
【轉】通俗理解資訊熵
前段時間德川和我講解了決策樹的相關知識,裡面德川說了一下熵,今天整理了一下,記錄下來希望對大家理解有幫助~
資訊熵的公式
先丟擲資訊熵公式如下:
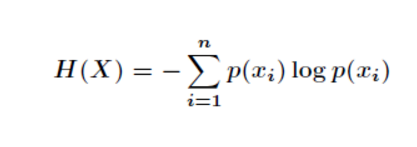
其中代表隨機事件X為
的概率,下面來逐步介紹資訊熵的公式來源!
資訊量
資訊量是對資訊的度量,就跟時間的度量是秒一樣,當我們考慮一個離散的隨機變數x的時候,當我們觀察到的這個變數的一個具體值的時候,我們接收到了多少資訊呢?
多少資訊用資訊量來衡量,我們接受到的資訊量跟具體發生的事件有關。
資訊的大小跟隨機事件的概率有關。越小概率的事情發生了產生的資訊量越大,如湖南產生的地震了;越大概率的事情發生了產生的資訊量越小
例子
腦補一下我們日常的對話:
師兄走過來跟我說,立波啊,今天你們湖南發生大地震了。
我:啊,不可能吧,這麼重量級的新聞!湖南多低的概率發生地震啊!師兄,你告訴我的這件事,資訊量巨大,我馬上打電話問問父母什麼情況。
又來了一個師妹:立波師兄,我發現了一個重要情報額,原來德川師兄有女朋友額~德川比師妹早進一年實驗室,全實驗室同學都知道了這件事。我大笑一聲:哈哈哈哈,這件事大家都知道了,一點含金量都沒有,下次八卦一些其它有價值的新聞吧!orz,逃~
因此一個具體事件的資訊量應該是隨著其發生概率而遞減的,且不能為負。
但是這個表示資訊量函式的形式怎麼找呢?
隨著概率增大而減少的函式形式太多了!不要著急,我們還有下面這條性質
如果我們有倆個不相關的事件x和y,那麼我們觀察到的倆個事件同時發生時獲得的資訊應該等於觀察到的事件各自發生時獲得的資訊之和,即:
h(x,y) = h(x) + h(y)
由於x,y是倆個不相關的事件,那麼滿足p(x,y) = p(x)*p(y).
根據上面推導,我們很容易看出h(x)一定與p(x)的對數有關(因為只有對數形式的真數相乘之後,能夠對應對數的相加形式,可以試試)。因此我們有資訊量公式如下:
下面解決倆個疑問?
(1)為什麼有一個負號
其中,負號是為了確保資訊一定是正數或者是0,總不能為負數吧!
(2)為什麼底數為2
這是因為,我們只需要資訊量滿足低概率事件x對應於高的資訊量。那麼對數的選擇是任意的。我們只是遵循資訊理論的普遍傳統,使用2作為對數的底!
資訊熵
下面我們正式引出資訊熵。
資訊量度量的是一個具體事件發生了所帶來的資訊,而熵則是在結果出來之前對可能產生的資訊量的期望——考慮該隨機變數的所有可能取值,即所有可能發生事件所帶來的資訊量的期望。即
轉換一下為:
最終我們的公式來源推導完成了。
這裡我再說一個對資訊熵的理解。資訊熵還可以作為一個系統複雜程度的度量,如果系統越複雜,出現不同情況的種類越多,那麼他的資訊熵是比較大的。
如果一個系統越簡單,出現情況種類很少(極端情況為1種情況,那麼對應概率為1,那麼對應的資訊熵為0),此時的資訊熵較小。
這也就是我理解的資訊熵全部想法,希望大家指錯交流。也希望對大家理解有幫助~
參考:
prml1.6節
致謝:
德川,郭江師兄
編輯於 2017-04-21