
N-gram統計語言模型(總結)
為了解決引數空間過大的問題,引入了馬爾科夫假設:任意一個詞的出現的概率僅僅與它前面出現的有限的一個或者幾個詞有關。如果一個詞的出現的概率僅於它前面出現的一個詞有關,那麼我們就稱之為bigram model(二元模型)。即
P(S) = P(W1,W2,W3,…,Wn)=P(W1)P(W2|W1)P(W3|W1,W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2|W1)P(W3|W2)…P(Wi)|P(Wi-1)...P(Wn|Wn-1)
如果一個詞的出現僅依賴於它前面出現的兩個詞,那麼我們就稱之為trigram(三元模型)。
在實踐中用的最多的就是bigram和trigram了,而且效果很不錯。高於四元的用的很少,因為訓練它(求出引數)需要更龐大的語料,而且資料稀疏嚴重,時間複雜度高,精度卻提高的不多。當然,也可以假設一個詞的出現由前面N-1個詞決定,對應的模型稍微複雜些,被稱為N元模型。
5.如何估計條件概率問題
條件概率推導在《數學之美》第30頁有詳細講解,在此講述一個簡單的條件概率。 一種簡單的估計方法就是最大似然估計(Maximum Likelihood Estimate)了,即P(Wn|W1,W2,…,Wn-1) = (C(W1,W2,…,Wn)) / (C(W1, W2,…,Wn-1)) 。C(w1,w2,...,wn)即序列w1,w2,...,wn在語料庫中出現的次數。 對於二元模型P(Wi|Wi-1)=C(Wi-1,Wi)/C(Wi-1) (最大似然估計是一種統計方法,它用來求一個樣本集的相關概率密度函式的引數,詳細的講解點選開啟連結)。6.在一個語料庫例子
注:這個語料庫是英文的,而對於漢字語料庫,需要對句子分詞,才能做進一步的自然語言處理。
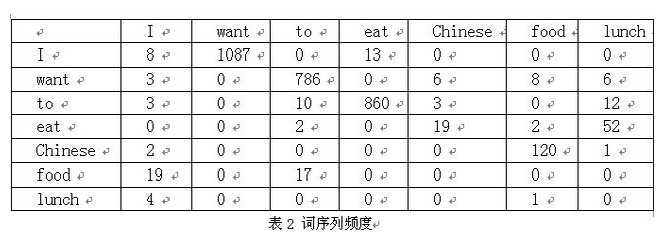
在訓練語料庫中統計序列C(W1 W2…Wn) 出現的次數和C(W1 W2…Wn-1)出現的次數。
下面我們用bigram舉個例子。假設語料庫總詞數為13,748
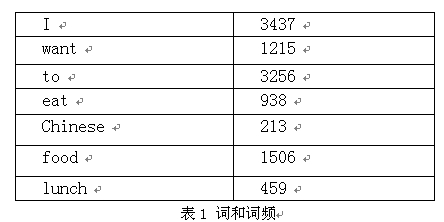
P(I want to eat Chinese food)
=P(I)*P(want|I)*P(to|want)*P(eat|to)*P(Chinese|eat)*P(food|Chinese)
=0.25*1087/3437*786/1215*860/3256*19/938*120/213
=0.000154171
對與 I to Chinese want food eat 的概率遠低於I want to eat Chinese food,所以後者句子結構更合理。
注:P(wang|I)=C(I want)|C(I)=1087/3437
網上很多資料中,表1 詞與詞頻和表2 詞序列頻度是沒有的,所以造成文章表意不清。
對於 1).高階語言模型 2).模型的訓練、零概率問題和平滑方法 3).語料庫的選取等問題,《數學之美》中都有詳細講解,在此不再概述。
相關推薦
N-gram統計語言模型(總結)
為了解決引數空間過大的問題,引入了馬爾科夫假設:任意一個詞的出現的概率僅僅與它前面出現的有限的一個或者幾個詞有關。如果一個詞的出現的概率僅於它前面出現的一個詞有關,那麼我們就稱之為bigram model(二元模型)。即 P(S) = P(W1,W2,W3,…,Wn)=P(W1)P(W2|W1)P
讀《數學之美》第三章 統計語言模型
其它 bigram 利用 理解 googl track 推斷 art google 自然語言從產生開始。逐漸演變為一種基於上下文相關的信息表達和傳遞方式,在計算機處理自然語言時,一個最主要的問題就是為自然語言上下文相關的特性建立數學模型,叫做統計語言模型(Statist
NLP(三)_統計語言模型
完全 概念 精度 馬爾科夫 編輯距離 一定的 角度 等於 nsh 概念 統計語言模型:是描述自然語言內在的規律的數學模型。廣泛應用於各種自然語言處理問題,如語音識別、機器翻譯、分詞、詞性標註,等等。簡單地說,語言模型就是用來計算一個句子的概率的模型 即P(W1,W2,W3.
統計語言模型
mat uri data- add ace msu 信息 狀態 經典 語言模型 p(S) 就是語言模型,即用來計算一個句子 S 概率的模型。 那麽,如何計算呢?最簡單、直接的方法是計數後做除法,即最大似然估計(Maximum Likelihood Estimate,MLE
快速熟悉one-hot,N-gram,word2vec模型
在自然語言處理領域,最開始的學習肯定繞不開one-hot,N-gram,word2vec。下文會快速,簡要的介紹這兩種技術,至於更多的技術細節,可以參考文章最後的參考文獻。在閱讀了本篇文章後,讀者應該能夠達到如下幾個目的: 1.明白one-hot,N-gram,word2v
數學之美 第3章 統計語言模型
語料原理上越多越好,但是要把握好一個度的問題比如機器翻譯中的雙語預料就比較少的,還有就是有很多資料都有噪聲和錯誤的,訓練語料的噪聲高低也會對模型的效果產生一定的影響,因此在訓練資料的時候通常會對訓練資料進行預處理,一般情況下,少量的隨機噪聲清理的成本非常高,通常就不做處理,還有就是有些噪聲處理的太乾淨反而是不
n-gram統計 計算句子概率 SRILM安裝使用
不是非要寫一篇的,是這個網上太少了,而且貌似也沒有其他工具來做這項工作了。因此本文主要寫怎麼使用SRILM統計n-gram,並使用該工具得到的語言模型進行句子概率的計算。當然如果有更好的工具請大家一定要推薦一下。 1、安裝 安裝官方寫的很簡單,遇到問題,又很
Statistical language model 統計語言模型
我們能夠建立語言模型了,一般的我們在訓練集上得到語言模型的引數,在測試集裡面來測試模型的效能,那麼如何去衡量一個語言模型的好壞呢?比較兩個模型A,B好壞,一種外在的評價就是將AB放入具體的任務中,然後分別得到模型的準確率,這種方式當然是最好的方式,但這種方式的缺點是過於耗時,在實際情況中往往需要花費過多時間才
NLP-統計語言模型
衡量 dot 形式 文檔 word2vec -i 其中 方式 rod 概念 統計語言模型是描述自然語言內在規律的數學模型。廣泛應用於各種語言處理問題,如語音識別、機器翻譯、分詞、詞性標註等。統計模型就是用來計算一個句子的概率模型。 $n-gram$
1《數學之美》第3章 統計語言模型
目錄 第3章 統計語言模型 1、用數學的方法描述語言規律 本節提到的概念 本節人物 2、延伸閱讀:統計語言模型的工程訣竅 2.1、高階語言模型
python 自然語言處理 統計語言建模 - (n-gram模型)
N-gram語言模型 考慮一個語音識別系統,假設使用者說了這麼一句話:“I have a gun”,因為發音的相似,該語音識別系統發現如下幾句話都是可能的候選:1、I have a gun. 2、I have a gull. 3、I have a gub. 那麼問題來了,到底哪一個是正確答案呢?
通俗理解N-gram語言模型。(轉)
資料 簡化 事情 自然 自然語言 規模 什麽 發音 給定 N-gram語言模型 考慮一個語音識別系統,假設用戶說了這麽一句話:“I have a gun”,因為發音的相似,該語音識別系統發現如下幾句話都是可能的候選:1、I have a gun. 2、I have a gu
n-gram語言模型及平滑演算法
一、n-gram模型概念 n-gram模型也稱為n-1階馬爾科夫模型,它有一個有限歷史假設:當前詞的出現概率僅僅與前面n-1個詞相關,可以表示為: &n
對語言模型N-gram的理解
今天我們一起來學習一下語言模型N-gram,首先我們來用數學的方法來描述一下語言的規律,這個數學模型就是我們在自然語言處理中的統計語言模型(Statistical Language Model)。在自然語言處理中,所謂的一個句子是否合理通順,就看這個句子的可能性,這裡的可能性就要用概率來
(五)N-gram語言模型的資料處理
一、步驟 資料集說明:一段英文 (1)分詞:把原始的英文分詞,只保留詞之間的順序不變,多個句子也是看出整體進行分詞。 (2)統計詞頻:按照n元進行詞頻統計,比如“I love NLP I enjoy it”當n=2時候,可以劃分為(【I love】,【love NLP】,【NLP
(四)N-gram語言模型與馬爾科夫假設
1、從獨立性假設到聯合概率鏈 樸素貝葉斯中使用的獨立性假設為 P(x1,x2,x3,...,xn)=P(x1)P(x2)P(x3)...P(xn)(1) (1
N-Gram語言模型
一、n-gram是什麼 wikipedia上有關n-gram的定義: n-gram是一種統計語言模型,用來根據前(n-1)個item來預測第n個item。在應用層面,這些item可以是音素(語音識別應用)、字元(輸入法應用)、詞(分詞應用)或鹼基對(基因資訊
自然語言處理中的N-Gram模型詳解
N-Gram(有時也稱為N元模型)是自然語言處理中一個非常重要的概念,通常在NLP中,人們基於一定的語料庫,可以利用N-Gram來預計或者評估一個句子是否合理。另外一方面,N-Gram的另外一個作用是用來評估兩個字串之間的差異程度。這是模糊匹配中常用的一種手段。本文將從此開始
N-gram語言模型與馬爾科夫假設
1、從獨立性假設到聯合概率鏈 樸素貝葉斯中使用的獨立性假設為 P(x1,x2,x3,...,xn)=P(x1)P(x2)P(x3)...P(xn)(1) (1)P(x1,x2,x3,...,xn)=P(x1)P(x2)P(x3)...P(xn) 去掉獨立性假設,有下面這個恆等式,即聯
N-gram語言模型 & Perplexity & 平滑
1. N-gram語言模型 語言模型(Language Model,LM)的一個常見任務,是已知一句話的前面幾個詞,預測下一個是什麼,即對P(wi∣w1i−1)P(w_i|w_1^{i−1})P(wi∣w1i−1)建模 N-gram語言模型,是基於