
【深度學習】卷積神經網路(CNN)
卷積神經網路(Convolutional Neural NetWork,CNN):
自然語言處理、醫藥發現、災難氣候發現、人工智慧程式。
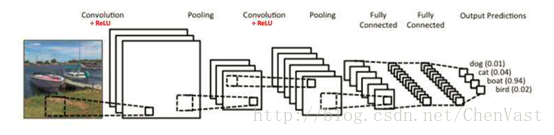
輸入層:
整個神經網路的輸入
卷積層:
卷積神經網路中最重要的部分,卷積層中每一個節點的輸入只是上一層神經網路的一小塊,一般為3x3或者5x5。
卷積層試圖將神經網路中的每一小塊進行更加深入的分析從而得到抽象程度更高的特徵。
通過卷積層處理過的節點矩陣會變得更深,經過卷積層之後的節點矩陣深度增加。
池化層:
池化層神經網路不會改變三維矩陣的深度,但是可以縮小矩陣的大小。
通過池化層可以進一步縮小最後全連線層中節點個數,從而達到減少整個神經網路中引數的目的。
全連線層:
經過多輪卷積層和池化層之後,在卷積神經網路的最後一般由1-2個全連線層來給出最後的分類結果。
獲取高資訊量的特徵,完成分類。
Softmax層:
Softmax層主要用於分類問題,通過Softmax層,可以得到當前樣例屬於不同種類的概率分佈情況。
CNN結構
卷積層:

過濾器/核心
過濾器可以將當前神經網路上的一個子節點矩陣轉化為下一層神經網路上的一個單位節點矩陣。
需要指定過濾器尺寸:常用的過濾器尺寸有3x3和5x5
過濾器處理的矩陣深度和當前層神經網路節點矩陣的深度是一致的,雖然節點矩陣是三維的,但是過濾器尺寸只需要指定這兩個維度。
尺寸指的是過濾器輸入節點矩陣大小
需要指定過濾器深度:深度指的水輸出單位節點矩陣的深度
卷積層的前向傳播過程:通過將一個過濾器從神經網路當前層的左上角移動到右下角,並且在移動中計算每一個對應的單位矩陣。
過濾器每移動一次就會得到一個值。
卷積層前向傳播得到的矩陣尺寸要小於當前層矩陣的尺寸。
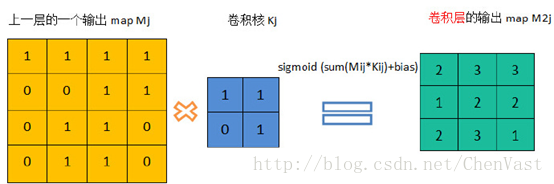

為了避免尺寸變化,可以在當前層矩陣的邊界加入0填充,可使卷積層前向傳播結果矩陣大小和當前層矩陣保持一致。
可以設定過濾器移動的步長來 調整結果矩陣的大小。
共享每一個卷積層中的過濾器中的引數可以巨幅減少神經網路上的引數。
卷積層的引數個數個圖片無關,它只和過濾器尺寸、深度以及當前層節點矩陣的深度有關。
池化層:
卷積層之間往往會加上池化層。
池化層可以非常有效的縮小矩陣的大小,減少最後全連線層中的引數。
使用池化層可以加快計算速度,防止過擬合。
使用的最多的池化層結構為最大池化層,使用較少的池化層為平均池化層。
池化層的過濾器需要人工設定過濾器尺寸、是否0填充、步長,等等設定。
卷積層和池化層的過濾器的方式是相似的,唯一的區別是卷積層使用的過濾器是橫跨整個深度的,池化層使用的過濾器隻影響一個深度上的點。
池化層的過濾器除了在廠礦移動之外還要在深度這個維度移動。
經典卷積神經網路:
LeNet-5模型:共7層。
卷積層(輸入層)-池化層-卷積層-池化層-全連線層-全連線層-全連線層(輸出層)
缺點:無法很好的處理類似於ImageNet這樣比較大的影象資料集。
使用LeNet-5模型實現手寫數字MNIST資料集識別
mnist_infernece.py:
import tensorflow as tf
INPUT_NODE = 784
OUTPUT_NODE = 10
IMAGE_SIZE = 28
NUM_CHANNELS = 1
NUM_LABELS = 10
CONV1_DEEP = 32
CONV1_SIZE = 5
CONV2_DEEP = 64
CONV2_SIZE = 5
FC_SIZE = 512
def inference(input_tensor, train, regularizer):
with tf.variable_scope('layer1-conv1'):
conv1_weights = tf.get_variable(
"weight", [CONV1_SIZE, CONV1_SIZE, NUM_CHANNELS, CONV1_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable("bias", [CONV1_DEEP], initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
with tf.name_scope("layer2-pool1"):
pool1 = tf.nn.max_pool(relu1, ksize = [1,2,2,1],strides=[1,2,2,1],padding="SAME")
with tf.variable_scope("layer3-conv2"):
conv2_weights = tf.get_variable(
"weight", [CONV2_SIZE, CONV2_SIZE, CONV1_DEEP, CONV2_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable("bias", [CONV2_DEEP], initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1, conv2_weights, strides=[1, 1, 1, 1], padding='SAME')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
with tf.name_scope("layer4-pool2"):
pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
pool_shape = pool2.get_shape().as_list()
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
reshaped = tf.reshape(pool2, [pool_shape[0], nodes])
with tf.variable_scope('layer5-fc1'):
fc1_weights = tf.get_variable("weight", [nodes, FC_SIZE],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc1_weights))
fc1_biases = tf.get_variable("bias", [FC_SIZE], initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_weights) + fc1_biases)
if train: fc1 = tf.nn.dropout(fc1, 0.5)
with tf.variable_scope('layer6-fc2'):
fc2_weights = tf.get_variable("weight", [FC_SIZE, NUM_LABELS],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc2_weights))
fc2_biases = tf.get_variable("bias", [NUM_LABELS], initializer=tf.constant_initializer(0.1))
logit = tf.matmul(fc1, fc2_weights) + fc2_biases
return logitmnist_train.py:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_infernece
import os
import numpy as np
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.01
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 10000
MOVING_AVERAGE_DECAY = 0.99
def train(mnist):
# 定義輸出為4維矩陣的placeholder
x = tf.placeholder (tf.float32, [
BATCH_SIZE,
mnist_infernece.IMAGE_SIZE,
mnist_infernece.IMAGE_SIZE,
mnist_infernece.NUM_CHANNELS],
name='x-input')
y_ = tf.placeholder (tf.float32, [None, mnist_infernece.OUTPUT_NODE], name='y-input')
regularizer = tf.contrib.layers.l2_regularizer (REGULARIZATION_RATE)
y = mnist_infernece.inference (x, False, regularizer)
global_step = tf.Variable (0, trainable=False)
# 定義損失函式、學習率、滑動平均操作以及訓練過程。
variable_averages = tf.train.ExponentialMovingAverage (MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply (tf.trainable_variables ())
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits (logits=y, labels=tf.argmax (y_, 1))
cross_entropy_mean = tf.reduce_mean (cross_entropy)
loss = cross_entropy_mean + tf.add_n (tf.get_collection ('losses'))
learning_rate = tf.train.exponential_decay (
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY,
staircase=True)
train_step = tf.train.GradientDescentOptimizer (learning_rate).minimize (loss, global_step=global_step)
with tf.control_dependencies ([train_step, variables_averages_op]):
train_op = tf.no_op (name='train')
# 初始化TensorFlow持久化類。
saver = tf.train.Saver ()
with tf.Session () as sess:
tf.global_variables_initializer ().run ()
for i in range (TRAINING_STEPS):
xs, ys = mnist.train.next_batch (BATCH_SIZE)
reshaped_xs = np.reshape (xs, (
BATCH_SIZE,
mnist_infernece.IMAGE_SIZE,
mnist_infernece.IMAGE_SIZE,
mnist_infernece.NUM_CHANNELS))
_, loss_value, step = sess.run ([train_op, loss, global_step], feed_dict={x: reshaped_xs, y_: ys})
if i % 1000 == 0:
print ("After %d training step(s), loss on training batch is %g." % (step, loss_value))
def main(argv=None):
mnist = input_data.read_data_sets("./MNIST_data", one_hot=True)
train(mnist)
if __name__ == '__main__':
main()經典用於圖片分類問題的卷積神經網路結構:
輸入層—>(卷積層+ —>池化層?)+ —>全連線層+
大部分卷積神經網路中一般最多連續使用三層卷積層
在過濾器深度上,大部分卷積神經網路都採用逐層遞增方式。
卷積層的步長一般為1-3。
池化層配置較為簡單,用的最多的是最大池化層,過濾器邊長和步長一般為2-3
Inception-v3模型
Inception模型結構是一種和LeNet-5結構完全不一樣的卷積神經網路結構。
Inception-v3模型中Inception結構是將不同的卷積層通過並聯的方式結合在一起。
Inception模型:
Inception可以使用不同尺寸的過濾器,然後再將得到的矩陣拼接起來。
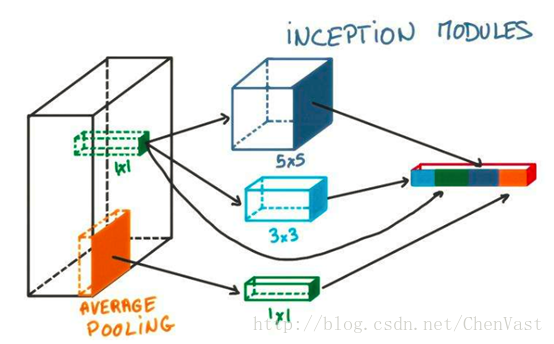
Inception-v3總共有46層,由11個Inception模組組成。
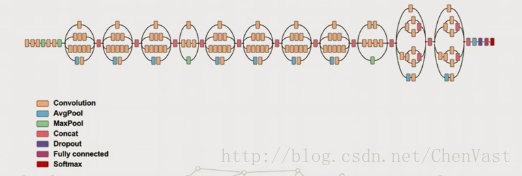
程式碼: