
鏈家二手房樓盤爬蟲
前言
想看下最近房價是否能入手,抓取鏈家 二手房 、 新房 的資訊,發現廣州有些精裝修 88平米 的 3房2廳 首付只要 29 萬!平均 1.1萬/平:

檢視請求資訊
本次用的是火狐瀏覽器32.0配合 firebug 和 httpfox 使用,基於 python3 環境,前期步驟:
- 首先開啟
firefox瀏覽器,清除網頁所有的歷史紀錄,這是為了防止以前的Cookie影響伺服器返回的資料。F12開啟firebug,進入鏈家手機端首頁https://m.lianjia.com,點選 網路 -> 頭資訊 ,檢視請求的頭部資訊。

發現請求頭資訊如下,這個是後面要模擬的:
Host: m.lianjia.com
User-Agent: Mozilla/5.0 (Windows NT 6.3; WOW64; rv:32.0) Gecko/20100101 Firefox/32.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Connection: keep-alive檢視導航連結
點選 firebug 的檢視元素箭頭,選中導航檢視元素:

發現導航的主要是在 class=inner post_ulog 的超連結元素 a 裡面,這裡用 BeautifulSoup 抓取名稱和 href 就好,最後組成一個字典:
# 獲取引導頻道 def getChannel(html): channelDict = {} soup = BeautifulSoup(html, "html.parser") channels = soup.find_all("a", attrs={"class": "inner post_ulog"}) for channel in channels: list_tmp = channel.find_all("div", attrs={"class": "name"}) channelName = list_tmp[0].get_text() channelHref = channel.get('href') channelDict[channelName] = channelHref return channelDict
結果如下:
{'海外': '/i/', '賣房': '/bj/yezhu/', '新房': '/bj/loupan/fang/', '找小區': '/bj/xiaoqu/', '查成交': '/bj/chengjiao/', '租房': '/chuzu/bj/zufang/', '二手房': '/bj/ershoufang/index/', '寫字樓': 'https://shang.lianjia.com/bj/'}獲取城市編碼
點選頁面低於按鈕,獲取城市編碼:
發現城市的編碼主要在 class=block city_block 的 div 裡面,如下抓取所有就好,這裡需要的是廣州,廣州的城市編碼是 gz :
# 獲取城市對應的縮寫
def getCity(html):
cityDict = {}
soup = BeautifulSoup(html, "html.parser")
citys = soup.find_all("div", attrs={"class": "city_block"})
for city in citys:
list_tmp = city.find_all('a')
for a in list_tmp:
cityHref = a.get('href')
cityName = a.get_text()
cityDict[cityName] = cityHref
return cityDict結果如下:
{'文昌': '/wc/', '大理': '/dali/', '威海': '/weihai/', '達州': '/dazhou/', '中山': '/zs/', '佛山': '/fs/', '呼和浩特': '/hhht/', '合肥': '/hf/', '南昌': '/nc/', '昆明': '/km/', '定安': '/da/', '宜昌': '/yichang/', '襄陽': '/xy/', '嘉興': '/jx/', '廈門': '/xm/', '青島': '/qd/', '株洲': '/zhuzhou/', '西安': '/xa/', '泉州': '/quanzhou/', '濟南': '/jn/', '澄邁': '/cm/', '濰坊': '/wf/', '保定': '/bd/', '綿陽': '/mianyang/', '重慶': '/cq/', '儋州': '/dz/', '南充': '/nanchong/', '南京': '/nj/', '北京': '/bj/', '杭州': '/hz/', '滁州': '/cz/', '咸寧': '/xn/', '瓊海': '/qh/', '洛陽': '/luoyang/', '紹興': '/sx/', '廊坊': '/lf/', '惠州': '/hui/', '南通': '/nt/', '上饒': '/sr/', '湛江': '/zhanjiang/', '秦皇島': '/qhd/', '黃石': '/huangshi/', '武漢': '/wh/', '天津': '/tj/', '哈爾濱': '/hrb/', '黃岡': '/hg/', '龍巖': '/ly/', '長春': '/cc/', '珠海': '/zh/', '邢臺': '/xt/', '三亞': '/san/', '北海': '/bh/', '太原': '/ty/', '德陽': '/dy/', '萬寧': '/wn/', '承德': '/chengde/', '五指山': '/wzs/', '陵水': '/ls/', '成都': '/cd/', '深圳': '/sz/', '咸陽': '/xianyang/', '煙臺': '/yt/', '東莞': '/dg/', '清遠': '/qy/', '西雙版納': '/xsbn/', '鄭州': '/zz/', '淮安': '/ha/', '漳州': '/zhangzhou/', '常德': '/changde/', '邯鄲': '/hd/', '上海': '/sh/', '開封': '/kf/', '蘇州': '/su/', '衡水': '/hs/', '無錫': '/wx/', '廣州': '/gz/', '銀川': '/yinchuan/', '徐州': '/xz/', '大連': '/dl/', '海口': '/hk/', '晉中': '/jz/', '福州': '/fz/', '新鄉': '/xinxiang/', '瀋陽': '/sy/', '瓊中': '/qz/', '樂東': '/ld/', '淄博': '/zb/', '眉山': '/ms/', '寧波': '/nb/', '張家口': '/zjk/', '保亭': '/bt/', '長沙': '/cs/', '臨高': '/lg/', '石家莊': '/sjz/', '許昌': '/xc/', '鎮江': '/zj/', '樂山': '/leshan/', '貴陽': '/gy/'}模擬請求二手房
點選二手房連結進入二手房列表頁面,發現列表頁面的 url 是 https://m.lianjia.com/bj/ershoufang/index/ ,把網頁往下拉進行翻頁,發現下一頁的 url 構造為:

只是在原來的網址後面添加了頁碼 pg1 ,但是在 httpfox 裡面驚奇的發現了一段 json:

- 對於爬蟲的各位作者有個忠告:能抓取json就抓取json!*
json是一個API介面,相比於網頁來說更新頻率低,網頁架構很容易換掉,但是API介面一般不會換掉,且換掉後維護的成本比網頁低。試想,介面只是一個dict,如果更新只要在程式碼裡面改key就好了;而網頁更新後,需要改的是bs4裡面的元素,對於以後開發過多的爬蟲來說,維護特別麻煩!
所以對於這裡肯定是抓取 json,檢視頭部:
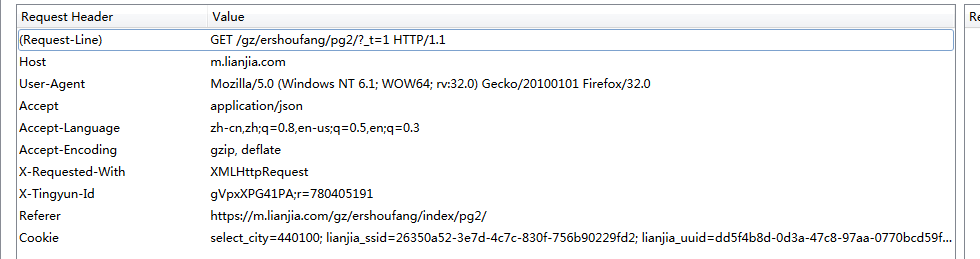
頭部需要攜帶 cookie !
所以這裡需要攜帶 cookie。而 requests 本身就有抓取攜帶 cookie 的寫法。那麼作者就在從獲取導航連結、城市編碼都獲取更新 cookie。而在每一次 requests 請求的時候,返回 cookie 的程式碼為:
session.get(url, headers=headers)
html_set_cookie = requests.utils.dict_from_cookiejar(session.cookies)那麼在導航連結、城市編碼的時候,不僅僅返回網頁的 html ,還多返回一個 cookie :
print("構建城市編碼url")
url_get_city = url_ori + "/city/"
print("獲取城市編碼", ":", url_get_city)
html_set_cookie, html_city = getHtml(url_get_city)
cityDict = getCity(html_city)
url_city = url_ori + cityDict[city]
print("訪問獲取導航", ":", url_city)
html_set_cookie, html_city_content = getHtml(url_city, _cookie=html_set_cookie)然後在請求頭攜帶 cookie :
# 解析網頁
def getHtml(url, _cookie=None):
html_bytes = session.get(url, headers=headers, cookies=_cookie)
html_set_cookie = requests.utils.dict_from_cookiejar(session.cookies)
return html_set_cookie, html_bytes.content.decode("utf-8", "ignore")這裡也模擬請求頭攜帶 cookie 後抓取下來的 json 為:
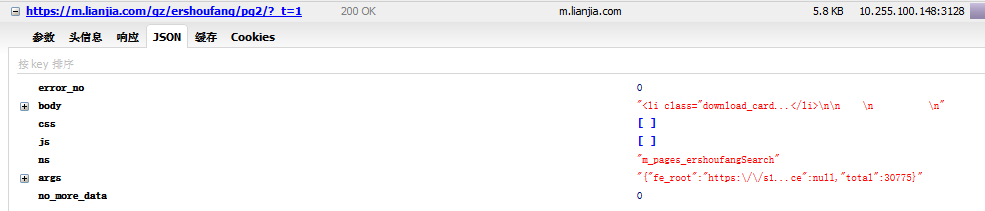
而主要的資訊在 body 裡面,直接解析 html 變成 dict ,提取 body 出來:
html_bytes = session.get(url_detail, headers=headerJson, cookies=html_set_cookie)
html_detail = html_bytes.content.decode("utf-8", "ignore")
detailJson = json.loads(html_detail)發現資訊都在 class=item_list 裡面,直接用 bs4 抓取即可。可以抓取到的資訊為:標題、標籤、房子構造、面積、總價、單價、房屋朝向、詳情頁 url 等:

獲取資訊的部分程式碼為:
# 獲取二手房的詳細資訊
def getInfoErshoufang(html):
detailArr = []
soup = BeautifulSoup(html, "html.parser")
detailInfo = soup.find_all("div", attrs={"class": "item_list"})
detailUrl = soup.find_all("a", attrs={"class": "a_mask"})
details = zip(detailInfo, detailUrl)
for info_url in details:
info = info_url[0]
detailDict = {}
# 獲取標題
title_tmp = info.find_all("div", attrs={"class": "item_main"})
detail_title = title_tmp[0].get_text()
# 獲取房屋大小
size_tmp = info.find_all("div", attrs={"class": "item_other"})
detail_size = size_tmp[0].get_text()
# 獲取價格單價
price_total_tmp = info.find_all("span", attrs={"class": "price_total"})
detail_price_total = price_total_tmp[0].get_text()
try:
unit_price_tmp = info.find_all("span", attrs={"class": "unit_price"})
detail_unit_price = unit_price_tmp[0].get_text()
except:
detail_unit_price = "88888888元/平"
# 獲取標籤
tag_tmp = info.find_all("div", attrs={"class": "tag_box"})
detail_tag = tag_tmp[0].get_text()
# 獲取詳情頁
url_a = info_url[1]封裝程式碼
為了讓程式碼更加的和諧,這裡對程式碼進行了封裝,包括如下幾個方面:
- 選擇城市
- 選擇檢視二手房、新房等
- 詳情頁抓取頁數
- 計算首付
- 按照首付升序排列
目前只寫那麼多了,畢竟博文只教方法給讀者,更多抓取的資訊需要各位讀者根據自己的需求新增
下載原始碼
作者已經將原始碼放到 github 上面了,包括 3 個 py 檔案:
- lianjia.py ,跳轉頁面到詳情頁的程式碼,為主程式碼
- GetDetail.py,抓取詳情頁翻頁的程式碼
- GetInfo.py,提取詳情頁裡面資訊的程式碼
原始碼地址為: