
批標準化(Batch Normalization)、Tensorflow實現Batch Normalization
批標準化(Batch Normalization):
論文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
論文地址:https://arxiv.org/pdf/1502.03167.pdf
Batch Normalization的基本思想:
深層神經網路在每一層做線性變換(y=wx+b)後,得到的值隨著網路深度加深或者在訓練過程中,其分佈會逐漸發生偏移或者變動,之所以訓練收斂慢,一般是整體分佈逐漸往非線性函式(如sigmoid函式)的取值區間的上下限兩端靠近,這會導致反向傳播時低層神經網路的梯度消失,這就是訓練深層神經網路收斂越來越慢的本質原因。
Batch Normalization就是通過一定的規範化手段,把線性變換後得到的值的分佈強行拉回到均值為0方差為1的標準正態分佈,這樣使得這些值落在非線性函式中對輸入比較敏感的區域,這樣輸入值的小變化就會導致損失函式較大的變化,梯度就會變大,避免梯度消失的問題。而且梯度變大意味著學習收斂速度快,能大大加快訓練速度。
Batch Normalization訓練神經網路模型的步驟:
首先,求每一個訓練批次輸入資料的均值:

然後,求每一個訓練批次輸入資料的方差:

使用求得的均值和方差對該批次的訓練資料做歸一化,獲得0-1分佈(其中ε是為了避免除數為0時所使用的微小正數):
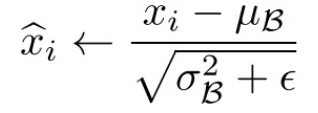
由於歸一化後的![]() 基本會被限制在正態分佈下,這會使得網路的表達能力下降。
基本會被限制在正態分佈下,這會使得網路的表達能力下降。
為解決該問題,我們引入兩個新的引數:γ,β。 γ和β是在訓練時網路自己學習得到的,它們用來恢復要學習的特徵。
我們將![]() 乘以γ調整數值大小,再加上β增加偏移後得到
乘以γ調整數值大小,再加上β增加偏移後得到![]() ,這裡的γ是尺度因子,β是平移因子。
,這裡的γ是尺度因子,β是平移因子。

在訓練過程中,我們還需要計算反向傳播loss函式的梯度,並且計算每個引數(注意:γ 和 β)。 我們使用鏈式法則,如下所示:
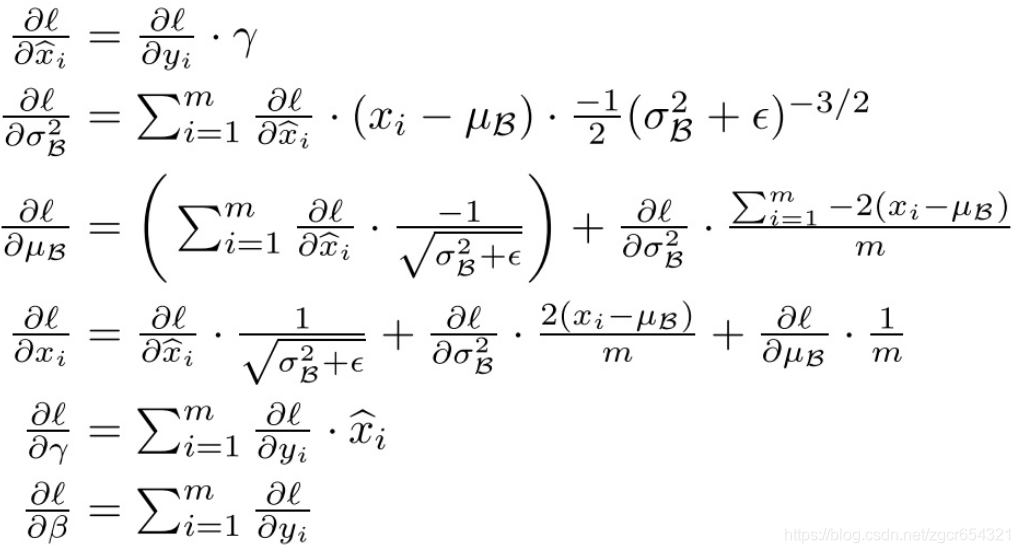
Batch Normalization測試神經網路模型的步驟:
測試時我們沒有mini-batch,但我們可以用下面幾種方法計算出進行歸一化時的平均值和方差。
方法1:
即平均值為所有mini-batch的平均值的平均值,而方差為每個batch的方差的無偏估計;
方法2:
使用我們之前介紹過的指數加權平均(exponentially weighted average)的方法來預測測試過程單個樣本的![]() 和
和![]() 。對於第
。對於第![]() 層隱藏層,考慮所有mini-batch在該隱藏層下的
層隱藏層,考慮所有mini-batch在該隱藏層下的![]() 和
和![]() ,然後用指數加權平均的方式來預測得到當前單個樣本的
,然後用指數加權平均的方式來預測得到當前單個樣本的![]() 和
和![]() 。這樣就實現了對測試過程單個樣本的均值和方差估計。最後,再利用訓練過程得到的γ和 β值計算出各層的
。這樣就實現了對測試過程單個樣本的均值和方差估計。最後,再利用訓練過程得到的γ和 β值計算出各層的![]() 值。
值。
舉例說明:
為什麼我們要把線性變換後的輸出值調整成均值為0,方差為1的標準正態分佈?
