.1.5 層次SoftMax
- 對於有大量類別的資料集,FastText使用了一種分層分類器(而非扁平式架構)。不同的類別被整合進樹形結構中(想象下二叉樹而非 list)。在某些文字分類任務中類別很多,計算線性分類器的複雜度高。為了改善執行時間,FastText模型使用了層次 Softmax技巧。層次Softmax技巧建立在哈弗曼編碼的基礎上,對標籤進行編碼,能夠極大地縮小模型預測目標的數量。
-
fastText 也利用了類別不均衡這個事實(一些類別出現次數比其他的更多),通過使用 Huffman 演算法建立用於表徵類別的樹形結構(Huffman樹)。因此,頻繁出現類別的樹形結構的深度要比不頻繁出現類別的樹形結構的深度要小,這也使得進一步的計算效率更高。
Huffman樹結構圖
5.2.1.6 N-gram特徵
- FastText 可以用於文字分類和句子分類。不管是文字分類還是句子分類,我們常用的特徵是詞袋模型。但詞袋模型不能考慮詞之間的順序,因此 FastText還加入了 N-gram 特徵。“我 愛 她” 這句話中的詞袋模型特徵是 “我”,“愛”, “她”。這些特徵和句子 “她 愛 我” 的特徵是一樣的。如果加入 2-gram,第一句話的特徵還有 “我-愛” 和 “愛-她”,這兩句話 “我 愛 她” 和 “她 愛 我” 就能區別開來了。當然啦,為了提高效率,我們需要過濾掉低頻的 N-gram。
- 在 FastText中,每個詞被看做是 n-gram字母串包。為了區分前後綴情況,"<", ">"符號被加到了詞的前後端。除了詞的子串外,詞本身也被包含進了 n-gram字母串包。以 where 為例,n=3 的情況下,其子串分別為<wh, whe, her, ere, re>,以及其本身 。
5.2.1.7 FastText 和 word2vec 對比
- 相似點:
1、模型結構很像,都是採用embedding向量的形式,得到word的隱向量表達。
2、採用很多相似的優化方法,比如使用Hierarchical softmax優化訓練和預測中的打分速度。
- 不同點:
1、模型的輸出層:word2vec的輸出層,對應的是每一個term,計算某term的概率最大;而fasttext的輸出層對應的是分類的label。不過不管輸出層對應的是什麼內容,起對應的vector都不會被保留和使用。
2、模型的輸入層:word2vec的輸出層,是 context window 內的term;而fasttext 對應的整個sentence的內容,包括term,也包括 n-gram的內容。
- 兩者本質的不同,體現在 h-softmax的使用:
1、Word2vec的目的是得到詞向量,該詞向量最終是在輸入層得到,輸出層對應的h-softmax也會生成一系列的向量,但最終都被拋棄,不會使用。
2、fastText則充分利用了h-softmax的分類功能,遍歷分類樹的所有葉節點,找到概率最大的label(一個或者N個)。
5.2.2 Text-CNN文字分類
TextCNN 是利用卷積神經網路對文字進行分類的演算法,它是由 Yoon Kim 在2014年在 “Convolutional Neural Networks for Sentence Classification” 一文中提出的。詳細的原理圖如下。
 Text-CNN文字分類模型原理圖
TextCNN詳細過程:第一層是圖中最左邊的7乘5的句子矩陣,每行是詞向量,維度=5,這個可以類比為影象中的原始畫素點了。然後經過有 filter_size=(2,3,4) 的一維卷積層,每個filter_size 有兩個輸出 channel。第三層是一個1-max pooling層,這樣不同長度句子經過pooling層之後都能變成定長的表示了,最後接一層全連線的 softmax 層,輸出每個類別的概率。
Text-CNN文字分類模型原理圖
