
Hadoop MapReduce原理【一篇就夠】
之前看英文版的《Hadoop權威指南》沒有看太明白,偶然發現這個博文寫得超級棒,就轉過來以備後面溫習用,望博主見諒!
原文請看=>https://blog.csdn.net/bingduanlbd/article/details/51924398
MapReduce是用於資料處理的一種程式設計模型,簡單但足夠強大,專門為並行處理大資料而設計。
1. 通俗理解MapReduce
MapReduce的處理過程分為兩個步驟:map和reduce。每個階段的輸入輸出都是key-value的形式,key和value的型別可以自行指定。map階段對切分好的資料進行並行處理,處理結果傳輸給reduce,由reduce函式完成最後的彙總。
例如從大量歷史資料中找出往年最高氣溫,NCDC公開了過去每一年的所有氣溫等天氣資料的檢測,每一行記錄一條觀測記錄,格式如下:

為了使用MapReduce找出歷史上每年的最高溫度,我們將行數作為map輸入的key,每一行的文字作為map輸入的value:

上圖中粗體部分分別表示年份和溫度。map函式對每一行記錄進行處理,提取出(年份,溫度)形式的鍵值對,作為map的輸出:
(1950,0)
(1950,22)
(1950,-11)
(1949,111)
(1947,78)- 1
- 2
- 3
- 4
- 5
很明顯,有些資料是髒的,因此map也是進行髒資料處理和過濾的好地方。在map輸出被傳輸到reduce之前,MapReduce框架會對鍵值對進行排序,根據key進行分組,甚至在key相同的一組內先統計出最高氣溫,所以reduce收到的資料格式像這樣:
(1949,[111,78]
(1950,[0,22,-11]- 1
- 2
如果有多個map任務同時執行(通常都是這樣),那麼每個map任務完成後,都會向reduce傳送上面格式的資料,傳送資料的過程叫shuffle。
map的輸出會作為reduce的輸入,reduce收到的是key加上一個列表,然後對這個列表進行處理,天氣資料的例子中,就是找出最大值作為最高氣溫。最後reduce輸出即為每年最高氣溫:
(1949,111)
(1950,22)- 1
- 2
整個MapReduce資料流如下圖:

其中的3個黑圈圈分別為map,shuffle和reduce過程。在Hadoop中,map和reduce的操作可以由多種語言來編寫,例如Java、Python、Ruby等。
在實際的分散式計算中,上述過程由整個叢集協調完成,我們假設現在有5年(2011-2015)的天氣資料,分佈存放在3個檔案中: weather1.txt,weather2.txt,weather3.txt。再假設我們現在有一個3臺機器的叢集,b並且map任務例項數量為3,reduce例項數量2。那麼實際執行MapReduce做作業時,整個流程類似於這樣:
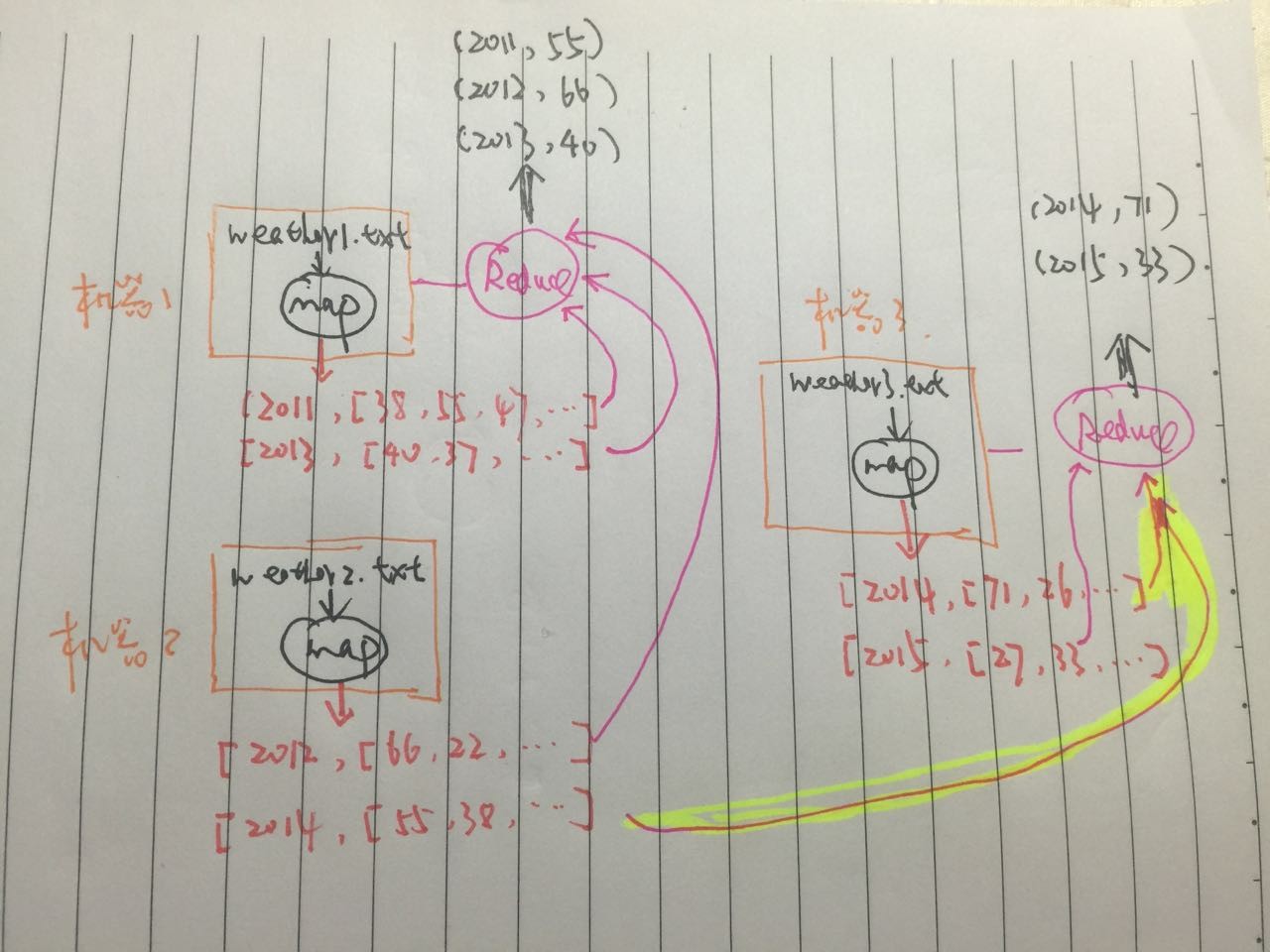
注意到2014年的資料分佈在兩個不同的檔案中,黃色的粗線部分,代表2014年的2個map作業的輸出都統一傳輸到一個reduce,因為他們的key相同(2014)。其實這個過程非常好理解,現實生活中,比如期末考試完了,那考卷由不同的老師批改,完成後如果想知道全年級最高分,那麼可以這麼做:
