
深度學習(卷積神經網路)問題總結
深度卷積網路
涉及問題:
1.每個圖如何卷積:
(1)一個圖如何變成幾個?
(2)卷積核如何選擇?
2.節點之間如何連線?
3.S2-C3如何進行分配?
4.16-120全連線如何連線?
5.最後output輸出什麼形式?
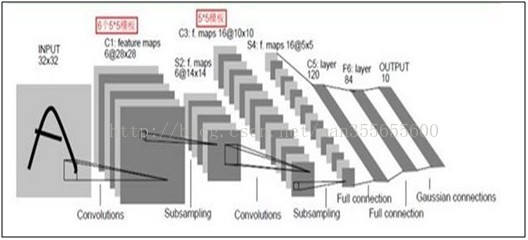
①各個層解釋:
我們先要明確一點:每個層有多個Feature Map,每個Feature Map通過一種卷積濾波器提取輸入的一種特徵,然後每個Feature Map有多個神經元。
C1
S2層是一個下采樣層(為什麼是下采樣?利用影象區域性相關性的原理,對影象進行子抽樣,可以減少資料處理量同時保留有用資訊),有6
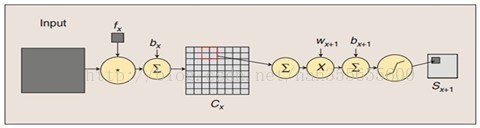
圖:卷積和子取樣過程:卷積過程包括:用一個可訓練的濾波器fx
所以從一個平面到下一個平面的對映可以看作是作卷積運算,S-層可看作是模糊濾波器,起到二次特徵提取的作用。隱層與隱層之間空間解析度遞減,而每層所含的平面數遞增,這樣可用於檢測更多的特徵資訊。
C3層也是一個卷積層,它同樣通過5x5的卷積核去卷積層S2,然後得到的特徵map就只有10x10個神經元,但是它有16種不同的卷積核,所以就存在16個特徵map了。這裡需要注意的一點是:C3中的每個特徵map是連線到S2中的所有6個或者幾個特徵map的,表示本層的特徵map是上一層提取到的特徵map的不同組合(這個做法也並不是唯一的)。(看到沒有,這裡是組合,就像之前聊到的人的視覺系統一樣,底層的結構構成上層更抽象的結構,例如邊緣構成形狀或者目標的部分)。
剛才說C3中每個特徵圖由S2中所有6個或者幾個特徵map組合而成。為什麼不把S2中的每個特徵圖連線到每個C3的特徵圖呢?原因有2點。第一,不完全的連線機制將連線的數量保持在合理的範圍內。第二,也是最重要的,其破壞了網路的對稱性。由於不同的特徵圖有不同的輸入,所以迫使他們抽取不同的特徵(希望是互補的)。
例如,存在的一個方式是:C3的前6個特徵圖以S2中3個相鄰的特徵圖子集為輸入。接下來6個特徵圖以S2中4個相鄰特徵圖子集為輸入。然後的3個以不相鄰的4個特徵圖子集為輸入。最後一個將S2中所有特徵圖為輸入。這樣C3層有1516個可訓練引數和151600個連線。
S4層是一個下采樣層,由16個5*5大小的特徵圖構成。特徵圖中的每個單元與C3中相應特徵圖的2*2鄰域相連線,跟C1和S2之間的連線一樣。S4層有32個可訓練引數(每個特徵圖1個因子和一個偏置)和2000個連線。
C5層是一個卷積層,有120個特徵圖。每個單元與S4層的全部16個單元的5*5鄰域相連。由於S4層特徵圖的大小也為5*5(同濾波器一樣),故C5特徵圖的大小為1*1:這構成了S4和C5之間的全連線。之所以仍將C5標示為卷積層而非全相聯層,是因為如果LeNet-5的輸入變大,而其他的保持不變,那麼此時特徵圖的維數就會比1*1大。C5層有48120個可訓練連線。
F6層有84個單元(之所以選這個數字的原因來自於輸出層的設計),與C5層全相連。有10164個可訓練引數。如同經典神經網路,F6層計算輸入向量和權重向量之間的點積,再加上一個偏置。然後將其傳遞給sigmoid函式產生單元i的一個狀態。
最後,輸出層由歐式徑向基函式(Euclidean Radial Basis Function)單元組成,每類一個單元,每個有84個輸入。換句話說,每個輸出RBF單元計算輸入向量和引數向量之間的歐式距離。輸入離引數向量越遠,RBF輸出的越大。一個RBF輸出可以被理解為衡量輸入模式和與RBF相關聯類的一個模型的匹配程度的懲罰項。用概率術語來說,RBF輸出可以被理解為F6層配置空間的高斯分佈的負log-likelihood。給定一個輸入模式,損失函式應能使得F6的配置與RBF引數向量(即模式的期望分類)足夠接近。這些單元的引數是人工選取並保持固定的(至少初始時候如此)。這些引數向量的成分被設為-1或1。雖然這些引數可以以-1和1等概率的方式任選,或者構成一個糾錯碼,但是被設計成一個相應字元類的7*12大小(即84)的格式化圖片。這種表示對識別單獨的數字不是很有用,但是對識別可列印ASCII集中的字串很有用。
使用這種分佈編碼而非更常用的“1 of N”編碼用於產生輸出的另一個原因是,當類別比較大的時候,非分佈編碼的效果比較差。原因是大多數時間非分佈編碼的輸出必須為0。這使得用sigmoid單元很難實現。另一個原因是分類器不僅用於識別字母,也用於拒絕非字母。使用分佈編碼的RBF更適合該目標。因為與sigmoid不同,他們在輸入空間的較好限制的區域內興奮,而非典型模式更容易落到外邊。
RBF引數向量起著F6層目標向量的角色。需要指出這些向量的成分是+1或-1,這正好在F6 sigmoid的範圍內,因此可以防止sigmoid函式飽和。實際上,+1和-1是sigmoid函式的最大彎曲的點處。這使得F6單元執行在最大非線性範圍內。必須避免sigmoid函式的飽和,因為這將會導致損失函式較慢的收斂和病態問題。
②問題講解
第1個問題:
(1)輸入-C1
用6個5*5大小的patch(即權值,訓練得到,隨機初始化,在訓練過程中調節)對32*32圖片進行卷積,得到6個特徵圖。
(2)S2-C3
C3那16張10*10大小的特徵圖是怎麼來?

將S2的特徵圖用1個輸入層為150(=5*5*6,不是5*5)個節點,輸出層為16個節點的網路進行convolution。
該第3號特徵圖的值(假設為H3)是怎麼得到的呢?
首先我們把網路150-16(以後這樣表示,表面輸入層節點為150,隱含層節點為16)中輸入的150個節點分成6個部分,每個部分為連續的25個節點。取出倒數第3個部分的節點(為25個),且同時是與隱含層16個節點中的第4(因為對應的是3號,從0開始計數的)個相連的那25個值,reshape為5*5大小,用這個5*5大小的特徵patch去convolution S2網路中的倒數第3個特徵圖,假設得到的結果特徵圖為h1。
同理,取出網路150-16中輸入的倒數第2個部分的節點(為25個),且同時是與隱含層16個節點中的第5個相連的那25個值,reshape為5*5大小,用這個5*5大小的特徵patch去convolution S2網路中的倒數第2個特徵圖,假設得到的結果特徵圖為h2。
最後,取出網路150-16中輸入的最後1個部分的節點(為25個),且同時是與隱含層16個節點中的第5個相連的那25個值,reshape為5*5大小,用這個5*5大小的特徵patch去convolution S2網路中的最後1個特徵圖,假設得到的結果特徵圖為h3。
最後將h1,h2,h3這3個矩陣相加得到新矩陣h,並且對h中每個元素加上一個偏移量b,且通過sigmoid的激發函式,即可得到我們要的特徵圖H3了。
第二個問題:
上圖S2中為什麼是150個節點?(涉及到權值共享和引數減少)
CNN一個牛逼的地方就在於通過感受野和權值共享減少了神經網路需要訓練的引數的個數。
下圖左:如果我們有1000x1000畫素的影象,有1百萬個隱層神經元,那麼他們全連線的話(每個隱層神經元都連線影象的每一個畫素點),就有1000x1000x1000000=10^12個連線,也就是10^12個權值引數。然而影象的空間聯絡是區域性的,就像人是通過一個區域性的感受野去感受外界影象一樣,每一個神經元都不需要對全域性影象做感受,每個神經元只感受區域性的影象區域,然後在更高層,將這些感受不同區域性的神經元綜合起來就可以得到全域性的資訊了。這樣,我們就可以減少連線的數目,也就是減少神經網路需要訓練的權值引數的個數了。如下圖右:假如區域性感受野是10x10,隱層每個感受野只需要和這10x10的區域性影象相連線,所以1百萬個隱層神經元就只有一億個連線,即10^8個引數。比原來減少了四個0(數量級),這樣訓練起來就沒那麼費力了,但還是感覺很多的啊,那還有啥辦法沒?
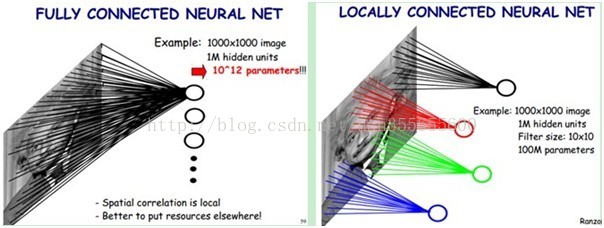
我們知道,隱含層的每一個神經元都連線10x10個影象區域,也就是說每一個神經元存在10x10=100個連線權值引數。那如果我們每個神經元這100個引數是相同的呢?也就是說每個神經元用的是同一個卷積核去卷積影象。這樣我們就只有多少個引數??只有100個引數啊!!!親!不管你隱層的神經元個數有多少,兩層間的連線我只有100個引數啊!親!這就是權值共享啊!親!這就是卷積神經網路的主打賣點啊!親!(有點煩了,呵呵)也許你會問,這樣做靠譜嗎?為什麼可行呢?這個……共同學習。
好了,你就會想,這樣提取特徵也忒不靠譜吧,這樣你只提取了一種特徵啊?對了,真聰明,我們需要提取多種特徵對不?假如一種濾波器,也就是一種卷積核就是提出影象的一種特徵,例如某個方向的邊緣。那麼我們需要提取不同的特徵,怎麼辦,加多幾種濾波器不就行了嗎?對了。所以假設我們加到100種濾波器,每種濾波器的引數不一樣,表示它提出輸入影象的不同特徵,例如不同的邊緣。這樣每種濾波器去卷積影象就得到對影象的不同特徵的放映,我們稱之為Feature Map。所以100種卷積核就有100個Feature Map。這100個Feature Map就組成了一層神經元。到這個時候明瞭了吧。我們這一層有多少個引數了?100種卷積核x每種卷積核共享100個引數=100x100=10K,也就是1萬個引數。才1萬個引數啊!親!(又來了,受不了了!)見下圖右:不同的顏色表達不同的濾波器。
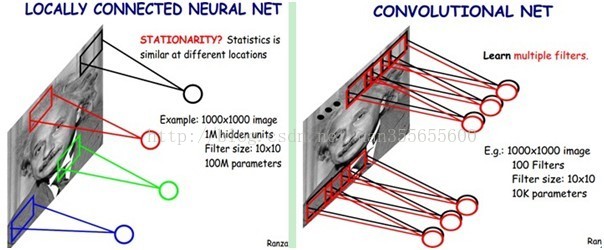
嘿喲,遺漏一個問題了。剛才說隱層的引數個數和隱層的神經元個數無關,只和濾波器的大小和濾波器種類的多少有關。那麼隱層的神經元個數怎麼確定呢?它和原影象,也就是輸入的大小(神經元個數)、濾波器的大小和濾波器在影象中的滑動步長都有關!例如,我的影象是1000x1000畫素,而濾波器大小是10x10,假設濾波器沒有重疊,也就是步長為10,這樣隱層的神經元個數就是(1000x1000 )/ (10x10)=100x100個神經元了,假設步長是8,也就是卷積核會重疊兩個畫素,那麼……我就不算了,思想懂了就好。注意了,這只是一種濾波器,也就是一個Feature Map的神經元個數哦,如果100個Feature Map就是100倍了。由此可見,影象越大,神經元個數和需要訓練的權值引數個數的貧富差距就越大。
所以這裡可以知道剛剛14*14的影象計算它的節點,按步長為3計算,則一幅圖可得5*5個神經元個數,乘以6得到150個神經元個數。
需要注意的一點是,上面的討論都沒有考慮每個神經元的偏置部分。所以權值個數需要加1 。這個也是同一種濾波器共享的。
總之,卷積網路的核心思想是將:區域性感受野、權值共享(或者權值複製)以及時間或空間亞取樣這三種結構思想結合起來獲得了某種程度的位移、尺度、形變不變性。
第三個問題:

如果C1層減少為4個特徵圖,同樣的S2也減少為4個特徵圖,與之對應的C3和S4減少為11個特徵圖,則C3和S2連線情況如圖:

第四個問題:
全連線:
C5對C4層進行卷積操作,採用全連線方式,即每個C5中的卷積核均在S4所有16個特徵圖上進行卷積操作。
第五個問題:
採用one-of-c的方式,在輸出結果的1*10的向量中最大分量對應位置極為網路輸出的分類結果。對於訓練集的標籤也採用同樣的方式編碼,例如1000000000,則表明是數字0的分類。
剛開始學深度學習,還是新手,這些是我一些疑惑的整理,整理出來希望能對一些剛入門的朋友一些幫助,中間可能有些不正確的地方,希望能夠指正