
機器學習基礎---再談歸納偏置
阿新 • • 發佈:2019-03-05

在“機器學習基礎-假設空間、樣本空間與歸納偏置”中提到了歸納偏置實際上是一種模型選擇策略,儘管我們認為A模型更簡單可能具有更好的泛化能力(更貼切實際問題對新資料的預測更準)而選擇了A,但是實際情況中很可能會出現B模型比A更好的情況如圖所示:(注:本文實際是對周志華西瓜書的部分總結)
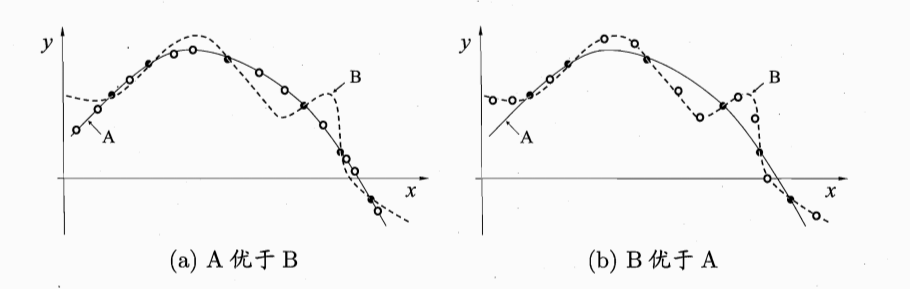
黑點是訓練資料,空心點是新資料,在(b)圖中B模型比A模型更好。
也就是說在無數個模型中都可能會出現比A模型與實際資料更符合的情況(西瓜書中引入了NFL(沒有免費的午餐定理)來著重說明具體問題具體分析,這個具體問題實際上是指資料分佈要與實際問題一致而不是指應用場景一致),換句話說哪個模型與實際情況更加符合我們就選擇那個模型。
現在的問題是我們如何判斷哪個模型與實際情況更加符合,因此引入了下一章節即模型的評估和選擇。
在評估和選擇時,雖然使用了N種方法,但本質上還是將資料分成了訓練集和測試集分別進行模型訓練和模型驗證,我們理想中的情況是訓練集與測試集要同時與實際資料的概率分佈一致,只有這樣我們才能通過技術手段儘量選擇到那個最優的模型,那N種方法直觀上模型評估選擇法,本質上是儘量保證與實際資料的概率分佈一