
NLP課程:詞向量到Word2Vec理論基礎及相關程式碼
阿新 • • 發佈:2018-12-23
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。
詞向量:
NLP的發展主要有兩個方向:
- 傳統方向:基於規則
- 現代方向:基於統計機器學習:如HMM(隱馬爾可夫)、CRF(條件隨機場)、SVM、LDA(主題模型)、CNN..
詞向量需要保證空間中分佈的相似性:

離散表示進階:
- One-hot表示:很容易理解,即在有詞的地方填充1,其他地方填充0,作為一個長向量。

- Bag of Words(詞袋模型)表示:是在one-hot基礎上進行優化,用單詞出現的次數來表示文件。文件的向量表示可以直接將各詞的詞向量表示加和:
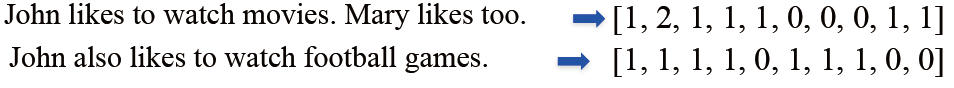
- TF-IDF是進一步優化了考慮單詞在整體文件中的頻次:

- Bi-gram和N-gram表示:前面的兩種方法都只是表示了單個單詞的關係,沒有上下文順序的關係,因此發展出了N-gram和Bi-gram(如果一個詞的出現僅依賴於它前面出現的一個詞,那麼我們就稱之為 Bi-gram:參考一),一句話 (詞組合) 出現的概率為:
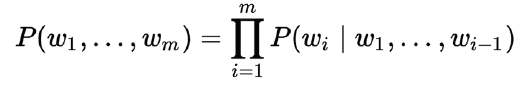

這樣表示的優點是:考慮的了詞順序,但是缺點是詞表膨脹,導致計算量增大。
- 離散表示的問題:
①無法衡量詞向量之間的關係;
②詞表維度隨著語料庫增長膨脹;
③n-gram詞序列隨語料庫膨脹更快;
④資料稀疏問題。
分散式表示 (Distributed representation)

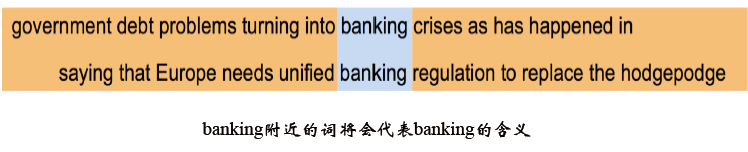
- 共現矩陣(Cocurrence matrix):Word - Document 的共現矩陣主要用於發現主題(topic),用於主題模型,如LSA (Latent Semantic Analysis), 局域窗中的Word - Word 共現矩陣可以挖掘語法和語義資訊:


將共現矩陣行(列)作為詞向量存在問題:
- 向量維數隨著詞典大小線性增長;
- 儲存整個詞典的空間消耗非常大;
- 一些模型如文字分類模型會面臨稀疏性問題;
- 模型會欠穩定
SVD降維:受上面存在的問題,進行改進構造低維稠密向量 (25~1000維)作為詞的分散式表示,想到用SVD對共現矩陣向量做降維 :

但是也同樣存在問題:
- 計算量隨語料庫和詞典增長膨脹太快,對X(n,n)維的矩陣,計算量O(n^3)。 而對大型的語料庫,n~400k,語料庫大小1~60B token ;
- 難以為詞典中新加入的詞分配詞向量;
- 與其他深度學習模型框架差異大。
Word2vec:
上面敘述了很多詞向量表示方法,現在終於進入正題。
NNLM (Neural Network Language model) :這個模型可以說是word2vec的前身,它直接從語言模型出發,將模型最優化過程轉化為詞向量表示的過程 ,目標函式為:
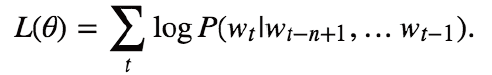
- 改進點:
①使用了非對稱的前向窗函式,窗長度為n-1;
②滑動視窗遍歷整個語料庫求和,計算量正比於語料庫大小 ;
③概率P滿足歸一化條件,這樣不同位置t處的概率才能相加,即:
- 結構:

其中:
①(N-1)個前向詞:one-hot表示;
②採用線性對映將one-hot表示投影到稠密D維表示 ;
③輸出層:Softmax;
④各層權重最優化:BP+SGD ;
⑤詞典維數V,稠密詞向量表示維數D 。
計算複雜度:每個訓練樣本的計算複雜度為:N * D + N * D * H + H * V(ps:一個簡單模型在大資料量上的表現比複雜模型在少資料量上的表現會好 ):

CBOW(連續詞袋):是word2vec模型的一種,從單詞袋上下文預測目標單詞,結構如下:

- 特點:①無隱層;②使用雙向上下文視窗;③輸入層直接使用低維稠密表示;④投影層簡化為求和(平均)。
- 目標函式:

- 概率分佈計算方法:
(1)層次softmax:①使用Huffman Tree 來編碼輸出層的詞典 ;②只需要計算路徑上所有非葉子節點詞向量的貢獻即可 ;③計算量降為樹的深度 V => log_2(V) :
那麼:
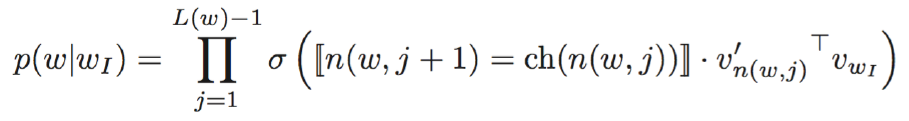 其中:
其中:
①Sigmoid函式:
②n(w,j):Huffman數內部第j層的節點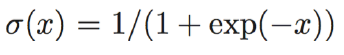
③ch(n(w,j)):n節點的child節點
④[[n(w,j+1)=ch(n(w,j)]] 是選擇函式,表明只選擇從根節點到目標葉節點路徑上的內部節點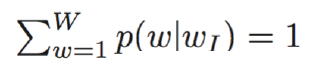
(2)負例取樣:P(w|context(w)): 一個正樣本,V-1個負樣本,對負樣本做取樣:
其中:
是context(w)中詞向量的和 ,
是詞u對應的一個(輔助)向量 ,NEG(w)是w的負樣本取樣子集
損失函式:對語料庫中所有詞w求和 :
詞典中的每一個詞對應一條線段,所有片語成了[0,1]間的剖分: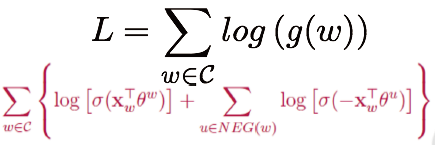
實際使用中取counter(w)^(3/4)效果最好,l1,l2,.....,ln組成了[0, 1]間的剖分: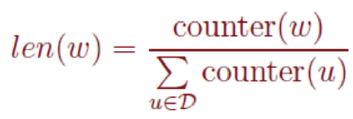
將[0, 1]劃分為M=10^8等分,每次隨機生成一個[1, M-1]間的整數,看落在那個詞對應的剖分上。
Skip-grams (SG):這是word2vec模型的另一種,是預測給定目標的上下文單詞:

- 結構如下:

- 特點與CBOW類似:
①無隱層 ;②投影層也可省略;③每個詞向量作為log-linear模型的輸入 ; - 目標函式:

- 概率密度由softmax計算:
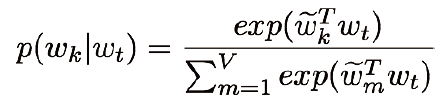
Word2Vec: 存在的問題:
- 對每個local context window單獨訓練,沒有利用包含在global co-currence矩陣中的統計資訊;
- 對多義詞無法很好的表示和處理,因為使用了唯一的詞向量;
總結:
離散表示:
- One-hot representation, Bag Of Words Unigram語言模型
- N-gram詞向量表示和語言模型
- Co-currence矩陣的行(列)向量作為詞向量
分散式連續表示:
- Co-currence矩陣的SVD降維的低維詞向量表示
- Word2Vec: Continuous Bag of Words Model
- Word2Vec: Skip-Gram Model

更多案例程式碼:歡迎關注我的github
To be continue......