
MySQL資料庫水平分表策略--一致性hash
阿新 • • 發佈:2018-12-24
一致性hash演算法緣起
一致性雜湊演算法在1997年由麻省理工學院提出的一種分散式雜湊(DHT)實現演算法,設計目標是為了解決因特網中的熱點(Hot spot)問題,初衷和CARP十分類似。一致性雜湊修正了CARP使用的簡 單雜湊演算法帶來的問題,使得分散式雜湊(DHT)可以在P2P環境中真正得到應用。
一致性hash演算法提出了在動態變化的Cache環境中,判定雜湊演算法好壞的四個定義:
1. 平衡性(Balance): 平衡性是指雜湊的結果能夠儘可能分佈到所有的緩衝中去,這樣可以使得所有的緩衝空間都得到利用。很多雜湊演算法都能夠滿足這一條件。 2. 單調性(Monotonicity): 單調性是指如果已經有一些內容通過雜湊分派到了相應的緩衝中,又有新的緩衝加入到系統中。雜湊的結果應能夠保證原有已分配的內容可以被對映到原有的或者新的緩衝中去,而不會被對映到舊的緩衝集合中的其他緩衝區。 3. 分散性(Spread): 在分散式環境中,終端有可能看不到所有的緩衝,而是隻能看到其中的一部分。當終端希望通過雜湊過程將內容對映到緩衝上時,由於不同終端所見的緩衝範圍有可能不同,從而導致雜湊的結果不一致,最終的結果是相同的內容被不同的終端對映到不同的緩衝區中。這種情況顯然是應該避免的,因為它導致相同內容被儲存到不同緩衝中去,降低了系統儲存的效率。分散性的定義就是上述情況發生的嚴重程度。好的雜湊演算法應能夠儘量避免不一致的情況發生,也就是儘量降低分散性。 4. 負載(Load): 負載問題實際上是從另一個角度看待分散性問題。既然不同的終端可能將相同的內容對映到不同的緩衝區中,那麼對於一個特定的緩衝區而言,也可能被不同的使用者對映為不同 的內容。與分散性一樣,這種情況也是應當避免的,因此好的雜湊演算法應能夠儘量降低緩衝的負荷。
在分散式叢集中,對機器的新增刪除,或者機器故障後自動脫離叢集這些操作是分散式叢集管理最基本的功能。如果採用常用的hash(object)%N演算法,那麼在有機器新增或者刪除後,很多原有的資料就無法找到了,這樣嚴重的違反了單調性原則。
一致性hash演算法介紹
一致性雜湊是一種特殊的雜湊方式。傳統的雜湊方式在當節點數目發生變化時,會引起大量的資料遷移,而使用一致性雜湊則不會產生這種問題。一致性雜湊最早是一個分散式快取(Distributed Caching)系統的放置演算法(現在很熱門的Memcached就用的是一致性雜湊)。但是現在它已經被廣泛應用到了其它各個領域。對於任何一個雜湊函式,其輸出值都有一個取值範圍,我們可以將這個取值區間畫成一個環,如下圖所示:
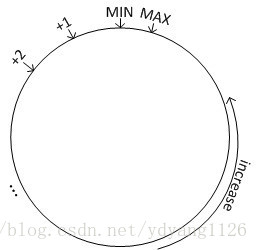
通過雜湊函式,每個節點都會被分配到環上的一個位置,每個鍵值也會被對映到環上的一個位置。這個鍵值最終被放置在距離該它的位置最近的,且位置編號大於等於該值的節點上面,即放置到順時針的下一個節點上面。下圖形象的表示了這種放置方案,其中Node 0上面放置Range 0上面的資料,以此類推。
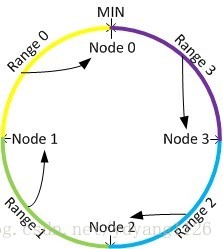
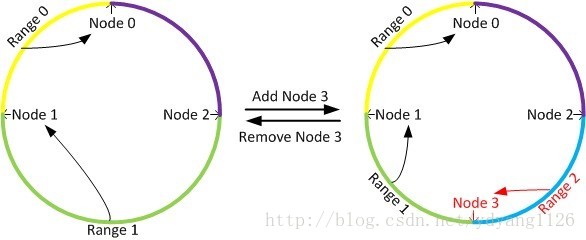
由於採用的雜湊函式通常是與輸入無關的均勻函式,因此當鍵值和節點都非常的多的時候,一致性雜湊可以達到很好的分散式均勻性。並且由於特殊的放置規則,一致性雜湊在節點資料發生變動時可以將影響控制在區域性區間內,從而保證非常少的資料遷移(接近理論上的最小值)。當增加一個節點時,只有這個節點所在的區間內的資料需要被重新劃分,如下圖中,只需要將range 2上面的資料會從node 1中遷移到node 3上面。當刪除一個節點時,只需要將這個節點上面的資料遷移到下一個節點上面,比如刪除node 3,只把range 2上面的資料遷移到node 1上面就可以並,而其它的資料是不需要遷移變動的。
一致性雜湊有非常廣泛的應用,Key-Value系統,文件資料庫或者分散式關係資料庫都可以使用。Amazon的NoSQL系統Dynamo應用採用的就是一種改進的一致性雜湊演算法。在這個系統中又引入了虛擬節點的概念,使得這個演算法的load balance更加的好,並且同時考慮了複製技術。環上的點就變成了虛擬節點,然後再採用其它的方式將這些虛擬節點對映到實際的物理節點上面去。這使得系統有很好的可擴充套件性和可用性。