
Kafka事務簡介
說明:本文翻譯Confluent官網,原文地址:
在之前的部落格文章(見尾部連結)中,我們介紹了ApacheKafka的exactly once語義,介紹了各種訊息傳輸語義,producer的冪等特性,事和Kafka Stream的exactly once處理語義。現在我們將從上篇文章結尾的地方開始,深入探討Apache Kafka的事務。本文件的目標是使讀者熟悉Apache Kafka中有效使用事務API所需要的主要概念。
我們將討論事務API設計的主要用例,Kafka的事務語義,JavaClient事務API細節,實現方面一些有趣的地方,最後,我們會討論API使用方面的一些重要因素。
這篇文章並不打算成為事務處理細節方面的教程,我們也不會深入探討設計方面的細節;相反,我們給希望更加深入的讀者JavaDoc或者設計文件的連結。
我們希望讀者在閱讀這篇文章之前,能夠熟悉Kafka的基本概念,比如Topics,partitions, 日誌偏移量和borker的覺得,以及包含kafka客戶端的應用程式例子,熟悉Kafka的Java客戶端也會所有幫助。
1. 為什麼要支援事務
我們在Kafka中設計事務的目的主要是為了滿足“讀取-處理-寫入”這種模式的應用程式。這種模式下資料的讀寫是非同步的,比如Kafka的Topics。這種應用程式更廣泛的被稱之為流處理應用程式。
第一代流處理應用程式可以容忍不準確的資料處理,比如,檢視網頁點選數量的應用程式,能夠允許計數器存在一些錯誤(多算或者漏算)。
然而,隨著這些應用的普及,對於流處理計算語義有更多要求的需求也在增多。比如,一些金融機構部使用流處理應用來處理使用者賬戶的借貸方,這種情況下,處理中的錯誤是不能容忍的,我們需要每一條訊息都被處理一次,沒有任何例外。
更正式的說,如果流處理應用程式消費訊息A併產生訊息B,使得B=F(A),則exactlyonce則意味著僅當B成功時才認為A被消耗,反之亦然。
當在Kafka的producer和consumer的配置屬性中使用at-least-once傳入語義的時候,一個流處理應用程式能夠處理下面的場景:
1. 由於內部重試,producer.send()方法使得訊息B可能被重複寫入。這將由Procedure的冪等特性解決,不是這篇文章其餘部分的重點。
2. 我們可能會對訊息A進行重新處理,這會導致重複的訊息B被寫入,違背了exactly once的處理語義,如果流處理應用程式在B寫入成功但是在A被成功標記之前崩潰,則可能會被重新處理,因此,當它恢復時,他將在此消費A並再次寫入B,導致重複。
3. 最後,在分散式環境中,應用程式會崩潰或者更糟,一旦和系統其它部分連線丟失,通常情況下,新的例項會自動啟動以取代丟失例項。通過這個過程,可能會有多個例項處理相同的輸入topic並寫入相同的輸出topic,從而導致重複的輸出並違背exactly once的處理語義,這個我們稱之為“殭屍例項”的問題。
我們在Kafka中設計了事務API來解決第二個和第三個問題,事務能夠保證這些“讀取-處理-寫入”操作成為一個與那字操作並且在一個週期中保證精確處理,滿足exactly once處理語義。
2. 事務語義
2.1. 多分割槽原子寫入
事務能夠保證Kafka topic下每個分割槽的原子寫入。事務中所有的訊息都將被成功寫入或者丟棄。例如,處理過程中發生了異常並導致事務終止,這種情況下,事務中的訊息都不會被Consumer讀取。現在我們來看下Kafka是如何實現原子的“讀取-處理-寫入”過程的。
首先,我們來考慮一下原子“讀取-處理-寫入”週期是什麼意思。簡而言之,這意味著如果某個應用程式在某個topic tp0的偏移量X處讀取到了訊息A,並且在對訊息A進行了一些處理(如B = F(A))之後將訊息B寫入topic tp1,則只有當訊息A和B被認為被成功地消費並一起釋出,或者完全不釋出時,整個讀取過程寫入操作是原子的。
現在,只有當訊息A的偏移量X被標記為消耗時,訊息A才被認為是從topic tp0消耗的,消費到的資料偏移量(record offset)將被標記為提交偏移量(Committing offset)。在Kafka中,我們通過寫入一個名為offsets topic的內部Kafka topic來記錄offset commit。訊息僅在其offset被提交給offsets topic時才被認為成功消費。
由於offset commit只是對Kafkatopic的另一次寫入,並且由於訊息僅在提交偏移量時被視為成功消費,所以跨多個主題和分割槽的原子寫入也啟用原子“讀取-處理-寫入”迴圈:提交偏移量X到offset topic和訊息B到tp1的寫入將是單個事務的一部分,所以整個步驟都是原子的。
2.2. 粉碎“殭屍例項”
我們通過為每個事務Producer分配一個稱為transactional.id的唯一識別符號來解決殭屍例項的問題。在程序重新啟動時能夠識別相同的Producer例項。
API要求事務性Producer的第一個操作應該是在Kafka叢集中顯示註冊transactional.id。 當註冊的時候,Kafka broker用給定的transactional.id檢查開啟的事務並且完成處理。 Kafka也增加了一個與transactional.id相關的epoch。Epoch儲存每個transactional.id內部元資料。
一旦這個epoch被觸發,任何具有相同的transactional.id和更舊的epoch的Producer被視為殭屍,並被圍起來, Kafka會拒絕來自這些Procedure的後續事務性寫入。
2.3. 讀事務訊息
現在,讓我們把注意力轉向資料讀取中的事務一致性。
Kafka Consumer只有在事務實際提交時才會將事務訊息傳遞給應用程式。也就是說,Consumer不會提交作為整個事務一部分的訊息,也不會提交屬於中止事務的訊息。
值得注意的是,上述保證不足以保證整個訊息讀取的原子性,當使用Kafka consumer來消費來自topic的訊息時,應用程式將不知道這些訊息是否被寫為事務的一部分,因此他們不知道事務何時開始或結束;此外,給定的Consumer不能保證訂閱屬於事務一部分的所有Partition,並且無法發現這一點,最終難以保證作為事務中的所有訊息被單個Consumer處理。
簡而言之:Kafka保證Consumer最終只能提供非事務性訊息或提交事務性訊息。它將保留來自未完成事務的訊息,並過濾掉已中止事務的訊息。
3. 事務處理Java API
事務功能主要是一個伺服器端和協議級功能,任何支援它的客戶端庫都可以使用它。 一個Java編寫的使用Kafka事務處理API的“讀取-處理-寫入”應用程式示例:
KafkaProducer producer = createKafkaProducer(
“bootstrap.servers”, “localhost:9092”,
“transactional.id”, “my-transactional-id”);
producer.initTransactions();
KafkaConsumer consumer = createKafkaConsumer(
“bootstrap.servers”, “localhost:9092”,
“group.id”, “my-group-id”,
"isolation.level", "read_committed");
consumer.subscribe(singleton(“inputTopic”));
while (true) {
ConsumerRecords records = consumer.poll(Long.MAX_VALUE);
producer.beginTransaction();
for (ConsumerRecord record : records)
producer.send(producerRecord(“outputTopic”, record));
producer.sendOffsetsToTransaction(currentOffsets(consumer), group);
producer.commitTransaction();
}
第7-10行指定KafkaConsumer只應讀取非事務性訊息,或從其輸入主題中提交事務性訊息。流處理應用程式通常在多個讀取處理寫入階段處理其資料,每個階段使用前一階段的輸出作為其輸入。通過指定read_committed模式,我們可以在所有階段完成一次處理。
第1-5行通過指定transactional.id配置並將其註冊到initTransactionsAPI來設定Procedure。在producer.initTransactions()返回之後,由具有相同的transactional.id的Producer的另一個例項啟動的任何事務將被關閉和隔離。
第14-21行顯示了“讀取-處理-寫入”迴圈的核心:讀取一部分記錄,啟動事務,處理讀取的記錄,將處理的結果寫入輸出topic,將消耗的偏移量傳送到offset topic,最後提交事務。有了上面提到的保證,我們就知道offset和輸出記錄將作為一個原子單位。
4. 事務工作原理
在本節中,我們將簡要介紹上面介紹的事務API引入的新元件和新資料流。更詳細的資訊,你可以閱讀原始設計文件,或觀看介紹Kafka MeetUp的Sliders。
下面示例的目標是在除錯使用了事務的應用程式時,如何對事務進行優化以獲得更好的效能。