1)各個老師根據自己批改過的所有試卷分數整理出來(map):
=>(course,[score1,score2,...])- 1
2)各個老師把最高分彙報給系主任(shuffle)
3)系主任統計最高分(reduce)
=>(courese, highest_score)- 1
當然,如果要多門課程混在一起,系主任工作量太大,於是副主任也上(相當於2個reduce),則老師在彙報最高分的時候,相同課程要彙報給同一個人(相同key傳輸給同一個reduce),例如數學英語彙報給主任,政治彙報給副主任。
2. 例項及程式碼實現
life is short , show me the code
MapReduce的概念框架有Google提出,Hadoop提供了經典的開源實現。但是並不是Hadoop特有的,例如在文件型資料庫MongoDB中,可以通過JS來編寫Map-Reduce,對資料庫中的資料進行處理。我們這裡以Hadoop為例說明。
資料準備
首先將本地的檔案上傳到HDFS:
hadoop fs -copyFromLocal /home/data/hadoop_book_input/ hdfs://master:9000/input- 1
可以查管理介面檢視是否成功上傳:
檢視一下資料內容:
hadoop fs -text hdfs://master:9000/input/ncdc/sample.txt- 1

編寫Java程式碼
首先實現Mapper類,Mapper在新版本Hadoop中改變為類(舊版為介面)定義如下:
// 支援泛型,泛型定義map輸入輸出的鍵值型別
public class Mapper <KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public Mapper() {
// map任務開始的時候呼叫一次,用於做準備工作
protected void setup(Context context) throws IOException, InterruptedException {
// 空實現
}
// map邏輯 預設直接將輸入進行型別轉換後輸出
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
// 任務結束後呼叫一次,清理工作,與setup對應
protected void cleanup(Context context
) throws IOException, InterruptedException {
// 空實現
}
// map的實際執行過程就是呼叫run方法,一般用於高階實現,更精細地控制 任務的執行過程, 一般情況不需要覆蓋這個方法
public void run(Context context) throws IOException, InterruptedException {
// 準備工作
setup(context);
try {
// 遍歷分配給該任務的資料,迴圈呼叫map
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
// 清理工作