TextCNN詳細過程:第一層是圖中最左邊的7乘5的句子矩陣,每行是詞向量,維度=5,這個可以類比為影象中的原始畫素點了。然後經過有 filter_size=(2,3,4) 的一維卷積層,每個filter_size 有兩個輸出 channel。第三層是一個1-max pooling層,這樣不同長度句子經過pooling層之後都能變成定長的表示了,最後接一層全連線的 softmax 層,輸出每個類別的概率。
特徵:這裡的特徵就是詞向量,有靜態(static)和非靜態(non-static)方式。static方式採用比如word2vec預訓練的詞向量,訓練過程不更新詞向量,實質上屬於遷移學習了,特別是資料量比較小的情況下,採用靜態的詞向量往往效果不錯。non-static則是在訓練過程中更新詞向量。推薦的方式是 non-static 中的 fine-tunning方式,它是以預訓練(pre-train)的word2vec向量初始化詞向量,訓練過程中調整詞向量,能加速收斂,當然如果有充足的訓練資料和資源,直接隨機初始化詞向量效果也是可以的。
通道(Channels):影象中可以利用 (R, G, B) 作為不同channel,而文字的輸入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),實踐中也有利用靜態詞向量和fine-tunning詞向量作為不同channel的做法。
一維卷積(conv-1d):影象是二維資料,經過詞向量表達的文字為一維資料,因此在TextCNN卷積用的是一維卷積。一維卷積帶來的問題是需要設計通過不同 filter_size 的 filter 獲取不同寬度的視野。
Pooling層:利用CNN解決文字分類問題的文章還是很多的,比如這篇 A Convolutional Neural Network for Modelling Sentences 最有意思的輸入是在 pooling 改成 (dynamic) k-max pooling,pooling階段保留 k 個最大的資訊,保留了全域性的序列資訊。
5.2.3 TextRNN
模型: Bi-directional RNN(實際使用的是雙向LSTM)從某種意義上可以理解為可以捕獲變長且雙向的的 “n-gram” 資訊。
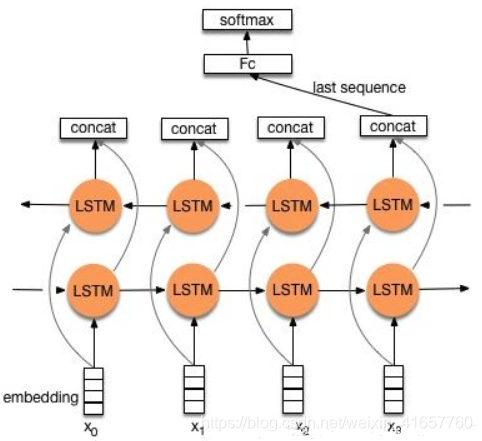
改進: CNN有個最大問題是固定 filter_size 的視野,一方面無法建模更長的序列資訊,另一方面 filter_size 的超參調節也很繁瑣。
5.2.4 TextRNN + Attention
模型結構:
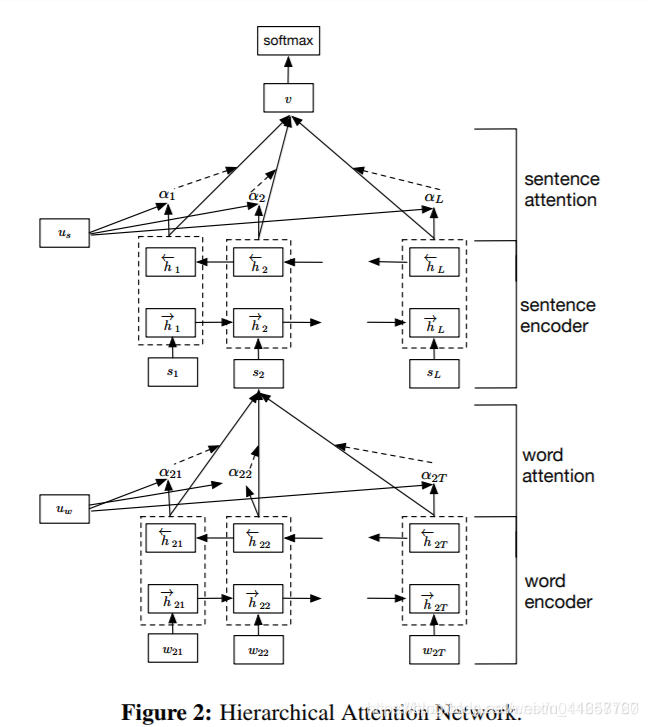
改進:注意力(Attention)機制是自然語言處理領域一個常用的建模長時間記憶機制,能夠很直觀的給出每個詞對結果的貢獻,基本成了Seq2Seq模型的標配了。實際上文字分類從某種意義上也可以理解為一種特殊的Seq2Seq,所以考慮把Attention機制引入近來。
5.2.5 TextRCNN(TextRNN + CNN)
模型結構:
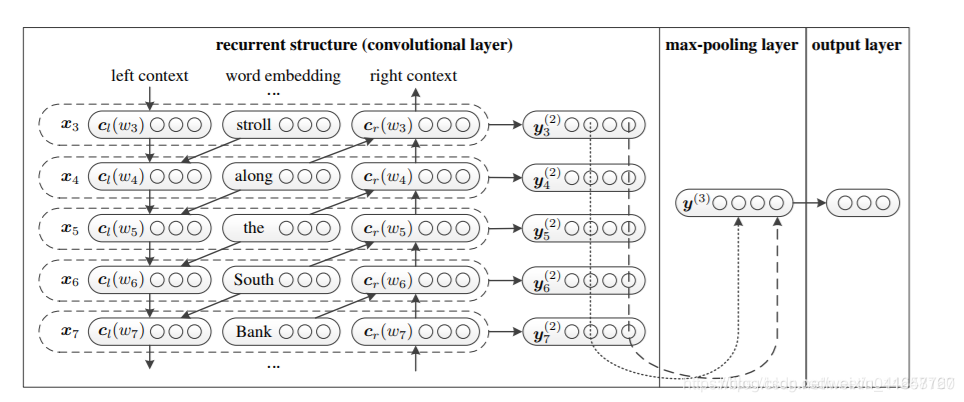
過程:
利用前向和後向RNN得到每個詞的前向和後向上下文的表示:

詞的表示變成詞向量和前向後向上下文向量連線起來的形式:
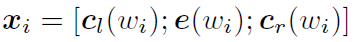
再接跟TextCNN相同卷積層,pooling層即可,唯一不同的是卷積層 filter_size = 1就可以了,不再需要更大 filter_size 獲得更大視野。
參考:
https://blog.csdn.net/xsdjj/article/details/83755511
https://www.jianshu.com/p/56061b8f463a
https://blog.csdn.net/weixin_41657760/article/details/9316