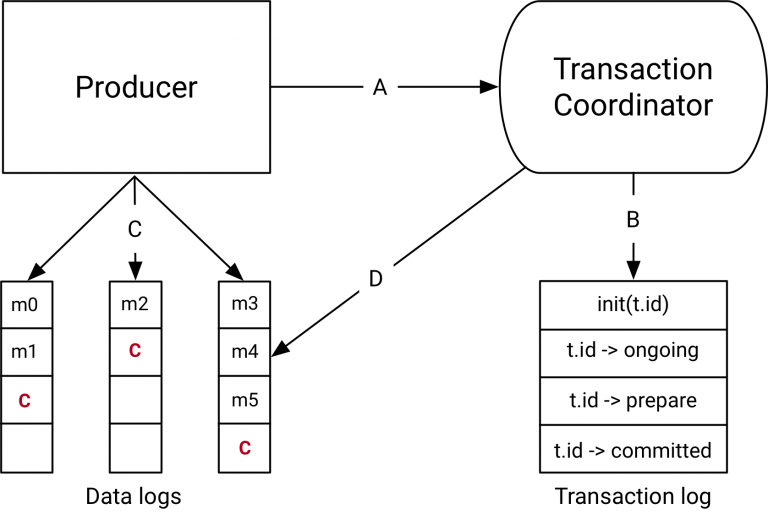
5. 事務協調器和事務日誌
在Kafka 0.11.0中與事務API一起引入的元件是上圖右側的事務Coordinator和事務日誌。
事務Coordinator是每個KafkaBroker內部執行的一個模組。事務日誌是一個內部的Kafka Topic。每個Coordinator擁有事務日誌所在分割槽的子集,即, 這些borker中的分割槽都是Leader。
每個transactional.id都通過一個簡單的雜湊函式對映到事務日誌的特定分割槽。這意味著只有一個Broker擁有給定的transactional.id。
通過這種方式,我們利用Kafka可靠的複製協議和Leader選舉流程來確保事務協調器始終可用,並且所有事務狀態都能夠持久儲存。
值得注意的是,事務日誌只儲存事務的最新狀態而不是事務中的實際訊息。訊息只儲存在實際的Topic的分割槽中。事務可以處於諸如“Ongoing”,“prepare commit”和“Completed”之類的各種狀態中。正是這種狀態和關聯的元資料儲存在事務日誌中。
6. 資料流
資料流在抽象層面上有四種不同的型別。
A. producer和事務coordinator的互動
執行事務時,Producer向事務協調員發出如下請求:
1. initTransactions API向coordinator註冊一個transactional.id。 此時,coordinator使用該transactional.id關閉所有待處理的事務,並且會避免遇到殭屍例項。 每個Producer會話只發生一次。
2. 當Producer在事務中第一次將資料傳送到分割槽時,首先向coordinator註冊分割槽。
3. 當應用程式呼叫commitTransaction或abortTransaction時,會向coordinator傳送一個請求以開始兩階段提交協議。
B. Coordinator和事務日誌互動
隨著事務的進行,Producer傳送上面的請求來更新Coordinator上事務的狀態。事務Coordinator會在記憶體中儲存每個事務的狀態,並且把這個狀態寫到事務日誌中(這是以三種方式複製的,因此是持久儲存的)。
事務Coordinator是讀寫事務日誌的唯一元件。如果一個給定的Borker故障了,一個新的Coordinator會被選為新的事務日誌的Leader,這個事務日誌分割了這個失效的代理,它從傳入的分割槽中讀取訊息並在記憶體中重建狀態。
C. Producer將資料寫入目標Topic所在分割槽
在Coordinator的事務中註冊新的分割槽後,Producer將資料正常地傳送到真實資料所在分割槽。這與producer.send流程完全相同,但有一些額外的驗證,以確保Producer不被隔離。
D. Topic分割槽和Coordinator的互動
在Producer發起提交(或中止)之後,協調器開始兩階段提交協議。
在第一階段,Coordinator將其內部狀態更新為“prepare_commit”並在事務日誌中更新此狀態。一旦完成了這個事務,無論發生什麼事,都能保證事務完成。
Coordinator然後開始階段2,在那裡它將事務提交標記寫入作為事務一部分的Topic分割槽。
這些事務標記不會暴露給應用程式,但是在read_committed模式下被Consumer使用來過濾掉被中止事務的訊息,並且不返回屬於開放事務的訊息(即那些在日誌中但沒有事務標記與他們相關聯)。
一旦標記被寫入,事務協調器將事務標記為“完成”,並且Producer可以開始下一個事務。
7. 事務實踐
現在我們已經理解了事務的語義以及它們是如何工作的,我們將注意力轉向利用事務編寫實際應用方面。
7.1. 如何選擇事務Id
transactional.id在遮蔽殭屍中扮演著重要的角色。但是在一個保持一個在Producer會話中保持一致的識別符號並且正確地遮蔽掉殭屍例項是有點棘手的。
正確隔離殭屍例項的關鍵在於確保讀取程序寫入週期中的輸入Topic和分割槽對於給定的transactional.id總是相同的。如果不是這樣,那麼有可能丟失一部分訊息。
例如,在分散式流處理應用程式中,假設Topic分割槽tp0最初由transactional.idT0處理。如果在某個時間點之後,它可以通過transactional.id T1對映到另一個Producer,那麼T0和T1之間就不會有柵欄了。所以tp0的訊息可能被重新處理,違反了一次處理保證。
實際上,可能需要將輸入分割槽和transactional.id之間的對映儲存在外部儲存中,或者對其進行靜態編碼。Kafka Streams選擇後一種方法來解決這個問題。
7.2. 事務效能以及如何優化?
Ø Producer開啟事務之後的效能
讓我們把注意力轉向事務如何執行。
首先,事務只造成中等的寫入放大。額外的寫入在於:
對於每個事務,我們都有額外的RPC向Coordinator註冊分割槽。這些是批處理的,所以我們比事務中的partition有更少的RPC。
在完成事務時,必須將一個事務標記寫入參與事務的每個分割槽。同樣,事務Coordinator在單個RPC中批量繫結到同一個Borker的所有標記,所以我們在那裡儲存RPC開銷。但是在事務中對每個分割槽進行額外的寫操作是無法避免的。
最後,我們將狀態更改寫入事務日誌。這包括寫入新增到事務的每批分割槽,“prepare_commit”狀態和“complete_commit”狀態。
我們可以看到,開銷與作為事務一部分寫入的訊息數量無關。所以擁有更高吞吐量的關鍵是每個事務包含更多的訊息。
實際上,對於Producer以最大吞吐量生產1KB記錄,每100ms提交訊息導致吞吐量僅降低3%。較小的訊息或較短的事務提交間隔會導致更嚴重的降級。
增加事務時間的主要折衷是增加了端到端延遲。回想一下,Consum閱讀事務訊息不會傳遞屬於公開傳輸的訊息。因此,提交之間的時間間隔越長,消耗的應用程式就越需要等待,從而增加了端到端的延遲。
Ø Consumer開啟之後的效能
Consumer在開啟事務的場景比Producer簡單得多,它需要做的是:
1. 過濾掉屬於中止事務的訊息。
2. 不返回屬於公開事務一部分的事務訊息。
因此,當以read_committed模式讀取事務訊息時,事務Consumer的吞吐量沒有降低。這樣做的主要原因是我們在讀取事務訊息時保持零拷貝讀取。
此外,Consumer不需要任何緩衝等待事務完成。相反,Broker不允許提前抵消包括公開事務。
因此,Consumer是非常輕巧和高效的。感興趣的讀者可以在本文件(連結2)中瞭解Consumer設計的細節。
8. 進一步閱讀
我們剛剛講述了Apache Kafka中事務的表面。 幸運的是,幾乎所有的設計細節都儲存在線上文件中。 相關檔案是:
最初的Kafka KIP(連結3):它提供了關於資料流的設計細節,並且詳細介紹了公共介面,特別是與事務相關的配置選項。
原始設計文件(連結4):不是為了核心,這是原始碼之外的權威地方 - 瞭解每個事務性RPC如何處理,如何維護事務日誌,如何清除事務性資料等等。
KafkaProducerjavadocs(連結5):這是學習如何使用新API的好地方。頁面開始處的示例以及send方法的文件是很好的起點。
9. 結論
在這篇文章中,我們瞭解了ApacheKafka中關於事務API的關鍵設計目標,我們理解了事務API的語義,並對API的實際工作有了更高層次的理解。
如果我們考慮“讀取-處理-寫入”週期,這篇文章主要介紹了讀寫路徑,處理本身就是一個黑盒子。事實是,在處理階段中可以做很多事情,使得一次處理不可能保證單獨使用事務API。例如,如果處理對其他儲存系統有副作用,則這裡覆蓋的API不足以保證exactly once。
Kafka Streams框架使用事務API向上移動整個價值鏈,併為各種各樣的流處理應用提供exactly once,甚至能夠在處理期間更新某些附加狀態並進行儲存。
後續的部落格文章將介紹KafkaStreams如何提供一次處理語義,以及如何編寫利用它的應用程式。
最後,對於那些渴望瞭解上述API實現細節的人,我們將會有另一篇部落格文章,其中涵蓋了這裡描述的一些更有趣的解決方案。