
幾種使用了CNN(卷積神經網路)的文字分類模型
下面就列舉了幾篇運用CNN進行文字分類的論文作為總結。
1 yoon kim 的《Convolutional Neural Networks for Sentence Classification》。(2014 Emnlp會議)
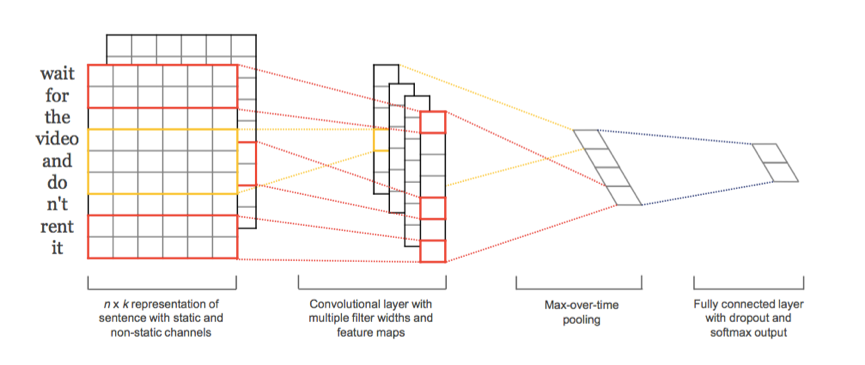
他用的結構比較簡單,就是使用長度不同的 filter 對文字矩陣進行卷積,filter的寬度等於詞向量的長度,然後使用max-pooling 對每一filter提取的向量進行操作,最後每一個filter對應一個數字,把這些filter拼接起來,就得到了一個表徵該句子的向量。最後的預測都是基於該句子的。該模型作為一個經典的模型,作為很多其他改領域論文裡實驗參照。
2 《A Convolutional Neural Network for Modelling Sentences》(2014 ACL會議)
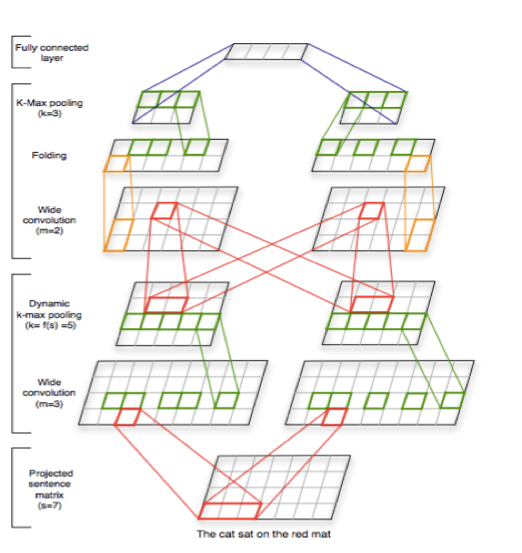
這個模型看起來就相對複雜一些,不過其基礎也是基於卷積的。每一層的卷積操作之後同樣會跟上一個max pooling操作。整個模型操作相對於上面的那個模型比較繁瑣,同時我有以下幾個比較質疑的地方:
1 倒數第二到倒數第三層使用了k-max 的pooling操作,也就是說第三層中相鄰的詞語對應於原來的句子可能不再是相鄰的,而且它們只有相對的先後關係儲存了下來。倒數第三層中不同卷積平面對應的詞語在原句子中可能處於不同的位置,甚至是不同的詞語,因此倒數第三道倒數第四之間的卷積是沒有意義的。
2 關於這裡的folding操作。把同一個詞語向量的不用維度之間進行加法操作,這樣原文裡是這樣解釋的“With a folding layer, a feature detector of the i-th order depends now on two rows of feature values in the lower maps of order i -1.”。但是這樣的操作有意義嗎??從來沒有見人提到用過,也許我們未來可以探索一下這樣是否能夠提高卷積器的效能。
