
機器學習基礎知識點歸納
一.生成模型與判別模型
1.概念介紹
參考:https://blog.csdn.net/u012101561/article/details/52814571
參考:http://www.cnblogs.com/fanyabo/p/4067295.html
監督學習的任務是學習一個模型,對給定的輸入預測相應的輸出,監督學習模型可分為生成模型與判別模型。
直觀來說,生成模型學習的是聯合概率分佈P(X,Y),然後根據條件概率公式計算P(Y|X)= P(X,Y)/ P(X)。基本思想是首先建立樣本的聯合概率概率密度模型P(X,Y),然後再得到後驗概率P(Y|X),再利用它進行分類。
判別模型估計的是條件概率分佈 p(y|x),是給定觀測變數x和目標變數y的條件模型。模型學習的是類別之間的最優分隔面,反映的是不同類資料之間的差異。
由生成模型可以得到判別模型,但由判別模型得不到生成模型。
舉個例子
假如你的任務是識別一個語音屬於哪種語言。例如對面一個人走過來,和你說了一句話,你需要識別出她說的到底是漢語、英語還是法語等。那麼你可以有兩種方法達到這個目的:
(1)學習每一種語言,你花了大量精力把漢語、英語和法語等都學會了。然後再有人過來對你說,你就可以知道他說的是什麼語言。
(2)不去學習每一種語言,你只學習這些語言模型之間的差別,然後再分類。意思是指我學會了漢語和英語等語言的發音是有差別的,我學會這種差別就好了。
那麼第一種方法就是生成方法,第二種方法是判別方法。
2.優缺點
1.判別模型
(1)優點
直接面對預測,往往學習的準確率更高
由於直接學習 P(Y|X) 或 f(X),可以對資料進行各種程度的抽象,定義特徵並使用特徵,以簡化學習過程
(2)缺點
不能反映訓練資料本身的特性
2.生成模型
(1)優點
可以還原出聯合概率分佈 P(X,Y),判別方法不能
學習收斂速度更快——即當樣本容量增加時,學到的模型可以更快地收斂到真實模型
當存在“隱變數”時,只能使用生成模型
(2)缺點
學習和計算過程比較複雜
3.常見模型
(1)判別模型
K 近鄰、感知機(神經網路)、決策樹、邏輯斯蒂迴歸、最大熵模型、SVM、提升方法、條件隨機場
(2)生成模型
樸素貝葉斯、隱馬爾可夫模型、混合高斯模型、貝葉斯網路、馬爾可夫隨機場
二.特徵選擇
參考:https://www.zhihu.com/question/29316149
1.去掉變化較小的特徵
即使用方差選擇法,先要計算各個特徵的方差,然後根據閾值,選擇方差大於閾值的特徵
2.根據相關係數的重要性篩選
3.遞迴特徵消除法
參考:https://www.letiantian.me/2015-04-01-recursive-feature-elimination/
遞迴消除特徵法使用一個基模型來進行多輪訓練,預測模型在原始特徵上訓練,每項特徵指定一個權重。之後,那些擁有最小絕對值權重的特徵被踢出特徵集。如此往復遞迴,直至剩餘的特徵數量達到所需的特徵數量。
4.L1正則
Lasso迴歸
5.其他學習模型類似隨機森林等選出的特徵重要性
6.迴歸模型的前進法,後退法,逐步迴歸法
三.處理不平衡資料
1.欠取樣:當資料量足夠時就該使用此方法,通過減少豐富類的大小來平衡資料集。儲存所有稀有類樣本,並在豐富類別中隨機選擇與稀有類別樣本相等數量的樣本,可以檢索平衡的新資料集以進一步建模;
2.過取樣:當資料量不足時就應該使用過取樣,它嘗試通過增加稀有樣本的數量來平衡資料集,而不是去除豐富類別的樣本的數量。
3.通過設計一個代價函式來懲罰稀有類別的錯誤分類。
四.異常值
1.Cook距離
2、箱線圖
3.孤立森林
一種適用於連續資料的無監督異常檢測方法,即不需要有標記的樣本來訓練,但特徵需要是連續的在孤立森林中,遞迴地隨機分割資料集,直到所有的樣本點都是孤立的。在這種隨機分割的策略下,異常點通常具有較短的路徑。
五.缺失值填充
1.直接刪除高缺失的變數
2.均值填補或者中位數填補,有的時候要根據鄰近資料進行填充
3.將缺失值作為想要預測的,去預測從而實現填補
六.降維
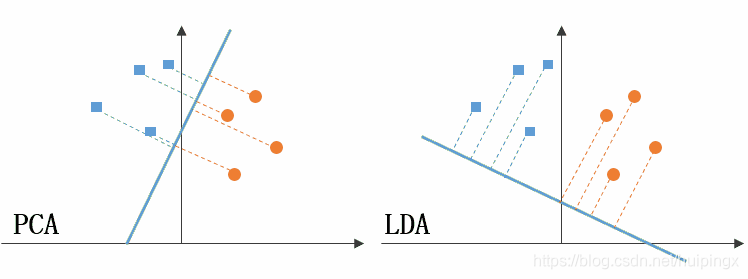
PCA:提取主成分從而描述原資料集波動的最大部分,利用貢獻率來衡量
LDA:線性判別方法,降維過程中要儘可能去拉開不同標籤的組的距離
七.專案一般步驟
1.數學抽象
根據資料明確任務目標,是分類、還是迴歸,或者是聚類。
2.資料獲取
對於分類問題,資料偏斜不能過於嚴重(平衡),不同類別的資料數量不要有數個數量級的差距。
3.特徵工程
歸一化、獨熱、缺失值處理、異常值處理、去除共線性等
特徵選擇
降維
4.模型訓練,調優
多引數調參方法
網格化搜尋: 對於多個引數,首先根據經驗確定大致的引數範圍。然後選擇較大的步長進行控制變數的方法進行搜尋,找到最優解後;然後逐步縮小步長,使用同樣的方法在更小的區間內尋找更精確的最優解
5.模型診斷誤差分析
過擬合、欠擬合判斷。常見的方法如交叉驗證等。
誤差分析也是機器學習至關重要的步驟。通過觀察誤差樣本,全面分析誤差產生誤差的原因:是引數的問題還是演算法選擇的問題,是特徵的問題還是資料本身的問題。
6. 模型融合/整合
7.上線執行
–未完待續