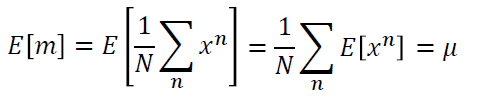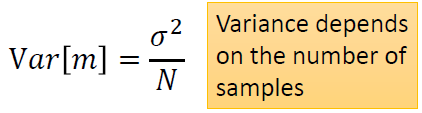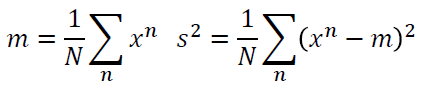Where does the error come from
| //李巨集毅視訊官網:http://speech.ee.ntu.edu.tw/~tlkagk/courses.html 點選此處返回總目錄 //邱錫鵬《神經網路與深度學習》官網:https://nndl.github.io
我們上一次講到,使用不同的model,在testing data上會得到不同的error。而且越複雜的model不一定會得到越低的error。 今天我們要討論的問題是,error來自什麼地方。 其實error有兩個來源,一個是"bias",一個是“variance”。瞭解error的來源是重要的,因為你常常做一下machine learning,做完就得到一個error,接下來你要怎麼improve你的model呢。如果沒有什麼方向,毫無頭緒的亂做,你就沒有效率。如果你可以診斷你的error的來源,你就可以挑選適當的方法來improve你的model。
------------------------------------------------------------------------------------------------------------------------------- 上一節的時候,我們要預測寶可夢進化後的CP值,也就說要找一個function,這個function input一隻寶可夢,output就是進化後的CP值。這個function理論上有一個最佳的function,我們寫成f^。但是這個理論上最佳的function我們是不知道的,只有Niantic是知道的,Niantic就是做寶可夢的公司。f^是我們不知道的,我們能做的事情就是,實際去抓一些寶可夢,根據training data,去學到的最好的function,f*。f*並不會真的等於f^,因為並不知道f^是什麼樣子,f*可能不等於f^。f*就好像是f^的估測值一樣。
就想成,是在打靶。f^是靶的中心,收集到一些data,做training以後,你找到一個你覺得最好的function f*,這個f*不等於f^,它是在靶紙上的另外一個位置。這個f*與f^中間有一段距離,這個距離呢,來自於兩件事:它可能來自於bias,也可能來自於variance。
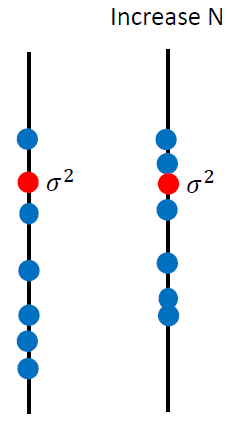
------------------------------------------------------------------------------------------------------------------------------- bias和variance是什麼呢?我們先舉一個概率裡面的例子,概率與統計學過。 假設有一個變數x,想要估計它的mean,怎麼做呢?假設x的mean是 要估測 N個點算平均值m會跟 假設紅點為 但是,如果今天把m的期望值算出來的話: 得到的值就是 那散步在周圍會散的多開呢?取決於m的variance。 variance的值呢depends on samples的個數。如果N比較多的話,就會比較集中。如果N比較少,就會分散地比較開。 要估測variance,即
即,
|