
sklearn-樸素貝葉斯
1. 樸素貝葉斯
樸素貝葉斯方法是一組監督學習演算法,基於貝葉斯定理應用給定類變數值的每對特徵之間的條件獨立性的“樸素”假設。貝葉斯定理在給定類變數的情況下表明瞭以下關係 y 和依賴特徵向量 X1 通過 Xn:
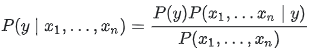
使用樸素的條件獨立假設
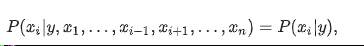
對全部的 i,這種關係簡化為
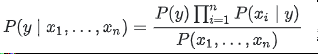
若P(X1,…,Xn) 給定連續的輸入,我們可以使用以下分類規則:
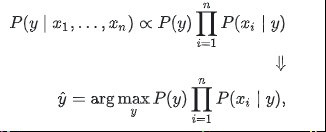
我們可以使用最大後驗(MAP)估計來估計 P(y)P(xi|y)y。不同的樸素貝葉斯分類器主要區別於他們對分佈的假設 P(xi|y),儘管它們顯然過於簡化了假設,但樸素的貝葉斯分類器在許多實際情況中都執行良好,著名的是文件分類和垃圾郵件過濾。他們需要少量的訓練資料來估計必要的引數。與更復雜的方法相比,樸素貝葉斯學習器和分類器可以非常快。類條件特徵分佈的解耦意味著每個分佈可以獨立地估計為一維分佈。這反過來有助於緩解維度懲罰帶來的問題。另一方面,雖然天真的貝葉斯被稱為一個不錯的分類器,但它被認為是一個不好的估計器,所以輸出的概率 predict_proba並不是太準確。
2. 高斯樸素貝葉斯
GaussianNB 實現高斯樸素貝葉斯演算法進行分類。 特徵的可能性被假設為高斯函式的形式:
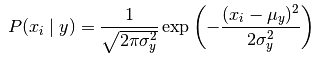
引數 σ_y 和 μ_y 使用最大似然法估計
3. 多項分佈的樸素貝葉斯
MultinomialNB 實現了服從多項分佈資料的樸素貝葉斯演算法,也是用於文字分類(這個領域中資料往往以詞向量表示,儘管在實踐中 tf-idf 向量在預測時表現良好)的兩大經典樸素貝葉斯演算法之一。 分佈引數由每類 y 的 θy = (θy1,…,θyn) 向量決定, 式中 n 是特徵的數量(對於文字分類,是詞彙量的大小),θyi 是樣本中屬於類 y 中特徵 i 概率 P(xi | y) 。
引數 θy 使用平滑過的最大似然估計法來估計,即相對頻率計數:
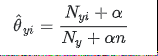
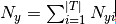
是訓練集T類 y中出現所有特徵的計數總和。先驗平滑因子 α>=0, 應用於在學習樣本中沒有出現的特徵,以防在將來的計算中出現0概率輸出。 把 α = 1 稱為拉普拉斯平滑(Lapalce smoothing),而 α <1被稱為利德斯通平滑(Lidstone smoothing)。
4. 伯努利樸素貝葉斯
BernoulliNB 實現了用於多重伯努利分佈資料的樸素貝葉斯訓練和分類演算法,即有多個特徵,但每個特徵 都假設是一個二元 (Bernoulli, boolean) 變數。 因此,這類演算法要求樣本以二元值特徵向量表示;如果樣本含有其他型別的資料, 一個 BernoulliNB 例項會將其二值化(取決於 binarize 引數)。伯努利樸素貝葉斯的決策規則基於
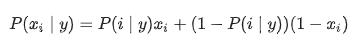
與多項分佈樸素貝葉斯的規則不同 伯努利樸素貝葉斯明確地懲罰類 y 中沒有出現作為預測因子的特徵 i ,而多項分佈分佈樸素貝葉斯只是簡單地忽略沒出現的特徵。
在文字分類的例子中,詞頻向量(而非詞數向量)可能用於訓練和用於這個分類器。 BernoulliNB 可能在一些資料集上可能表現得更好,特別是那些更短的文件。
5. 堆外樸素貝葉斯模型擬合
樸素貝葉斯模型可以解決整個訓練集不能匯入記憶體的大規模分類問題。 為了解決這個問題, MultinomialNB, BernoulliNB, 和 GaussianNB 實現了 partial_fit 方法,可以動態的增加資料,使用方法與其他分類器的一樣,所有的樸素貝葉斯分類器都支援樣本權重。
注:與 fit 方法不同,首次呼叫 partial_fit 方法需要傳遞一個所有期望的類標籤的列表。所有樸素貝葉斯模型呼叫 partial_fit 都會引入一些計算開銷。推薦讓資料快越大越好,其大小與 RAM 中可用記憶體大小相同。
6. 例子
from sklearn import datasets
iris = datasets.load_iris()
# ##高斯樸素貝葉斯
#
# Parameters:
# priors : array-like, shape (n_classes,)
# Prior probabilities of the classes. If specified the priors are not adjusted according to the data.
# var_smoothing : float, optional (default=1e-9):Portion of the largest variance of all features that is added to variances for calculation stability.
# Attributes:
# class_prior_ : array, shape (n_classes,):probability of each class.
# class_count_ : array, shape (n_classes,):number of training samples observed in each class.
# theta_ : array, shape (n_classes, n_features):mean of each feature per class
# sigma_ : array, shape (n_classes, n_features):variance of each feature per class
# epsilon_ : float:absolute additive value to variances
#
# methods:
# fit(X, y[, sample_weight]): Fit Gaussian Naive Bayes according to X, y
# get_params([deep]):Get parameters for this estimator.
# partial_fit(X, y[, classes, sample_weight]):Incremental fit on a batch of samples.
# predict(X):Perform classification on an array of test vectors X.
# predict_log_proba(X):Return log-probability estimates for the test vector X.
# predict_proba(X):Return probability estimates for the test vector X.
# score(X, y[, sample_weight]):Returns the mean accuracy on the given test data and labels.
# set_params(**params):Set the parameters of this estimator.
#
#其他型別的具體可見官方API
#
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf = clf.fit(iris.data, iris.target)
y_pred=clf.predict(iris.data)
print("高斯樸素貝葉斯,樣本總數: %d 錯誤樣本數 : %d" % (iris.data.shape[0],(iris.target != y_pred).sum()))
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB()
clf = clf.fit(iris.data, iris.target)
y_pred=clf.predict(iris.data)
print("多項分佈樸素貝葉斯,樣本總數: %d 錯誤樣本數 : %d" % (iris.data.shape[0],(iris.target != y_pred).sum()))
from sklearn.naive_bayes import BernoulliNB
clf = BernoulliNB()
clf = clf.fit(iris.data, iris.target)
y_pred=clf.predict(iris.data)
print("伯努利樸素貝葉斯,樣本總數: %d 錯誤樣本數 : %d" % (iris.data.shape[0],(iris.target != y_pred).sum()))
結果