首先看正態分佈的圖:

由上圖我們可知,在一個標準差範圍內,也就是x值落在[-1,1]的範圍內的概率為68%,在兩個標準差範圍內,也就是說x值落在[-2,2]的範圍內的概率為95%。
我們再看一下sigmoid(x)函式的影象:

現在我們假設沒有經過Batch Normalization調整前的x值滿足均值是-6、方差是1的正態分佈,那麼就有95%的值落在了[-8,-4]之間,此時對應的sigmoid(x)的值接近於0,這個區域的導數值很小,函式值變化很慢。而假設經過Batch Normalization調整後的x值滿足均值是0、方差是1的正態分佈,那麼就有95%的x值落在了[-2,2]區間內,這一段區間內sigmoid(x)函式的導數值比較大,函式變化較快,故這個區域的梯度變化也比較大。
因此,經過Batch Normalization調整後,x值落到了梯度變化較大的區間,這樣我們訓練時權重更新的幅度就比較大,訓練過程就會加快。
另外,BN為了保證非線性的獲得,對變換後的滿足均值為0方差為1的x又進行了scale加上shift操作(y=scale*x+shift),每個神經元增加了兩個引數scale和shift引數,這兩個引數是通過訓練學習到的,意思是通過scale和shift把這個值從標準正態分佈左移或者右移一點並長胖一點或者變瘦一點,每個例項挪動的程度不一樣,這樣等價於非線性函式的值從正中心周圍的線性區往非線性區動了動。
Batch Normalization的優點:
Batch Normalization就是通過一定的規範化手段,把線性變換後得到的值的分佈強行拉回到均值為0方差為1的標準正態分佈,這樣使得這些值落在非線性函式中對輸入比較敏感的區域,這樣輸入值的小變化就會導致損失函式較大的變化,梯度就會變大,避免梯度消失的問題。而且梯度變大意味著學習收斂速度快,能大大加快訓練速度;
對於深層的神經網路,每一層都使用Batch Normalization就可以使得不同層的權重變化整體步調更一致,這樣可以使用更高的學習率,加快訓練速度;
Batch Normalization可以防止過擬合。因此如果我們用了Batch Normalization,此時就可以移除或使用較低的dropout,降低L2權重衰減係數等防止過擬合的手段。論文中最後的模型分別使用10%、5%和0%的dropout訓練模型,與之前的40%-50%相比,可以大大提高訓練速度。
輸入的標準化處理Normalizing inputs和隱藏層的標準化處理Batch Normalization是有區別的:
Normalizing inputs使所有輸入資料的均值為0,方差為1。而Batch Normalization可使各隱藏層輸入的均值和方差為任意值(因為Batch Normalization進行轉換後還會進行y=scale*x+shift操作)。
Tensorflow實現Batch Normalization:
程式碼如下:
import tensorflow as tf
import tqdm
import matplotlib.pyplot as plt
import os
from tensorflow.examples.tutorials.mnist import input_data
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
X = tf.placeholder(tf.float32, shape=[None, 784])
Y = tf.placeholder(tf.float32, shape=[None, 10])
# dropout比率
KEEP_PROB = tf.placeholder(tf.float32)
# 是否在訓練階段
IS_TRAINING = tf.placeholder(tf.bool)
USE_BN = tf.placeholder(tf.bool)
iteration = 3000
# 定義4個全連線層的變數,這是一個4層的全連線神經網路
w_1 = tf.Variable(tf.random_normal([784, 300]))
b_1 = tf.Variable(tf.constant(0.1, shape=[300]))
w_2 = tf.Variable(tf.random_normal([300, 100]))
b_2 = tf.Variable(tf.constant(0.1, shape=[100]))
w_3 = tf.Variable(tf.random_normal([100, 100]))
b_3 = tf.Variable(tf.constant(0.1, shape=[100]))
w_4 = tf.Variable(tf.random_normal([100, 10]))
b_4 = tf.Variable(tf.constant(0.1, shape=[10]))
# 定義第1層、第2層、第3層中的BN過程中的beta和gamma變數
gamma_1 = tf.Variable(tf.ones([300]))
beta_1 = tf.Variable(tf.zeros([300]))
gamma_2 = tf.Variable(tf.ones([100]))
beta_2 = tf.Variable(tf.zeros([100]))
gamma_3 = tf.Variable(tf.ones([100]))
beta_3 = tf.Variable(tf.zeros([100]))
# BN函式
def batch_norm(x, gamma, beta, is_training, use_bn, decay=0.99, eps=1e-3):
# 先判斷要不要用BN,再判斷目前使用BN是在訓練階段還是測試階段
if use_bn is False:
return x
# 求一個批樣本的平均值和方差
batch_mean, batch_var = tf.nn.moments(x, [0, 1])
# tf.train.ExponentialMovingAverage實現滑動平均模型,它使用指數衰減來計算變數的移動平均值。
# decay是衰減率。在建立ExponentialMovingAverage物件時,需指定衰減率(decay),用於控制模型的更新速度。
# ExponentialMovingAverage對每一個待更新訓練學習的變數/variable都會維護一個影子變數/shadow variable
# 影子變數的初始值與訓練變數的初始值相同。當執行變數更新時,每個影子變數都會更新為:
# shadow variable=decay∗shadow variable+(1−decay)∗variable
ema = tf.train.ExponentialMovingAverage(decay=decay)
def mean_var_with_update():
# 這裡的[batch_mean, batch_var]就是影子變數
# ema_apply_op = ema.apply([next1,next2,nex3...]),這裡傳入的[next1,next2,nex3...]是一個變數列表,可以同時計算多個加權平均數
# total1 = a * total1 + (1 - a) * next1, total2 = a * total2 + (1 - a) * next2
ema_apply_op = ema.apply([batch_mean, batch_var])
# tf.control_dependencies()給圖中的某些計算指定順序,與tf.identity配合使用的話,可以達到這樣的效果:
# 先執行ema_apply_op更新了batch_mean, batch_var變數後,用tf.identity(batch_mean)將更新後的batch_mean值取出
with tf.control_dependencies([ema_apply_op]):
return tf.identity(batch_mean), tf.identity(batch_var)
# tf.cond相當於一個三目運算子,如果is_training為True,則取mean_var_with_update的結果,否則取後面lambda的結果
# 需要注意的是在執行時後面兩種結果都被計算出來了,只是我們選擇取哪種結果繼續下面的運算
mean, var = tf.cond(is_training, mean_var_with_update, lambda: (ema.average(batch_mean), ema.average(batch_var)))
# 對x進行批標準化
normed = tf.nn.batch_normalization(x, mean, var, beta, gamma, eps)
return normed
# 定義cnn模型
def model(x, y, keep_prob, is_training, use_bn):
# 定義了一個4層的全連線神經網路
layer1_out = tf.add(tf.matmul(x, w_1), b_1)
layer1_out = batch_norm(layer1_out, gamma_1, beta_1, is_training, use_bn)
layer1_out_activation = tf.nn.relu(layer1_out)
layer1_out_dropout = tf.nn.dropout(layer1_out_activation, keep_prob)
layer2_out = tf.add(tf.matmul(layer1_out_dropout, w_2), b_2)
layer2_out = batch_norm(layer2_out, gamma_2, beta_2, is_training, use_bn)
layer2_out_activation = tf.nn.relu(layer2_out)
layer2_out_dropout = tf.nn.dropout(layer2_out_activation, keep_prob)
layer3_out = tf.add(tf.matmul(layer2_out_dropout, w_3), b_3)
layer3_out = batch_norm(layer3_out, gamma_3, beta_3, is_training, use_bn)
layer3_out_activation = tf.nn.relu(layer3_out)
layer3_out_dropout = tf.nn.dropout(layer3_out_activation, keep_prob)
layer_out = tf.nn.softmax(tf.add(tf.matmul(layer3_out_dropout, w_4), b_4))
cost = tf.reduce_mean(-tf.reduce_sum(y * tf.log(layer_out)))
optimizer = tf.train.AdamOptimizer(learning_rate=0.002).minimize(cost)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(layer_out, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return cost, optimizer, accuracy
loss, op, acc = model(X, Y, KEEP_PROB, IS_TRAINING, USE_BN)
tf.set_random_seed(1)
bn_acc_record = []
bn_acc_step = []
total_average_bn_loss_step = []
total_average_bn_loss = []
# 迭代訓練2000次,記錄使用了BN時的loss和acc
with tf.Session() as sess_bn:
sess_bn.run(tf.global_variables_initializer())
total_bn_loss = 0
# tqdm包可以將訓練過程像進度條一樣顯示出來,並且可顯示已用時間/剩餘時間
for i in tqdm.tqdm(range(iteration)):
train_batch_x_data, train_batch_y_data = mnist.train.next_batch(64)
bn_loss, _ = sess_bn.run([loss, op],
feed_dict={X: train_batch_x_data, Y: train_batch_y_data, KEEP_PROB: 0.8,
IS_TRAINING: True, USE_BN: True})
total_bn_loss += bn_loss
if i > 100:
total_average_bn_loss_step.append(i)
total_average_bn_loss.append(total_bn_loss / (i + 1))
if i % 50 == 0:
test_batch_x_data, test_batch_y_data = mnist.test.next_batch(64)
bn_acc = sess_bn.run([acc],
feed_dict={X: test_batch_x_data, Y: test_batch_y_data, KEEP_PROB: 1.0,
IS_TRAINING: False, USE_BN: True})
bn_acc_step.append(i)
bn_acc_record.append(bn_acc[0])
# 為了讓兩個模型更具有可比性,將其tf變數種子設成一樣,這樣它們初始化時的值一樣
tf.set_random_seed(1)
no_bn_acc_record = []
no_bn_acc_step = []
total_average_no_bn_loss_step = []
total_average_no_bn_loss = []
# 迭代訓練2000次,記錄不使用BN時的loss和acc
with tf.Session() as sess_no_bn:
sess_no_bn.run(tf.global_variables_initializer())
total_no_bn_loss = 0
for i in tqdm.tqdm(range(iteration)):
train_batch_x_data, train_batch_y_data = mnist.train.next_batch(64)
no_bn_loss, _ = sess_no_bn.run([loss, op],
feed_dict={X: train_batch_x_data, Y: train_batch_y_data, KEEP_PROB: 0.8,
IS_TRAINING: True, USE_BN: False})
total_no_bn_loss += no_bn_loss
if i > 100:
total_average_no_bn_loss_step.append(i)
total_average_no_bn_loss.append(total_bn_loss / (i + 1))
if i % 50 == 0:
test_batch_x_data, test_batch_y_data = mnist.test.next_batch(64)
no_bn_acc = sess_no_bn.run([acc],
feed_dict={X: test_batch_x_data, Y: test_batch_y_data, KEEP_PROB: 1.0,
IS_TRAINING: False, USE_BN: False})
no_bn_acc_step.append(i)
no_bn_acc_record.append(no_bn_acc[0])
# 將使用和不使用BN時的loss變化和acc變化畫成圖做對比
fig, ax = plt.subplots(1, 2, figsize=(12, 8))
ax[0].set(title='total average loss')
ax[1].set(title='acc')
ax[0].plot(total_average_bn_loss_step, total_average_bn_loss, '-', color='red', label=r'$bn\_loss$')
ax[0].plot(total_average_no_bn_loss_step, total_average_no_bn_loss, '-', color='blue', label=r'$no\_bn\_loss$')
ax[0].legend(loc="upper right")
ax[1].plot(bn_acc_step, bn_acc_record, '-', color='red', label=r'$bn\_acc$')
ax[1].plot(no_bn_acc_step, no_bn_acc_record, '-', color='blue', label=r'$no\_bn\_loss$')
ax[1].legend(loc="upper right")
plt.show()
plt.close()這個模型使用mnist為訓練資料,模型是一個4層的全連線神經網路,我們在每個神經層使用BN和每個神經層不使用BN各訓練3000次,觀察這個過程中total average loss的變化和acc的變化。
執行結果如下:
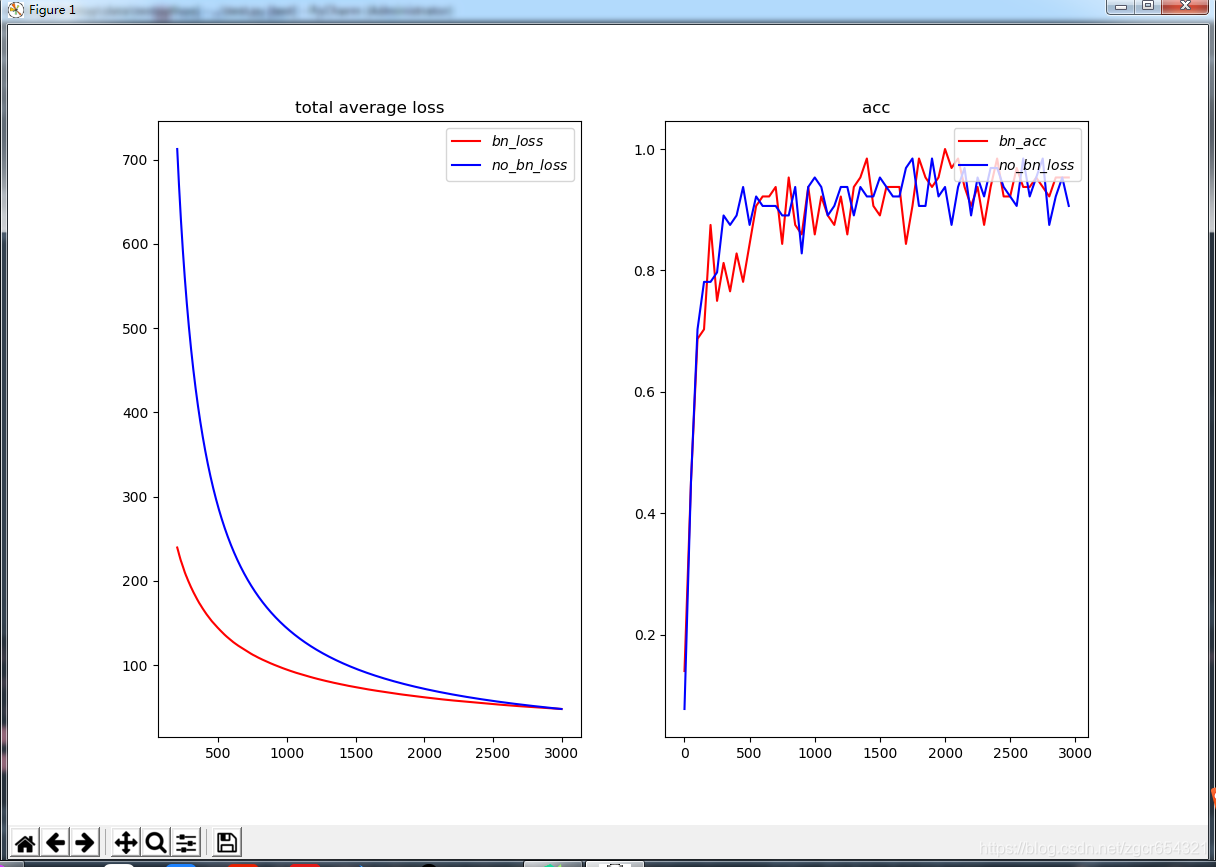
我們可以看到使用了BN後的模型loss值下降的更快,模型訓練的速度加快了。