
圖的幾種儲存方式(鄰接矩陣+鄰接表+vector)
阿新 • • 發佈:2018-12-24
最近看到資料結構真的是頭大,剛好想到之前自己因為不會存圖被xxx怒懟,作為一個acmer來說,怎麼能不會這種操作呢。然後現在來總結一下圖的儲存方式。
圖的分類有很多,這裡不再贅述。
來看一個一般的無向圖:通俗地講,一張圖是由邊、頂點集構成,每條邊上可能還會有相應的邊權(帶權的),這裡講帶權的。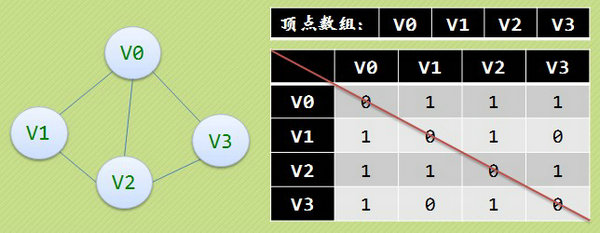
然後想我們怎樣儲存它呢,下面介紹幾種儲存方式。 1、鄰接矩陣 圖的鄰接矩陣儲存方式是用兩個陣列來存圖的,一個一維陣列儲存頂點集,一個二維陣列(鄰接矩陣)儲存的是圖中邊的資訊。 例如:上圖就可以用一個一維陣列head[4]={ v0,v1,v2,v3}儲存頂點資訊,一個二維陣列edge[4][4]儲存邊的資訊(比如edge[i][j]=2,可以將這個陣列看作點i到點j的邊權為2),上面這個圖中,1表示圖中存在點i到點j的邊0表示不存在。但是細心的你也許注意到了,上面的圖是一個無向圖,也就是說i-j的同是j-i也是一樣的,也就是說edge[i][j]==edge[j][i];這個關係利用對稱矩陣可以證明,也就是說,用主對角線為軸的上三角形和下三角形相對應的元素是相等的。而在剛開始的時候將鄰接矩陣初始化為0表示所有點都沒有聯通,時間複雜度O(n^2).好了,具體我們見程式碼:
#include<bits/stdc++.h> using namespace std; const int maxn=1e3+5; #define INF 0x3f3f3f3f int head[maxn];//儲存頂點,這裡不需要 int edge[maxn][maxn]; int n,m;//n個點,m條邊,點的編號為1-n void init() { for(int i=1;i<=n;i++) { for(int j=1;j<=n;j++) { if(i==j) edge[i][j]=0;//自己到自己是0 else edge[i][j]=INF;//初始化為無窮大 } } } int main() { while(scanf("%d%d",&n,&m)!=EOF) { init();//初始化鄰接矩陣 for(int i=0;i<m;i++) { int u,v,w; scanf("%d%d%d",&u,&v,&w); //if(u!=v&&edge[u][v]>w)這裡主要是處理重邊和自環 edge[u][v]=edge[v][u]=w; } for(int i=1;i<=n;i++) { for(int j=i;j<=n;j++) { printf("%d-%d=%d\n",i,j,edge[i][j]); } } } return 0; }
2、鄰接表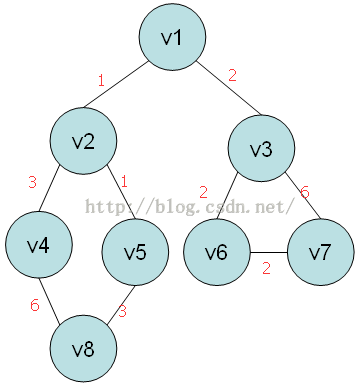
鄰接表存圖主要是使用連結串列儲存,這裡儲存頂點資訊依然使用動態的一維head[] 陣列,而儲存各個邊資訊則需要使用多重連結串列。具體我們見程式碼:上圖的鄰接表如下: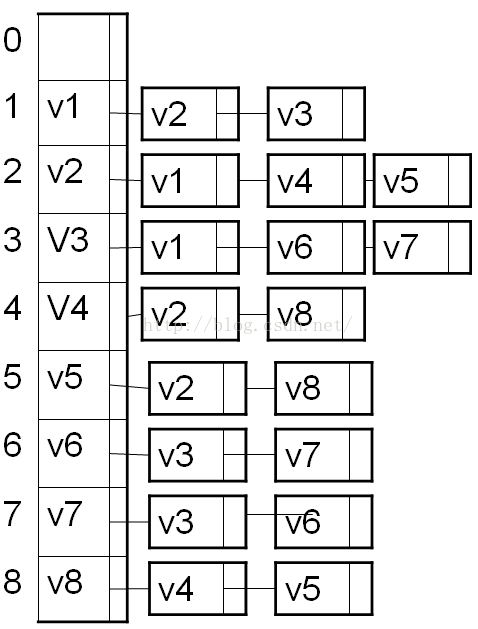
