
機器學習筆記(八):強化學習
前面我們介紹的機器學習演算法都屬於人工餵給機器資料,然後機器從這些資料中學得模型。而我們人類的學習過程並不是這樣,人類通過自身的感官感知環境,而後從環境中獲得經驗、知識,因此單純地依靠前面所介紹的方法並不能實現通用人工智慧。那麼有沒有辦法使得機器也能自動地不斷從周圍環境中獲得經驗或‘知識’呢?阿蘭。圖靈曾提出過這樣的設想“除了試圖去建立一個模擬成人大腦的程式外,為什麼不試圖建立一個可以模擬小孩大腦的程式呢?如果他接受適當的教育,就會獲得成人的大腦。”基於這個設想,研究者們提出了強化學習(Reinforcement Learning,又譯為增強學習)的概念。本文主要對強化學習的基本概念與方法進行介紹。
目錄
一、什麼是強化學習(RL)?
二、強化學習的型別
三、常用的強化學習演算法
一、什麼是強化學習?
強化學習是從一種讓agent(智慧主體)自動連續做出決策的機器學習方法。其原理可歸納如下:
在強化學習中,學習者是一個能夠自動做出決策的agent,它通過感知自身所處的狀態(state)與環境來產生動作(action),而不同狀態下的不同動作會帶給agent不同的獎賞(reward)。強化學習的目標就是通過一系列的試錯後找到一種最優的策略(policy),使得經過一系列的動作(actions)後,所獲得的總的獎賞(reward)最大。
為方便理解,可參考下面這張圖
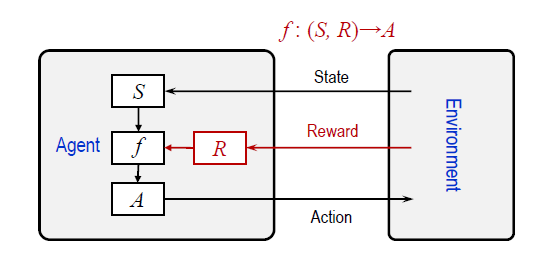
強化學習的Agent主要由三部分構成,分別是:感受器用來感知當前所處狀態(State);決策模型f根據當前狀態下不同動作(Action)的獎賞(Reward)來選擇策略與環境互動;動作器執行這些動作;
基於上面的介紹,我們可以把一個強化學習的過程抽象為以下數學代數的形式
l 一系列agent的狀態
l 一系列agent所能採取的動作
l 動作作用於狀態產生的變化對應關係
l 動作作用於狀態所得到的獎賞
強化學習的目標即尋找最優策略 ,假如上面的四組資料都已知,那麼強化學習的求解可近似於貨郎擔問題,使用貪心演算法即可得到不錯的解。但在我們使用強化學習求解問題時往往是無法獲得T和R的,因此我們必須通過不斷試錯來進行學習。
二、強化學習的型別
目前常見的對強化學習演算法的分類有四種,下面分別介紹。
1、 Model-free 和 Model-based
Model-free和model-based的劃分主要基於演算法中是否用模型來表示環境。
對於Model-based類演算法,其先理解真實世界是怎樣的, 使用MDP與值迭代或策略迭代的方法來學習T和R,建立一個模型來模擬現實世界的反饋。通過想象來預判斷接下來將要發生的所有情況,然後選擇這些想象情況中最好的那種,並依據這種情況來採取下一步的策略。它比 Model-free 多出了一個虛擬環境,還有想象力。
而model-free方法不建立真實世界的模型,環境給什麼就是什麼,一步一步等待真實世界的反饋,再根據反饋採取下一步行動。Model-free方法常用蒙特卡洛方法與動態規劃結合的數學模型來進行規劃。
2、 Policy based 和 value based
Policy based:通過感官分析所處的環境, 直接輸出下一步要採取的各種動作的概率, 然後根據概率採取行動,每種動作都有可能被選中,只是概率不同。
Value based:輸出的是所有動作的價值, 根據最高價值來選動作。相比基於概率的方法,基於價值的決策部分更為肯定,即價值最高的動作一定會被選中,而基於概率的,即使某個動作的概率最高, 但是還是不一定會選到他.
但是對於選取連續的動作,基於價值的方法是無能為力的。我們卻能用一個概率分佈在連續動作中選取特定動作, 這也是基於概率的方法的優點之一。
3、Monte-carlo update(回合更新) 和 Temporal-difference update(單步更新)
強化學習還能用另外一種方式分類,回合更新和單步更新。假設強化學習就是在玩遊戲,遊戲回合有開始和結束。回合更新指的是遊戲開始後,需要等待遊戲結束再總結這一回合,再更新我們的行為準則。而單步更新則是在遊戲進行中每一步都在更新,不用等待遊戲的結束,這樣邊玩邊學習。
4、On-policy 和 Off-policy
所謂On-policy(線上學習),就是指必須本人在場,並且一定是本人一邊行動邊一學習。而Off-policy(離線學習)是你可以選擇自己行動,也可以選擇看著別人行動,通過看別人行動來學習別人的行為準則,離線學習 同樣是從過往的經驗中學習,但是這些過往的經歷沒必要是自己的經歷,任何人的經歷都能被學習。
三、常用的強化學習演算法
1. Sarsa

Q 為動作效用函式(action-utility function),相當於我們在第一章中定義的R,用於評價在特定狀態下采取某個動作的優劣,可以將之理解為智慧體(Agent)的大腦。
SARSA 利用馬爾科夫性質,只利用了下一步資訊, 讓系統按照策略指引進行探索,在探索每一步都進行狀態價值的更新,更新公式如下所示:
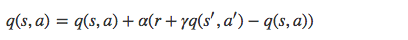
s 為當前狀態,a 是當前採取的動作,s’ 為下一步狀態,a’ 是下一個狀態採取的動作,r 是系統獲得的獎勵, α 是學習率, γ 是衰減因子。
2. Q-Learning

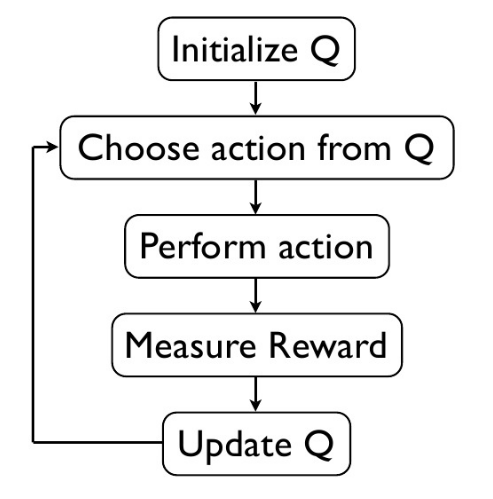
Q Learning 的演算法框架和 SARSA 類似, 也是讓系統按照策略指引進行探索,在探索每一步都進行狀態價值的更新。關鍵在於 Q Learning 和 SARSA 的更新公式不一樣,Q Learning 的更新公式如下:
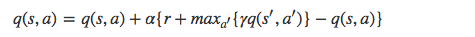
3. Policy Gradients(DeepMind,ICML’14)
系統會從一個固定或者隨機起始狀態出發,策略梯度讓系統探索環境,生成一個從起始狀態到終止狀態的狀態-動作-獎勵序列,s1,a1,r1,.....,sT,aT,rT,在第 t 時刻,我們讓 gt=rt+γrt+1+... 等於 q(st,a) ,從而求解策略梯度優化問題。
4. Actor-Critic(DeepMind,arXiv:1602.01783)
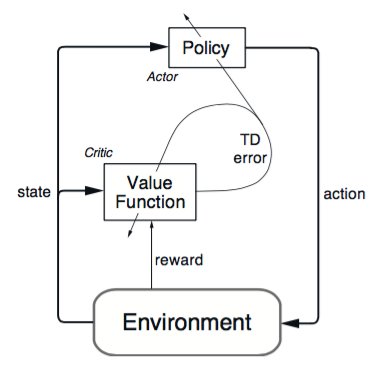
演算法分為兩個部分:Actor 和 Critic。Actor 更新策略, Critic 更新價值。Critic 就可以用之前介紹的 SARSA 或者 Q Learning 演算法。
5.Monte-carlo learning
用當前策略探索產生一個完整的狀態-動作-獎勵序列:
s1,a1,r1,....,sk,ak,rk∼π
在序列第一次碰到或者每次碰到一個狀態 s 時,計算其衰減獎勵:
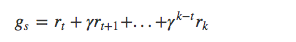
最後更新狀態價值:
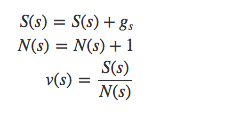
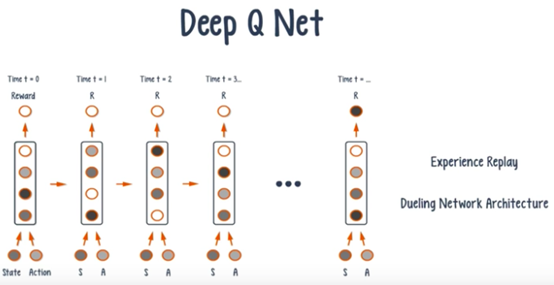
6. Deep-Q-Network(DeepMind,NeruiIPS’13,Nature’15)
DQN可近似看作是CNN+Q-Learning
DQN 演算法的主要做法是 Experience Replay,將系統探索環境得到的資料儲存起來,然後隨機取樣樣本更新深度神經網路的引數。它也是在每個 action 和 environment state 下達到最大回報,不同的是加了一些改進,加入了經驗回放和決鬥網路架構。

參考文獻
1、 王文敏,人工智慧
2、 鄒月嫻,機器學習及其應用
3、 小道蕭兮,《強化學習》,https://www.jianshu.com/p/f8b71a5e6b4d
4、 Alice熹愛學習,《一文了解強化學習》
https://blog.csdn.net/aliceyangxi1987/article/details/73327378