
Kafka Confluent 簡介
簡介
基本模組
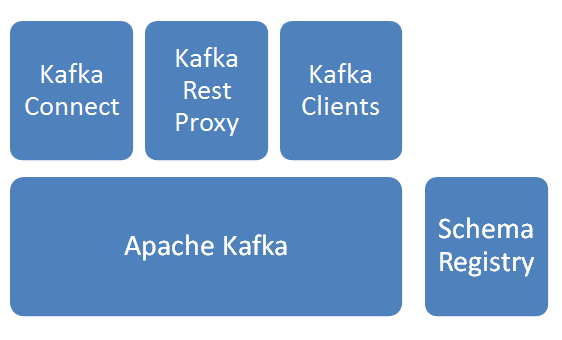
Apache Kafka
訊息分發元件,資料採集後先入Kafka。Schema Registry
Schema管理服務,訊息出入kafka、入hdfs時,給資料做序列化/反序列化處理。Kafka Connect
提供kafka到其他儲存的管道服務,此次焦點是從kafka到hdfs,並建立相關HIVE表。Kafka Rest Proxy
提供kafka的Rest API服務。Kafka Clients
提供Client程式設計所需SDK。
說明:以上服務除Apache kafka由Linkedin始創並開源,其他元件皆由Confluent公司開發並開源。上圖解決方案由confluent提供。
基本邏輯步驟
- 資料通過Kafka Rest/Kafka Client寫入Kafka;
- kafka Connect任務作為consumer從kafka訂閱資料;
- kafka Connect任務建立HIVE表和hdfs檔案的對映關係;
- kafka connect任務收到資料後,以指定格式,寫入指定hdfs目錄;
實操:
1. 啟動服務
啟動kafka 服務
- 修改配置
/*
1.修改192.168.103.44、192.168.103.45、192.168.103.46三臺伺服器上配置
2.配置檔案中broker.id值分別修改為0、1、2
*/
cd /home/ubuntu/confluent-2.0 - 命令列啟動
cd /home/ubuntu/confluent-2.0.0
nohup bin/kafka-server-start etc/kafka/server.properties &- 服務說明
kafka服務無Leader概念,服務訪問埠為9092
啟動Schema Register服務
- 命令列啟動
//wonderwoman叢集環境,只在woderwoman上啟動了服務
cd /home/ubuntu/confluent-2.0.0
nohup bin/schema-registry-start etc/schema-registry - 服務說明
Schema Register服務埠為8081
啟動Kafka Rest API服務
- 修改配置
// 修改schema伺服器地址和zookeeper伺服器地址
cd /home/ubuntu/confluent-2.0.0
vi etc/kafka-rest/kafka-rest.properties- 命令列啟動
//wonderwoman叢集環境,只在woderwoman上啟動了服務
cd /home/ubuntu/confluent-2.0.0
nohup bin/kafka-rest-start ./etc/kafka-rest/kafka-rest.properties &- 服務說明
Schema Register服務埠為8082
啟動Kafka connect服務
- 修改配置
/*
修改如下配置項:
1.bootstrap.servers, 所有kafka broker的地址
2.group.id 標誌connect叢集,叢集內配一致
3.key.converter.schema.registry.url,schema服務地址
4.value.converter.schema.registry.url,schema服務地址
*/
cd /home/ubuntu/confluent-2.0.0/
vi etc/schema-registry/connect-avro-distributed.properties- 命令列啟動
//啟動分散式connect,在zookeeper叢集內所有機器上啟動
cd /home/ubuntu/confluent-2.0.0/
nohup bin/connect-distributed etc/schema-registry/connect-avro-distributed.properties > /tmp/1.log
2. 建立schema
- Rest API方式
- 準備shema的定義檔案,例如myschema.json
- 註冊topic和schema,返回schema的ID
curl -X POST -i -H "Content-Type: application/vnd.schemaregistry.v1+json" --data @myschema.json http://localhost:8081/subjects/20160427/versions
- Kafka Client方式
詳見 Kafka Client提供的介面,支援java/c/c++等語言
3. 建立Topic
建立的topic名稱為xianzhen,3個分割槽,每分割槽資料存兩份
- 命令列方式
cd /home/ubuntu/confluent-2.0.0/
./bin/kafka-topics --create --topic xianzhen --partitions 3 --replication-factor 2 --zookeeper 192.168.103.44:2181Rest API方式
略,後續補充Kafka Client方式
詳見 Kafka Client提供的介面,支援java/c/c++等語言
4. 建立Connector
分散式只支援以REST API的方式提交Connector作業
- Rest API方式
- 建立配置檔案
vi confluentHive-connector.json
{
"name": "hive-final",
"config": {
"connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector",
"tasks.max": "6",
"topics": "confluentHive",
"hdfs.url": "hdfs://ns1",
"hadoop.conf.dir": "/home/ubuntu/hadoop-2.7.1/etc/hadoop",
"hadoop.home": "/home/ubuntu/hadoop-2.7.1",
"flush.size": "100",
"rotate.interval.ms": "1000",
"hive.integration":true,
"hive.metastore.uris":"thrift://192.168.103.44:9083",
"schema.compatibility":"BACKWARD",
"hive.home":"/home/ubuntu/apache-hive-1.2.1-bin",
"hive.conf.dir":"/home/ubuntu/spark-1.6.1/conf"
}
}- 部分配置說明
| 配置項 | 說明 |
|---|---|
| name | Connector名稱,會對應kafka consumer Group的名稱 |
| connector.class | Connector實現類,連線hdfs時,配置見例 |
| tasks.max | 最大任務數量,對應於處理的執行緒數量,不是越多就越快,受kafka分割槽數限制 |
| topics | 訂閱的kafka topic名稱,也對應於最終HIVE的表名 |
| hdfs.url | hdfs的地址,和hadoop的core-site.xml中配置對應上 |
| hadoop.home | hadoop的目錄 |
| hadoop.conf.dir | hadoop的配置目錄 |
| hive.integration | 是否寫入HIVE表 |
| hive.metastore.uris | hive Metastore服務地址 |
| hive.home | HIVE目錄 |
| hive.conf.dir | HIVE的配置目錄 |
- 提交Connector
curl -X POST -H "Content-Type: application/json" --data @confluent-connector.json http://192.168.103.44:8083/connectors5. 資料寫入kafka
寫入資料時,應帶上schema,或者已建立schema的ID
REST API方式
curl -X POST -H "Content-Type: application/vnd.kafka.avro.v1+json" --data '{"value_schema_id":27, "records": [{"value": {"sip":"1.1.1.1", "dip":"1.1.1.2", "smac":"111", "dmac":"112"}}]}' http://192.168.103.44:8082/topics/confluentHiveKafka Client方式
詳見 Kafka Client提供的介面,支援java/c/c++等語言
相關推薦
Kafka Confluent 簡介
簡介 基本模組 Apache Kafka 訊息分發元件,資料採集後先入Kafka。 Schema Registry Schema管理服務,訊息出入kafka、入hdfs時,給資料做序列化/反序列化處理。 Kafka Connect 提供kaf
kafka-confluent管控中心安裝
啟動腳本 3.3 img report 安全 mage sse port -s https://www.confluent.io/ 一個基於kafka的擴展平臺,我們主要關註其管控中心。 由於監控中心只有企業版才有,所以下載企業版,並進行測試。 進入下載中心,可以看到
Kafka基礎簡介
err 日誌 class put 介紹 分享 頻率 actor oid kafka是一個分布式的,可分區的,可備份的日誌提交服務,它使用獨特的設計實現了一個消息系統的功能。 由於最近項目升級,需要將spring的事件機制轉變為消息機制,針對後期考慮,選擇了kafka作為消息
Debezium for MySQL+Kafka+Confluent Schema Registry環境搭建
由於公司業務需要,需要把MySQL中的binlog資訊傳送到kafka上,給相關應用去消費,對資料變化作出響應。 筆者用的
Kafka學習之路 (一)Kafka的簡介
要求 異步通信 images 等等 ron 服務器角色 消費 消息 崩潰 一、簡介 1.1 概述 Kafka是最初由Linkedin公司開發,是一個分布式、分區的、多副本的、多訂閱者,基於zookeeper協調的分布式日誌系統(也可以當做MQ系統),常見可以用於web/ng
Kafka之簡介
1.什麼是kafka? 1.1入門 1.1.1簡介 kafka是LinkedIn開源的一個分散式MQ系統,現在是Apache的孵化專案。 Kafka is a distributed,partitioned,replicated commit logservice ,在
Kafka學習筆記(1)----Kafka的簡介和Linux下單機安裝
1. Kafka簡介 Kafka is a distributed,partitioned,replicated commit logservice。它提供了類似於JMS的特性,但是在設計實現上完全不同,此外它並不是JMS規範的實現。kafka對訊息儲存時根據Topic進行歸類,傳送訊息者成為Produ
Kafka事務簡介
說明:本文翻譯Confluent官網,原文地址: 在之前的部落格文章(見尾部連結)中,我們介紹了ApacheKafka的exactly once語義,介紹了各種訊息傳輸語義,producer的冪等特性,事和Kafka Stream的exactly once處理語義。現
[翻譯]Kafka Streams簡介: 讓流處理變得更簡單
看到一篇不錯的譯文,再推送一撥 Introducing Kafka Streams: Stream Processing Made Simple 這是Jay Kreps在三月寫的一篇文章,用來介紹Kafka Streams。當時Kafka Streams
分散式訊息佇列kafka原理簡介
kafka原理簡介 Kafka是由LinkedIn開發的一個分散式的訊息系統,使用Scala編寫,它以可水平擴充套件和高吞吐率而被廣泛使用。目前越來越多的開源分散式處理系統如Cloudera、Apache Storm、Spark都支援與Kafka整合
kafka connect簡介以及部署
1、什麼是kafka connect? 根據官方介紹,Kafka Connect是一種用於在Kafka和其他系統之間可擴充套件的、可靠的流式傳輸資料的工具。它使得能夠快速定義將大量資料集合移入和
替代Flume——Kafka Connect簡介
我們知道過去對於Kafka的定義是分散式,分割槽化的,帶備份機制的日誌提交服務。也就是一個分散式的訊息佇列,這也是他最常見的用法。但是Kafka不止於此,開啟最新的官網。 我們看到Kafka最新的定義是:Apache Kafka® is a distributed streaming pla
最簡單流處理引擎——Kafka Streams簡介
Kafka在0.10.0.0版本以前的定位是分散式,分割槽化的,帶備份機制的日誌提交服務。而kafka在這之前也沒有提供資料處理的顧服務。大家的流處理計算主要是還是依賴於Storm,Spark Streaming,Flink等流式處理框架。 Storm,Spark Streaming,Flink流處理
Apache Kafka 0.11版本新功能簡介
多個 spa 實現 cer true assign 線程 cto headers Apache Kafka近日推出0.11版本。這是一個裏程碑式的大版本,特別是Kafka從這個版本開始支持“exactly-once”語義(下稱EOS, exactly-once semant
kafka入門:簡介、使用場景、設計原理、主要配置及集群搭建(轉)
request 上傳 結構 數據 send gist segments ring 希望 問題導讀: 1.zookeeper在kafka的作用是什麽? 2.kafka中幾乎不允許對消息進行“隨機讀寫”的原因是什麽? 3.kafka集群consumer和producer狀態信息
ZOOKEEPER和KAFKA簡介
中心 概念 ras ice 規模 PE 傳遞 group 客戶端訪問 目錄KAFKA1. kafka的特性2. Kafka的架構組件簡介3. 重要組件或概念詳解Topic、Partition、OffsetProducersConsumers4. Ka
使用confluent本地安裝和使用kafka
轉載請註明出處:使用confluent本地安裝和使用kafka confluent簡介 confluent是平臺化的工具,封裝了kafka,讓我們可以更方便的安裝和使用監控kafka,作用類似於CDH對於Hadoop。 confluent是由LinkedIn開發出Apache
kafka簡介
搜索 容錯 sum rod stat 廣播 不同 輸入 connector kafka是一種高吞吐量的分布式發布訂閱消息系統,它可以處理消費者規模的網站中所有動作流數據。這種動作(網頁瀏覽、搜索和其他用戶的行動)是現代網絡上的許多社會功能的一個關鍵因素。這些數據通常是由於吞
大資料基礎之Kafka(1)簡介、安裝及使用
http://kafka.apache.org 一 簡介 Kafka® is used for building real-time data pipelines and streaming apps. It is horizontally scalable,&nb
大資料學習之路93-kafka簡介
kafka是實時計算中用來做資料收集的,它是一個訊息佇列。它使用scala開發的。 那麼我們就會想我們這裡能不能用hdfs做資料儲存呢?它是分散式的,高可用的。 但是它還缺少一些重要的功能:比如說我們往hdfs中寫資料,之後我們需要實時的讀取。當我們讀到某一行的時候斷掉了,假如說這個讀取