cleanup(context);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
實現中我們只覆蓋map方法,其他保留不變。具體實現如下:
public class MaxTemperatureMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
// 9999代表資料丟失
private static final int MISSING = 9999;
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 行作為輸入值 key在這裡暫時不需要使用
String line = value.toString();
// 提取年份
String year = line.substring(15, 19);
// 提取氣溫
int airTemperature = parseTemperature( line );
String quality = line.substring(92, 93);
// 過濾髒資料
boolean isRecordClean = airTemperature != MISSING && quality.matches("[01459]");
if ( isRecordClean ) {
// 輸出(年份,溫度)對
context.write(new Text(year), new IntWritable(airTemperature));
}
}
private int parseTemperature(String line){
int airTemperature;
if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
return airTemperature;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
接著實現Reducer,看看定義:
public class Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
// Reducer上下文類定義
public abstract class Context
implements ReduceContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
}
// 初始化 在Reduce任務開始時呼叫一次
protected void setup(Context context
) throws IOException, InterruptedException {
// 空實現
}
/**
* map shuffle過來的資料中,每一個key呼叫一次這個方法
*/
@SuppressWarnings("unchecked")
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context
) throws IOException, InterruptedException {
// 預設將所有的值一一輸出
for(VALUEIN value: values) {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
protected void cleanup(Context context
) throws IOException, InterruptedException {
// 空實現 收尾工作
}
// Reducer的執行邏輯 供更高階的定製
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
// 遍歷輸入key
while (context.nextKey()) {
reduce(context.getCurrentKey(), context.getValues(), context);
// 一個key處理完要轉向下一個key時,重置值遍歷器
Iterator<VALUEIN> iter = context.getValues().iterator();
if(iter instanceof ReduceContext.ValueIterator) {
((ReduceContext.ValueIterator<VALUEIN>)iter).resetBackupStore();
}
}
} finally {
cleanup(context);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
我們的Reducer實現主要是找出最高氣溫:
public class MaxTemperatureReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int maxValue = findMax( values );
context.write(key, new IntWritable(maxValue));
}
private static int findMax(Iterable<IntWritable> values){
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
return maxValue;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
Mapper和Reducer實現後,需要一個入口提交作業到Hadoop叢集,在新版本中,使用YARN框架來執行MapReduce作業。作業配置如下:
public class MaxTemperature {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperature <input path> <output path>");
System.exit(-1);
}
// 設定jar包及作業名稱
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max temperature");
// 輸入輸出路徑
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 設定Mapper和Reducer實現
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
// 設定輸出格式
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 等待作業完成後退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
輸入輸出路徑使用FileInputFormat/FileOutputFormat的靜態方法來設定,在執行作業之前,輸出目錄不能存在,這是為了避免覆蓋資料導致資料丟失。執行之前如果檢測到目錄已經存在,作業將無法執行。OK,把專案打包,如果使用Eclipse,使用Export功能。如果使用Maven開發,則直接執行package命令。假設我們最後的jar包為max-temp.jar.把jar包上傳到你的叢集機器上,或者放在安裝了Hadoop的客戶端機器上,這裡假設jar包放在/opt/job目錄下。
執行
首先把作業jar包放到CLASSPATH:
cd /opt/job
export HADOOP_CLASSPATH=max-temp.jar- 1
- 2
執行:
hadoop MaxTemperature /input/ncdc/sample.txt /output- 1
hadoop會自動把HADOOP_CLASSPAT設定的路徑加入到CLASSPATH中,同時把HADOOP相關的依賴包也加入CLASSPATH,然後啟動一個JVM執行MaxTemperature這個帶有main方法的類。
結果如下:
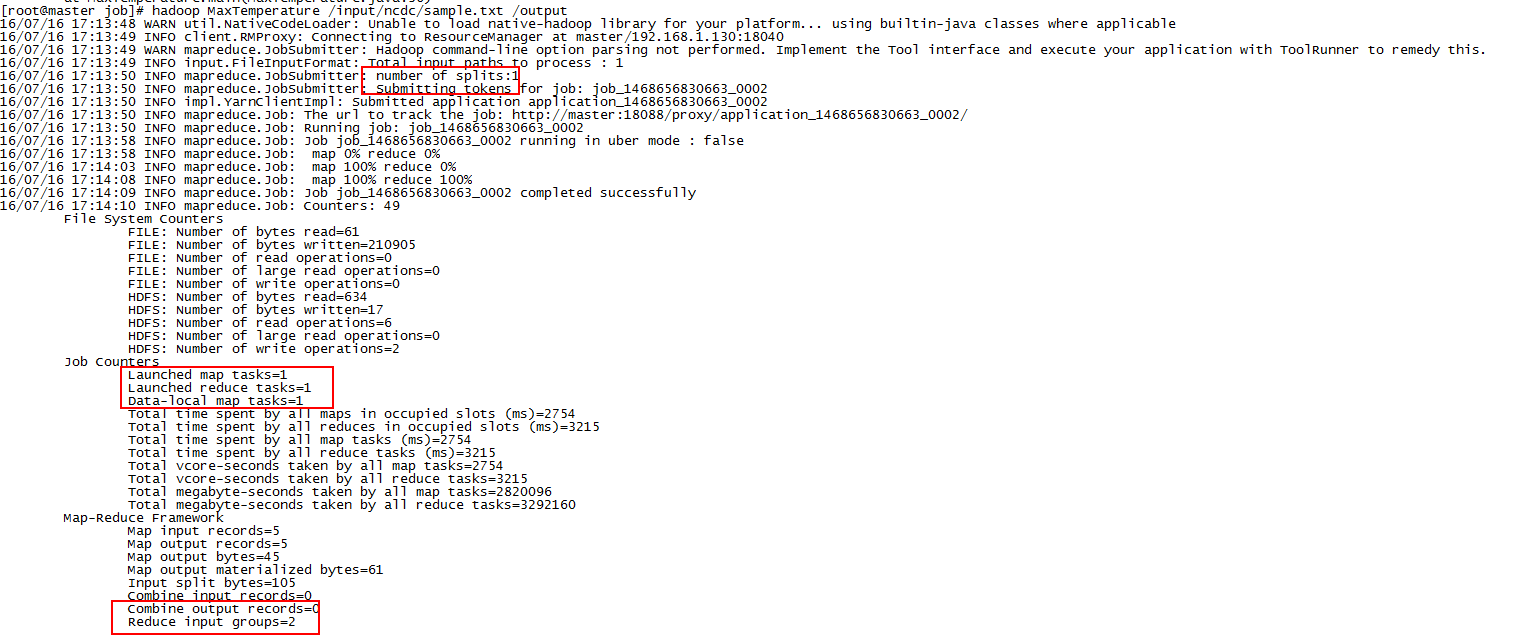
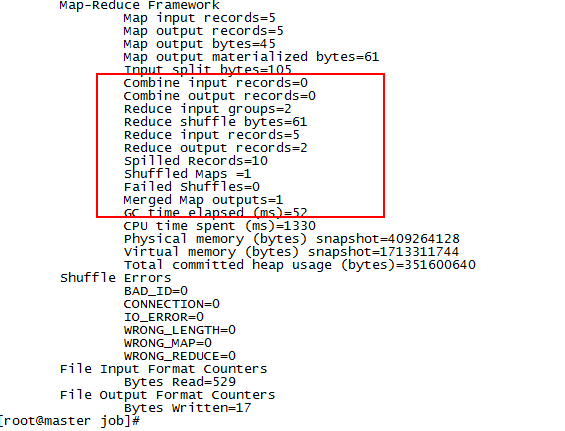
日誌中可以看到作業的一些執行情況,例如map任務數量,reduce任務數量,以及輸入輸出的記錄數,可以看到跟實際情況完全吻合。
我們看一下輸出目錄/output:
hadoop fs -ls /output- 1

可以看到該目錄下有個成功標識檔案_SUCCESS和結果輸出檔案part-r-0000,每個reducer會輸出一個檔案。檢視一下這個輸出檔案的內容:
hadoop fs -text hdfs://master:9000/output/part-r-00000- 1
如上圖所示,我們成功得到了1949和1950年的最高溫度,無需管結果是否合理,只要按照我們想要的邏輯執行即可。
YARN管理介面也可以看到該作業的情況:
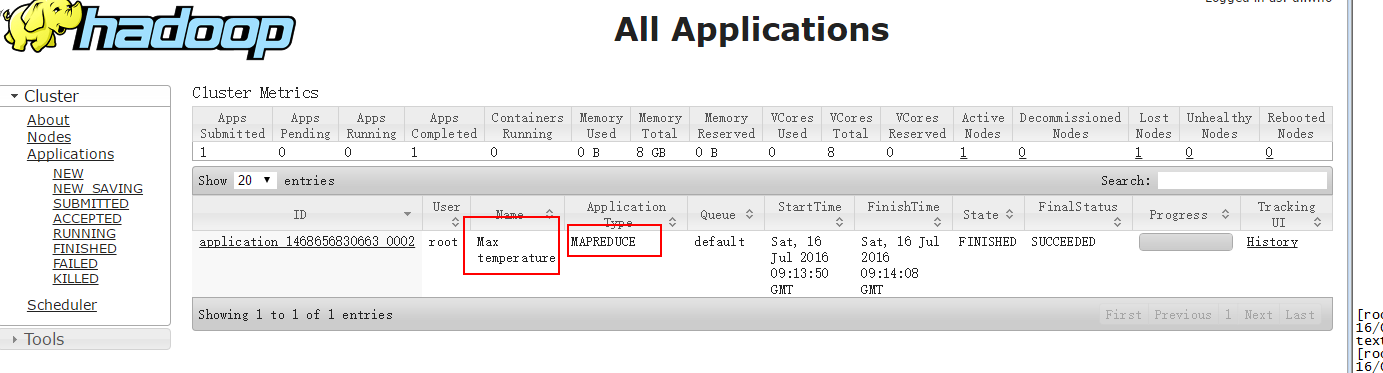
3. 進一步理解MapReduce
一個MapReduce作業通常包括輸入資料、MapReduce程式以及一些配置資訊。Hadoop把作業分解為task執行,task分為map任務和reduce任務,在新版本的Hadoop中,這些Task通過資源管理框架進行排程,如果任務失敗,MapReduce應用框架會重新執行任務。