#include<bits/stdc++.h> using namespace std; const int maxn=10005;//點的數量 const int maxm=10005;//邊的數量 int head[maxn];//儲存頂點 int cnt; struct node { int u;//起點 int v;//終點 int w;//權值 int next;//指向上一條邊的編號 }edge[maxn*4];//一般都是要開到邊的四倍 void add(int u,int v,int w) { edge[cnt].u=u; edge[cnt].v=v; edge[cnt].w=w; edge[cnt].next=head[u]; head[u]=cnt++;//頂點編號 } /* 兩種方式都可以,下面的是用C++構造實現 struct node { int v,w,next; node(){} node(int v,int w,int next):v(v),w(w),next(next){} }E[4*maxn]; void add(int u,int v,int w) { E[cnt]=node(v,w,head[u]); head[u]=cnt++; } */ void init() { cnt=0; memset(head,-1,sizeof(head));//表頭陣列初始化 } int main() { int n,m; while(scanf("%d%d",&n,&m)!=EOF) { init(); for(int i=1;i<=m;i++) { int u,v,w; scanf("%d%d%d",&u,&v,&w); add(u,v,w); add(v,u,w);//雙向邊 } int u; scanf("%d",&u);//輸入一個起點 for(int i=head[u];i!=-1;i=edge[i].next)//輸出所有與起點為u相連的邊的終點和權值 { int v=edge[i].v; int w=edge[i].w; printf("%d %d\n",v,w); } } return 0; }
二者區別:
先介紹一下稠密圖和稀疏圖:
對於一個含有n個點m條邊的無向圖,鄰接表表示有n個鄰接表結點和m個邊表結點。邊的數量接近於n*(n-1)的稱作稠密圖,反之為稀疏圖。考慮到鄰接表中要附加鏈域,這時候用鄰接矩陣比較合適。
對於一個含有n個點m條邊的有向圖,鄰接表表示有n個鄰接表結點和2*m個邊表結點。邊的數目遠小於n^2的為稀疏圖,反之為稠密圖。
還有一種存圖方式為vector存圖,有興趣可以瞭解一下,
下面給出程式碼:https://paste.ubuntu.com/p/NK5vxQfZBT/#include<bits/stdc++.h>
using namespace std;
const int maxn=1e3+5;
struct node
{
int u;//起點
int v;//終點
int w;//權值
}E;
vector<node>edge[maxn];//edge[i]表示起點是i,vector裡面儲存的是邊
int main()
{
int n,m;//n個點m條邊
while(scanf("%d%d",&n,&m)!=EOF)
{
//點的編號1-n
for(int i=1;i<=m;i++)
{
int u;
scanf("%d%d%d",&u,&E.v,&E.w);
edge[u].push_back(E);
}
for(int i=1;i<=n;i++)//這裡vector實際上相當於一個二維的動態陣列,第二維大小不確定
{
for(int j=0;j<edge[i].size();j++)
{
node e=edge[i][j];
printf("%d-%d=%d\n",i,e.v,e.w);
}
}
}
return 0;
}