3《A C-LSTM Neural Network for Text Classification》(arXiv preprint arXiv)
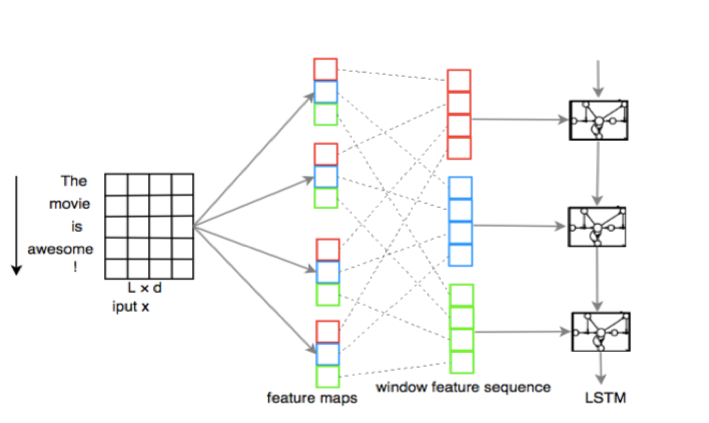
其實這篇論文裡只是用cnn對原文的詞向量以某一長度的filter進行卷積抽象,這樣原來的純粹詞向量序列就變成了經過卷積的抽象含義序列。最後對原句子的encoder還是使用lstm,由於使用了抽象的含義向量,因此其分類效果將優於傳統的lstm,這裡的cnn可以理解為起到了特徵提取的作用。
4 《Recurrent Convolutional Neural Networks for Text Classification》(2015 AAAi會議) 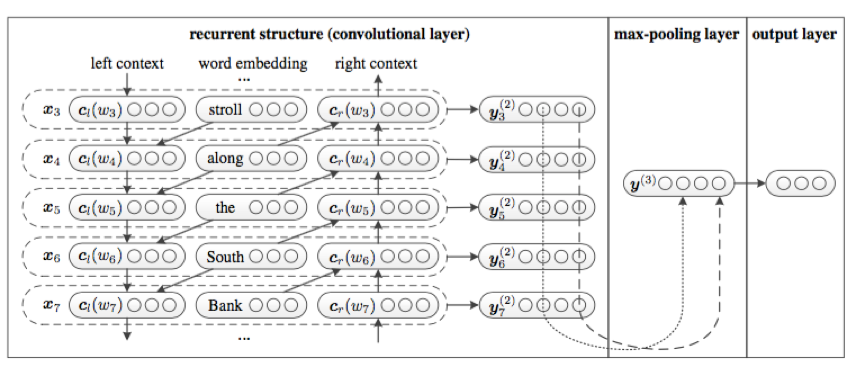
正如標題所說的,把lstm和cnn結合起來了,不過這個結合的方式和上面的不一樣。舉例來說對於詞序列: A B C D E F來說,在形成C詞的向量化表示的時候,使用的不再僅僅是C的word embedding,而是C左邊的內容構成的向量和C以及C右邊內容構成的向量的拼接形式。由於使用到了左右兩邊的內容故使用的是雙向的Lstm。然後如圖中所示使用1-d convolution的方式得到一系列的y,最後經過max-pooling的方式得到整個句子的向量化表示,最後的預測也是基於該句子的。
5 《Learning text representation using recurrent convolutional neural network with highway layers》(arXiv preprint arXiv) 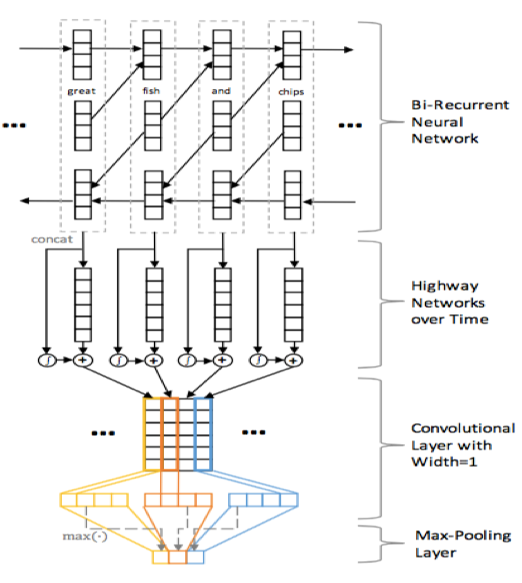
這個模型幾乎就是稍微的更改了一下4中的模型,只不過在C向量拼接完畢將要進行卷積操作之前經過了一個highway而已。(本人對於僅僅加了一個highway就能提高模型準確率的做法感到十分懷疑,畢竟這個網路的層數並不深)