作業的輸入被劃為固定大小的分片,叫input splits,簡稱splits。然後為每一個split分塊建立一個map任務,map任務對每一條記錄執行使用者定義的map函式。劃分為split之後,不同配置的機器就可以根據自己的資源及運算能力執行適當的任務,即使是相同配置的機器,最後執行的任務數也往往不等,這樣能有效利用整個叢集的計算能力。但是split也不已太多,否則會耗費很多時間在建立map任務上,通常而言,按叢集Block大小(預設為128M)來劃分split是合理的。
Hadoop會把map任務執行在裡資料最近的節點上,最好的情況是直接在資料(split)所在的節點上執行map任務,這樣不需要佔用頻寬,這一優化叫做資料本地優化(data locality optimization)。下圖的map選址方案從最優到最次為a,b,c:
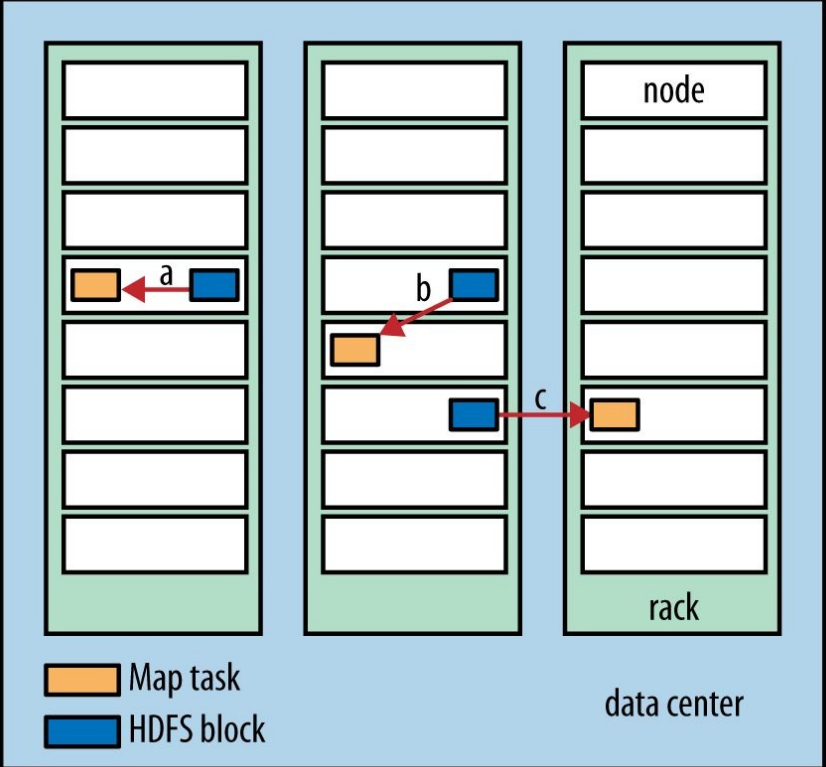
關於Hadoop如何衡量兩個叢集節點的距離,參考我的另一批部落格 深入理解HDFS:Hadoop分散式檔案系統。但是節點距離不是分配task考慮的唯一因素,還會考慮節點當前負載等因素。
Reduce任務通常無法利用本地資料的優化,大多數情況下,reduce的輸入都來自叢集的其他節點。reduce針對每一個key執行reduce函式之後,輸出結果通常儲存在HDFS中,並且儲存一定的副本數,第一個副本存在執行reduce任務的本地機器,其他副本根據HDFS寫入的管道分別寫入節點,關於更多HDFS的資料寫入流程,參考這裡。
下圖是一個單reduce的資料流示例:
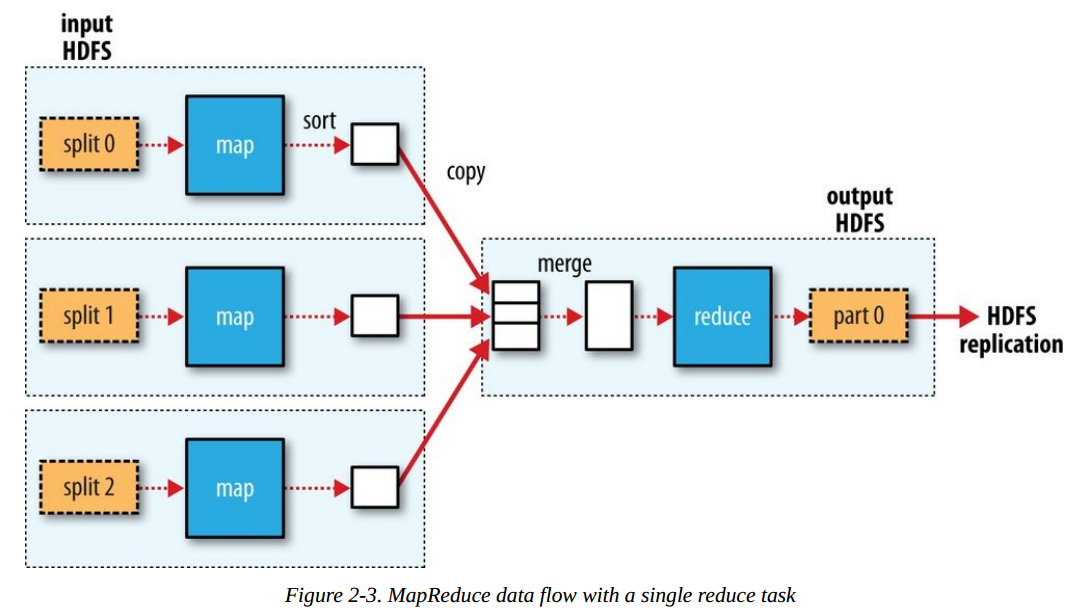
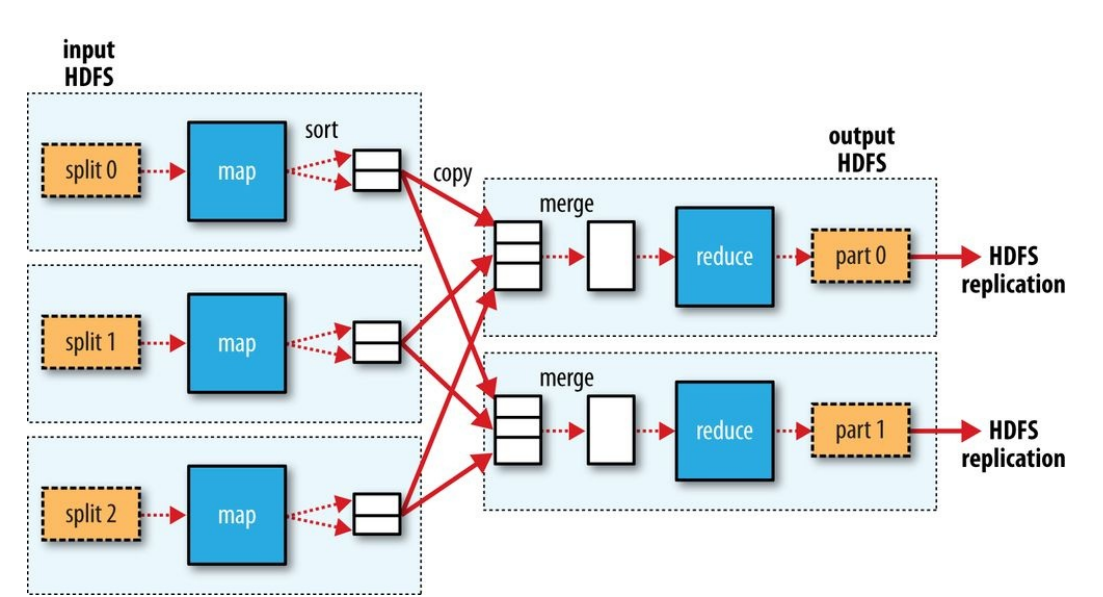
如果有多個reduce任務,那麼map任務的輸出到底該傳輸到哪一個reduce任務呢?決定某個key的資料(key,[value1, value2,...])該傳送給那個reduce的過程叫partition。預設情況下,MapReduce使用key的雜湊函式進行分桶,這通常工作的很好。如果需要自行指定分割槽函式,可以自己實現一個Partitioner並配置到作業中。key相同的map任務輸出一定會發送到同一個reduce任務。map任務的輸出資料傳輸到reduce任務所在節點的過程,叫做shuffle。下面是一個更通用的MapReduce資料流圖:
當然,有些作業中我們可能根本不需要有reduce任務,所有工作在map任務並行執行完之後就完畢了,例如Hadoop提供的並行複製工作distcp,其內部實現就是採用一個只有Mapper,沒有Reducer的MapReduce作業,在map完成檔案複製之後作業就完成了,如下圖所示:

在上面計算最高天氣的例子中,每個map將每一條記錄所產生的(年份,溫度)記錄都shuffle到reduce節點,當資料量較大時,將佔用很多頻寬,耗費很長時間。事實上,可以在map任務所在的節點上做更多工作。map任務執行完之後,可以把所有結果按年份分組,並統計出每一年的最高溫度(類似於sql中的 select max(temperature) from table group by year),這個最高溫度是區域性的,只在本任務重產生的資料做比較。做完區域性統計之後,將結果傳送給reduce做最終的彙總,找出 全域性最高溫度。過程示意圖如下:
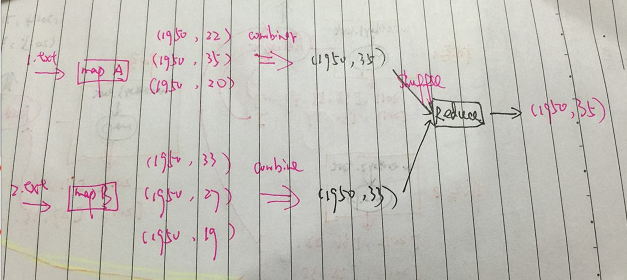
這麼做之所以符合邏輯,是基於以下的事實:
max(0,20,10,25,15)=max(max(0,20,10) , max(25,15))- 1
符合上述性質的函式稱為是commutative和associative,有時候也成為是distributive。如果是計算平均溫度,則不能使用這一的方式。
上述的區域性計算在Hadoop中使用Combiner來表示。為了在作業中使用Combiner,我們需要明確指定,在前面的例子中,可以直接使用Reducer作為Combiner,因為兩者邏輯是一樣的:
// 設定Mapper和Reducer實現
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);- 1
- 2
- 3
- 4
4. Hadoop Streaming
Hadoop完全允許我們使用Java以外的語言來編寫map和reduce函式。Hadoop Streaming使用Unix標準流作為Hadoop和其他應用程式的介面。資料流的大致示意圖如下:
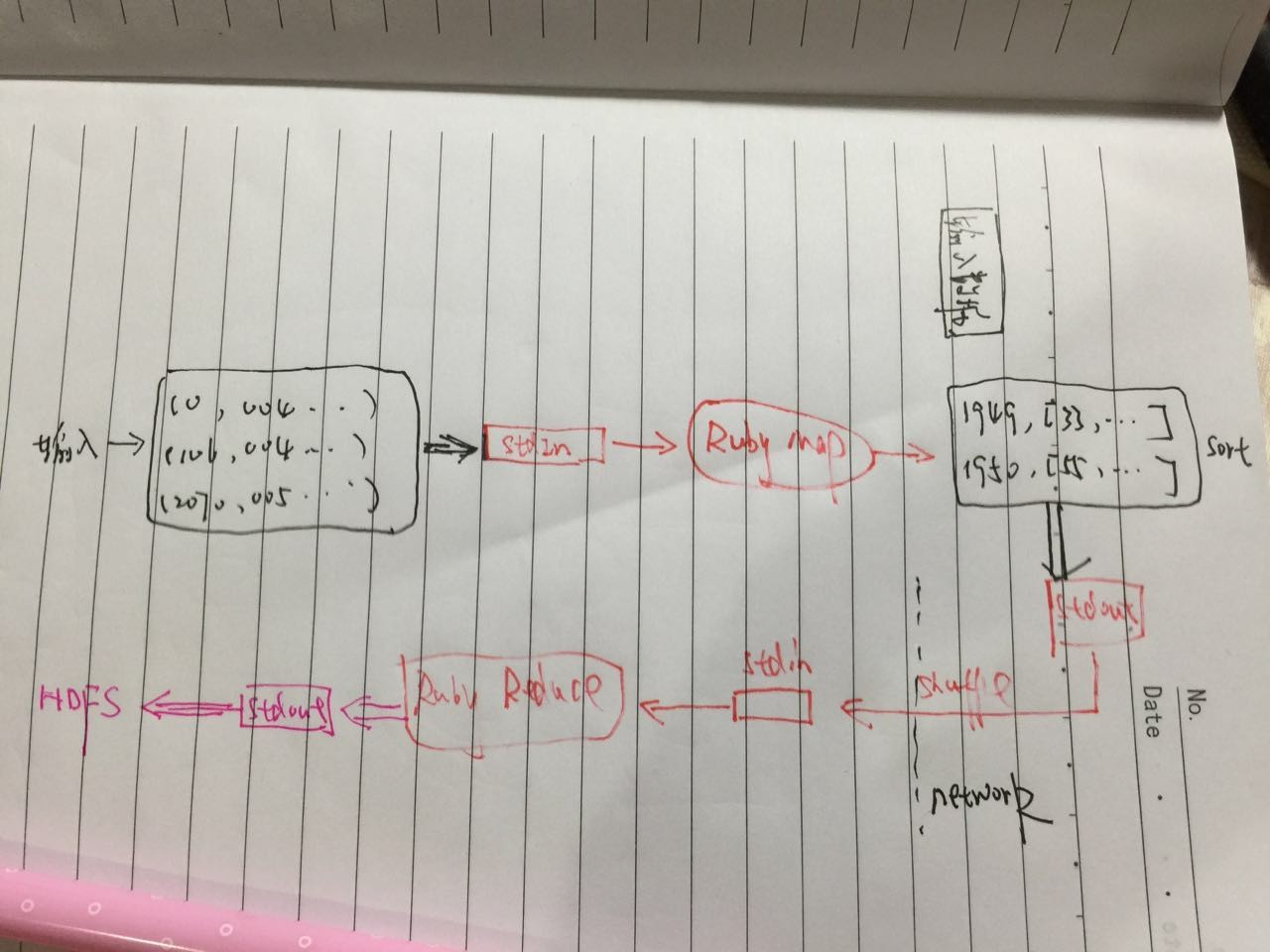
整個資料在Hadoop MapReduce與Ruby應用、標準輸入輸出之間流轉,因此叫Streaming。我們繼續使用前面氣溫的例子來說明,先使用ruby來編寫map和reduce,然後使用unix的管道來模擬整個過程,最後遷移到Hadoop上執行。
Ruby版本的map函式從標準流中讀取資料,運算後將結果輸出到標準輸出流:
#!/usr/bin/ruby
STDIN.each_line do |line|
val = line
year , temp , q = val[15,4],val[87,5],val[92,1]
puts "#{year}\t#{temp}" if (temp != "+9999" && q =~/[01459]/)
end- 1
- 2
- 3
- 4
- 5
- 6
邏輯與Java版本完全一樣,STDIN是ruby的標準輸入,each_line針對每一行進行操作,邏輯封裝在do和end之間。puts是ruby標準輸出函式,列印tab分割的記錄到標準輸出流。
因為這個指令碼與標準輸入輸出互動,所以很容易結合linux的管道來測試:
cat input/ncdc/sample.txt | ruby max_temp_map.rb- 1

一樣用ruby指令碼來完成reduce的功能:
last_key , max_val = nil , -1000000
STDIN.each_line do |line|
key , val = line.split("\t")
if last_key && last_key != key
puts "#{last_key}\t#{max_val}"
last_key , max_val = key , val.to_i
else
last_key , max_val = key,[max_val , val.to_i].max
end
end
# 處理最後一個key的輸出
put "#{last_key}\t#{max_val}" if last_key- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
map處理完之後,同一個key的一組鍵值對中,value是排序的,所以當前讀到的key如果不同於上一個key,表示這個key的所有值都處理完了(前文提到會在切換key之前reset輸入)。我們使用sort命令來替代MapReduce中的排序過程,把map的標準輸出作為sort的輸入,sort通過管道連線到map:
cat /home/data/hadoop_book_input/ncdc/sample.txt| ruby max_temp_map.rb | sort | ruby max_temp_reduce.rb- 1
輸出結果如下圖,與前文完全一致。

很好,我們在Hadoop上執行這個作業。非Java語言的MapReduce作業,需要使用Hadoop Streaming來執行。Hadoop Streaming會負責作業的Task分解,把輸入資料作為標準輸入流傳遞給Ruby寫的map指令碼,並接受來自map指令碼的標準輸出,排序後shuffle到reduce節點上,並以標準輸入傳遞給reduce,最後把reduce的標準輸出儲存到HDFS檔案中。
我們使用hadoop jar命令,同時指定輸入輸出目錄,指令碼位置等。
hadoop jar /home/hadoop-2.6.0/share/hadoop/tools/lib/hadoop-streaming-2.6.0.jar -files max_temp_map.rb,max_temp_reduce.rb -input /input/ncdc/sample.txt -output /output/max-tem-ruby -mapper max_temp_map.rb -reducer max_temp_reduce.rb- 1
-file引數把這些檔案上傳到叢集中。注意map和reduce指令碼需要在CLASSPATH下,我是在當前目錄下執行的,預設加入到類路徑中。另外請確保叢集中的所有機器都安裝了ruby,否則可能出現類似subprocess failed with code 127。這裡的輸出檔案是/outp/max-tem-ruby,MapReduce不允許多個作業輸出到同一個目錄。
檢視輸出檔案,與Java版本完全一致。OK,我們設定combiner,然後在大的資料集上感受一下:
hadoop jar /home/hadoop-2.6.0/share/hadoop/tools/lib/hadoop-streaming-2.6.0.jar -files max_temp_map.rb,max_temp_reduce.rb -input /input/ncdc/all -output /output/max-tem-all -mapper max_temp_map.rb -combiner x_temp_reduce.rb -reducer max_temp_reduce.rb- 1
計算結果:

map和reduce也一樣可以用Python來實現,用與Ruby一樣的方式來執行,這裡不多介紹。
參考
本文主要內容來自《Hadoop權威指南》,感謝作者的優秀書籍。