
零基礎教你搭建Hadoop叢集
零基礎教你搭建Hadoop叢集
需要的安裝包:
- JDK壓縮包
- Hadoop壓縮包
linux安裝虛擬機器
使用linux安裝虛擬機器就不做過多描述,可以參考(隨便找的連結),安裝的方法大同小異
https://blog.csdn.net/a89649997/article/details/59107918
一、使用VMvare建立兩個虛擬機器,使用的是ubuntu16.04版本的,並關閉全部虛擬機器的防火牆
a)因為預設的虛擬機器主機名都是ubuntu,所以為了便於虛擬機器的識別,建立完成虛擬機器後我們對虛擬機器名進行修改,我們把用於主節點的虛擬機器名稱設為master(按自己的喜好建立),把用於從節點的虛擬機器名稱設為slave1
- 修改主機名的命令:sudo gedit /etc/hostname,把原主機名ubuntu改為master(在從主機上則改為slave1)

b)為了虛擬機器之間能ping通,需要修改虛擬機器的ip地址(這裡以在master機器操作為例子,從節點的虛擬機器也要進行一致的操作),把/etc/hosts中yangcx-virtual-machine修改為剛剛改過的主機名master,同時將前面的ip地址改為實際的ip地址
- 命令:sudo gedit /etc/hosts
檢視IP地址命令
命令:ifconfig -a
上圖紅框標記的就是虛擬機器的真實ip地址,因此我們把/etc/hosts中的內容修改為:
slave1的ip地址就是從虛擬機器slave1的真實ip地址。同樣,我們在slave1虛擬機器上也要進行這一步操作。




c)關閉虛擬機器的防火牆
ubuntu預設都是安裝防火牆軟體ufw的,使用命令 sudo ufw version,如果出現ufw的版本資訊,則說明已有ufw。使用命令 sudo ufw status檢視防火牆開啟狀態:如果是active則說明開啟,如果是inactive則說明關閉。
- 開啟/關閉防火牆 (預設設定是’disable’)
sudo ufw enable|disable
使用sudo ufw disble來關閉防火牆,並再次用sudo ufw status 檢視防火牆是否關閉。
二、安裝jdk(所有虛擬機器都要安裝配置)
將jdk的壓縮檔案拖進master和slave1虛擬機器中,壓縮(右鍵extract here),或者用命令列tar -zxvf jdk1.8.0_161.tar.gz
配置環境jdk環境:
命令:sudo gedit /etc/profile
將jdk的路徑新增到檔案後面(根據自己的檔案路徑來,我這裡jdk1.8.0_161資料夾的路徑是/home/hadoop/java)
儲存退出,為了使配置立即生效,鍵入命令:source /etc/profile,或者重啟虛擬機器,命令:shutdown -r now
檢查路徑jdk是否安裝成功,鍵入命令:java -version
如果出現了版本資訊,則恭喜配置成功;

三、安裝SSH服務
1.首先確保虛擬機器能連上網
2.更新源列表:sudo apt-get update
3.安裝ssh:輸入"sudo apt-get install openssh-server"–>回車–>輸入"y"–>回車–>安裝完成。
4.檢視ssh服務是否啟動,開啟"終端視窗",輸入"sudo ps -e |grep ssh"–>回車–>有sshd,說明ssh服務已經啟動,如果沒有啟動,輸入"sudo service ssh start"–>回車–>ssh服務就會啟動。
四、建立ssh無密碼登入本機
ssh生成金鑰有rsa和dsa兩種生成方式,預設情況下采用rsa方式。
1.建立ssh-key,這裡我們採用rsa方式
ssh-keygen -t rsa -P “” //(P是要大寫的,後面跟"")

(注:回車後會在~/.ssh/下生成兩個檔案:id_rsa和id_rsa.pub這兩個檔案是成對出現的)
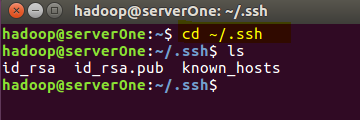
2.進入~/.ssh/目錄下,將id_rsa.pub追加到authorized_keys授權檔案中,開始是沒有authorized_keys檔案的
cd ~/.ssh
輸入命令
cat id_rsa.pub >> authorized_keys
完成後就可以無密碼登入本機了。

3.登入localhost
ssh localhost
(注:當ssh遠端登入到其它機器後,現在你控制的是遠端的機器,需要執行退出命令才能重新控制本地主機)

4.執行退出命令
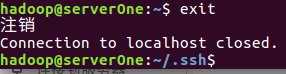
前面1~4步驟,在master和slave1兩臺虛擬機器上都是配置
5.配置master無密碼登陸slave1
mater主機中輸入命令複製一份公鑰到home中
把master的home目錄下的id_rsa_master.pub拷到slave1的home下(做法是先拖到windows桌面上,在拖進slave1虛擬機器中)

slave1的home目錄下分別輸入命令

至此實現了mater對slave1的無密碼登陸
五.安裝hadoop
a)將hadoop壓縮包拖進master虛擬機器中,解壓(這裡解壓的路徑是/home/hadoop/hadoop-2.7.3)
b)在hadoop-2.7.3資料夾裡面先建立4個資料夾:
hadoop-2.7.3/hdfs
hadoop-2.7.3/hdfs/tmp
hadoop-2.7.3/hdfs/name
hadoop-2.7.3/hdfs/data
c)配置 hadoop的配置檔案
先進入配置檔案的路徑:cd /home/hadoop/hadoop-2.7.3/etc/hadoop(對應到自己的路徑)
命令ls,檢視該路徑下的檔案列表(被紅框框住的檔案是要程序配置的檔案)
c1) 首先配置core-site.xml檔案
在configuration中加入以下程式碼:
(注意:第一個屬性中的value和之前建立的/hadoop-2.7.3/hdfs/tmp路徑要一致)




c2) 配置 hadoop-env.sh檔案, 將JAVA_HOME檔案配置為本機JAVA_HOME路徑
c3) 配置yarn-env.sh
將其中的JAVA_HOME修改為本機JAVA_HOME路徑
c4) 配置hdfs-site.xml
在configuration中加入以下程式碼:
注意(其中第二個dfs.namenode.name.dir和dfs.datanode.data.dir的value和之前建立的/hdfs/name和/hdfs/data路徑一致;因為這裡只有一個從主機slave1,所以dfs.replication設定為1)




c5 )複製mapred-site.xml.template檔案,並命名為mapred-site.xml, 配置 mapred-site.xml,在標籤configuration中新增以下程式碼


c6)配置yarn-site.xml
在標籤configuration中新增以下程式碼


c7) 配置slaves 檔案, 把原本的localhost刪掉,改為slave1
c8) 配置hadoop的環境,就像配置jdk一樣,根據hadoop資料夾的路徑配置,以路徑/home/hadoop/hadoop-2.7.3 為例,鍵入命令 source /etc/profile 使配置立即生效



c9) 接下來,將hadoop傳到slave1虛擬機器上面去
(注意:hadoop是虛擬機器的使用者名稱,建立slave1時設定的,傳過去後,在slave1上面同樣對hadoop進行路徑配置,和c8步一樣)

c10) 初始化hadoop
c11) 開啟hadoop
兩種方法:
start-all.sh
先start-dfs.sh,再start-yarn.sh
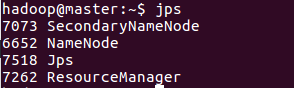
如果在mater上面鍵入jps後看到
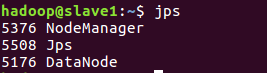
在slave1上鍵入jps後看到
則說明叢集搭建成功

六 、最後用自帶的樣例測試hadoop叢集能不能正常跑任務
用來求圓周率,pi是類名,第一個10表示Map次數,第二個10表示隨機生成點的次數(與計算原理有關)
則恭喜你,hadoop叢集搭建完成


如需瞭解更加詳細安裝及知識點可以參考
https://blog.csdn.net/hliq5399/article/details/78193113
喜歡的小夥伴點個贊
原創作者請點選詳情
https://mp.weixin.qq.com/s/U73v01opZdJG8hu1H_nx8w