
大眾點評運維架構的圖文詳解(全面前沿)
今天分享專題大綱如圖所示,從5個方面跟大家一起探討:

1、點評運維團隊的配置
目前我們運維分為4個組,相信跟大部分公司一樣,運維團隊分為:應用運維、系統運維、運維開發和監控運維,當然還有DBA團隊和安全團隊,這裡就不一一羅列了。整個運維團隊全算上目前是不到40人規模。
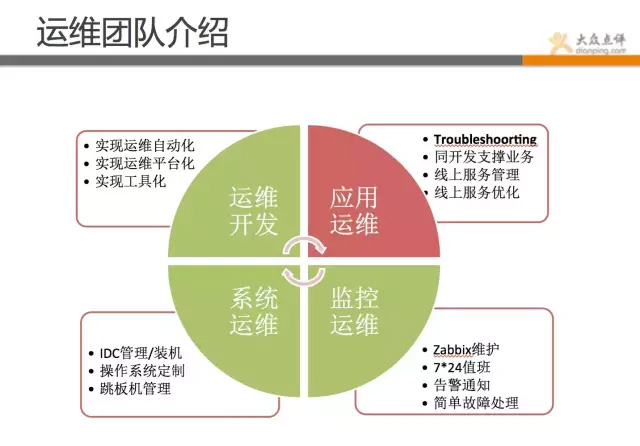
我們團隊分工是這樣的:
-
應用運維:負責支援線上業務,各自會負責對應的業務線,主要職能是保證線上業務穩定性和同開發共同支撐對應業務,以及線上服務管理和持續優化。
-
運維開發:幫助運維提升工作效率,開發方便快捷的工具,實現運維平臺化自動化。
-
系統運維:負責作業系統定製和優化,IDC管理和機器交付,以及跳板機和賬號資訊管理。
-
監控運維:負責發現故障,並第一時間通知相關人員,及時處理簡單故障和啟動降級方案等。
2、點評的整體架構
先看下點評的機房情況。
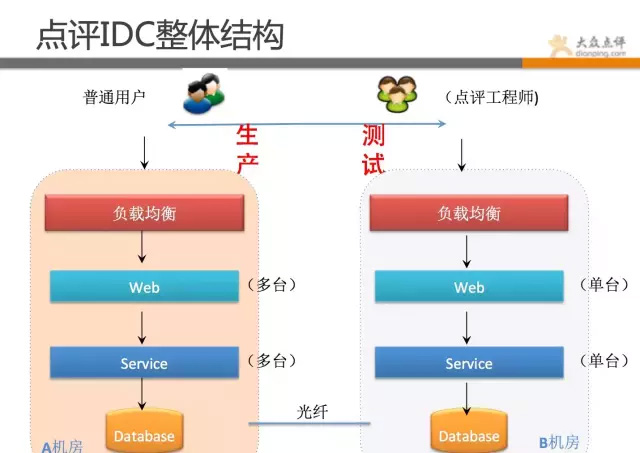
點評目前是雙機房結構,A機房主跑線上業務,B機房跑測試環境和大資料處理作業,有hadoop叢集、日誌備份、災備降級應用(在建)等。點評目前機房物理機+虛擬機器有近萬臺機器。
點評的整體架構,還是跟多數換聯網公司一樣,採用多級分層模式,我們繼續來詳細看下點評整體架構。
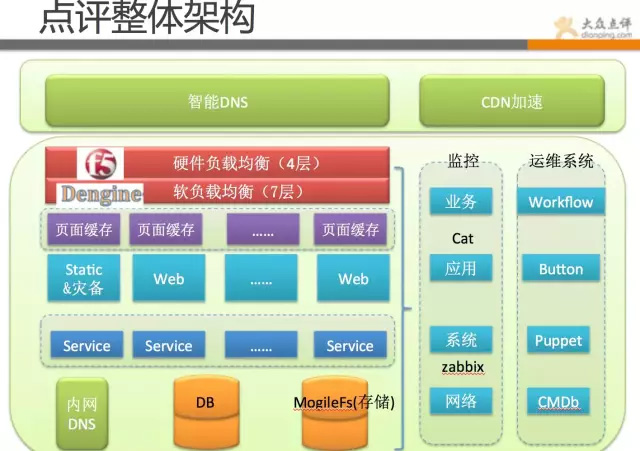
上面這幅圖基本概括了點評的整體架構環境:
-
使用者引導層用的是第三方的智慧DNS+CDN。
-
負載均衡首先是F5做的4層負載均衡 之後是dengine做的7層負載均衡(Dengine是在tengine基礎上做了二次開發)。再往後是varnish做的頁面快取 之後請求到web端 web端通過內部協議呼叫service(RPC)。
-
圖片儲存用的是mogileFS分散式儲存 。
-
所有業務,全部有高可用方案,應用全部是至少2臺以上。
-
當然,具體業務要複雜很多,這裡只是抽象出簡單層面,方便各位同學理解。
目前,點評運維監控是從4個維度來做的:
-
業務層面,如團購業務每秒訪問數,團購券每秒驗券數,每分鐘支付、建立訂單等(cat)。
-
應用層面,每個應用的錯誤數,呼叫過程,訪問的平均耗時,最大耗時,95線等(cat)。
-
系統資源層面:如cpu、記憶體、swap、磁碟、load、主程序存活等 (zabbix)。
-
網路層面: 如丟包、ping存活、流量、tcp連線數等(zabbix cat)。
3、點評運維繫統介紹
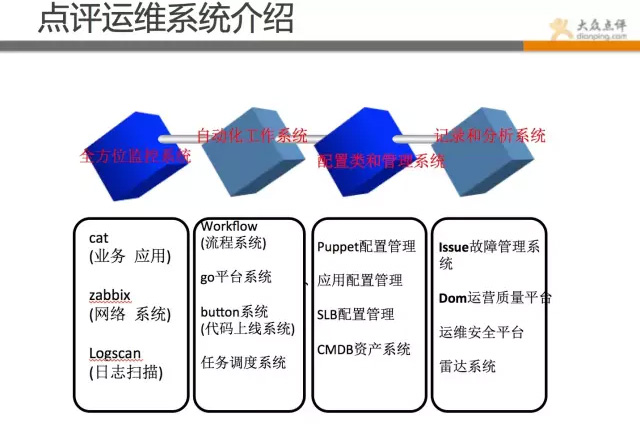
點評的運維和平臺架構組做了很多實用的工具,這些工具組成了點評的整體運維體系。
目前自動化運維比較熱,但自動化運維個人覺得是一種指導思想,沒必要硬造概念和生搬硬套。自動化在很多公司百花齊放,各家有各家的玩法。但不管怎麼定義,運維人員都必須從不同緯度去面對和解決企業所存在的問題。
點評在這方面,也是摸著石頭過河,我們的思路是先造零件,再整合,通過零件的打造和之間的整合,慢慢勾勒出一條適合自己的運維自動化框架。
我們運維的理念是:
-
能用程式幹活的,堅決程式化、平臺化;
-
能用管理解決的問題,不用技術解決;
-
同一個錯誤不能犯三次;
-
每次故障,都是學習和提升的機會;
-
每個人都要有產品化思維,做平臺產品讓開發走自助路線;
-
小的,單一的功能,組合起來完成複雜的操作(任務分解);
所以,我們將自己的理念,融入到自己的作品中,做出了很多工具。
首先整體做個說明,點評運維工具系統彙總:
-
全方位監控系統:覆蓋業務、應用、網路、系統等方面,做到任何問題,都可直觀反饋。對不同應用等級,做到不同監控策略和報警策略。
-
自動化工具系統:對重複的、容易出錯的、繁瑣的工作儘可能工具化,通過小的策略組合,完成大的任務。
-
配置和管理系統:對於複雜的配置管理,儘可能web化、標準化、簡單化,有模板定義,有規範遵循。
-
記錄和分析系統:對發生的問題和資料做記錄並分析,不斷的總結、完善和提升。
下面就跟大家來一一介紹下:
3.1 全方位監控系統
Zabbix大家應該非常熟悉了,這裡就不做介紹,主要介紹下cat監控。
-
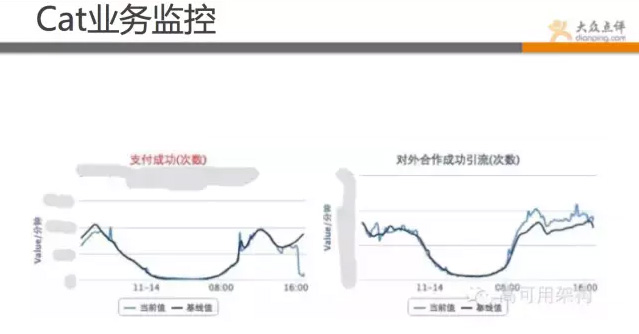
業務監控:
這張是cat的應用監控圖表,可直觀從業務角度看出問題,可跟基線的對比,發現問題所在。如圖所示,此時支付遠偏離基線,流量正常,可能後端出了問題。
除了這些,還有建立訂單、支付、首頁訪問、手機訪問等業務資料。
這張圖是從業務角度來監控的。

這張也是從業務層面來監控的,該圖展示的是手機的訪問量趨勢圖,下面包括延遲、成功率、連結型別、運營商等都有明確資料,該監控可全方位覆蓋業務。

-
應用監控:
從業務層面往下,就是應用層面。
應用狀態大盤可清晰表示當前業務元件狀態,如果某個業務不可用,其下面某個應用大量報錯,說明可能是該應用導致。
該監控大盤十分清晰明的能展示業務下面的應用狀態,可在某業務或者某域名打不開的時候,第一時間找出源頭。
下圖為應用報錯大盤,出問題的應用會實時登榜(每秒都會重新整理資料),當出現大故障時,運維人員可一眼看出問題;而當多個不同業務同時報錯時,則可能是公共基礎服務出了問題。

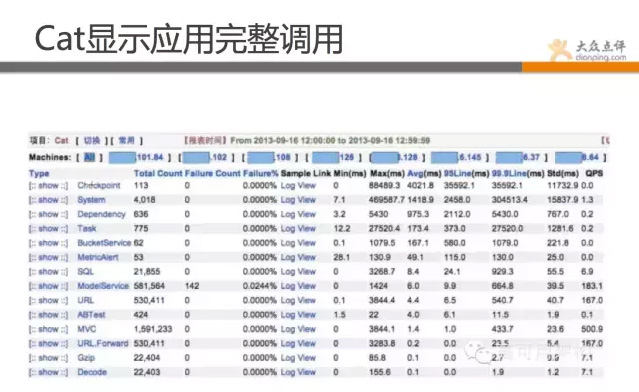
再看下圖的這個功能,是Cat最強大的功能,能完整顯示應用之間呼叫過程,做了什麼事情,請求了那些,用了多長時間,成功率是多少,訪問量是多大,盡收眼底。 Cat幾乎無死角的覆蓋到業務和應用層面的監控,當然還可做網路等層面監控,總之非常強大。這也是點評的鷹眼系統。
-
Logscan日誌掃描工具:
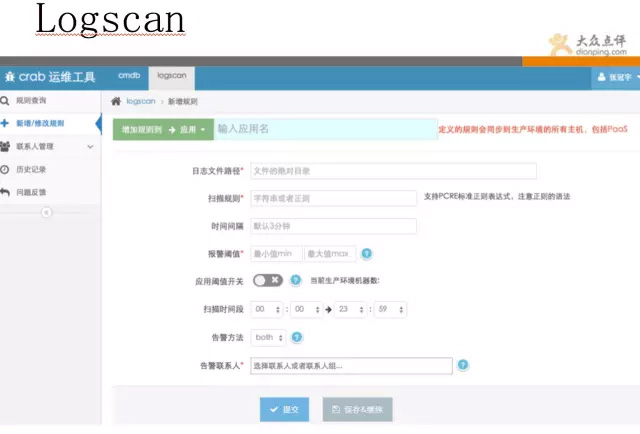
Logscan系統,是一套日誌掃描工具,可根據你定義的策略,對日誌內容進行定時掃描,該工具可覆蓋到基於日誌內容的檢測,結合zabbix和cat,實現無死角覆蓋。 比如有一些攻擊的請求,一直遍歷你的url,通過cat、zabbix等都無法靈活捕獲,有了日誌掃描,便可輕鬆發現。
3.2 自動化工作系統
首先介紹下點評的流程系統-workflow系統
顧名思義workflow是一套流程系統,其核心思想是把線上所有的變更以標準化流程的方式,梳理出來。
我們遵循一個理念,能用程式跑,就不去人操作。
流程有不同狀態的轉化,分別為發起、審計、執行、驗證等環節。使用者可自行發起自己的需求變更,通過運維稽核,操作(大部分是自動的),驗證。 如擴容、上線、dump記憶體、封IP等都為自動化流程。
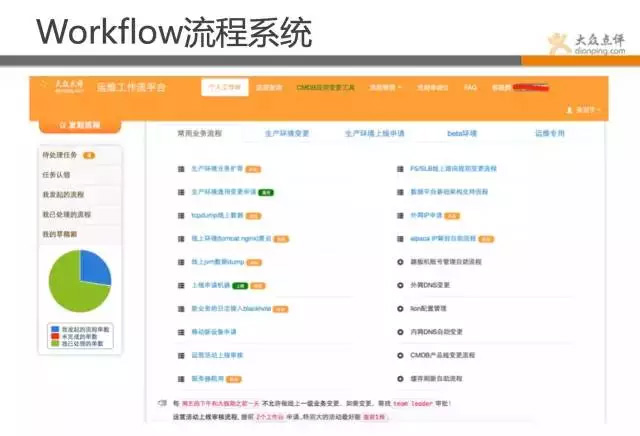
以我們線上自動化擴容流程為展示,使用者使用時,需要填寫對應資訊,提交後,運維在後臺稽核過後,就完全自動化擴容,擴容完成會有郵件通知,全程運維不需要登入伺服器操作。(自動化倒不是太複雜的技術難題,通過小的任務組合,設定好策略即可). 幾十臺機器的擴容,運維只需點個稽核通過按鈕,數分鐘而已。
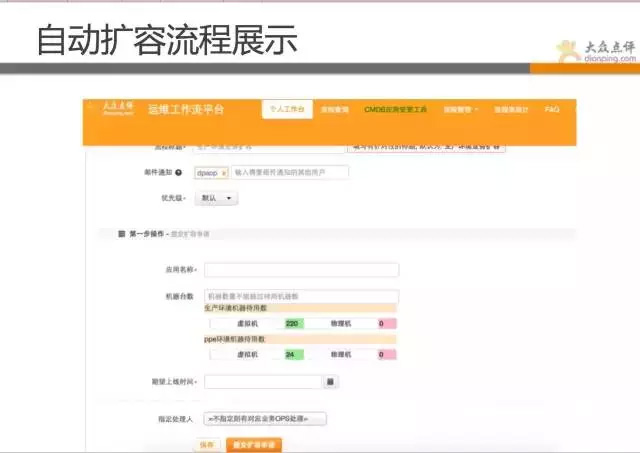
經過長時間的推廣,點評現在98%以上變更都是通過工作流平臺完成的,所有變更全部有記錄,做到出問題時 有法可依,違法可糾。
而且通過流程單的使用頻率,可做資料分析,瞭解哪些操作比較頻繁,能否自動化掉,是否還有優化空間。 這才是做平臺的意義,以使用者為導向。
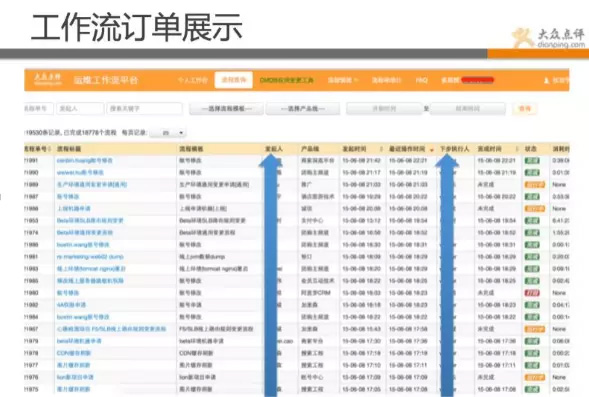
流程系統就介紹到這裡,朋友們可關注下其中核心思想。
下面介紹另一套重量級核心系統:Button系統
Button是一套程式碼管理、打包、部署上線系統,開發可完全自主化進行上傳程式碼,自動化測試,打包,預發,灰度上線,全部上線,問題回滾等操作。 全程運維不用幹預,完全平臺自主化。

點評的運維,除了有些沒法自動化的手動配置下,其他基本都是開發自助。 這就是自動化的威力!
Go平臺系統,是一套運維作業系統,其中包含了很多常規操作、如批量重啟、降級、切換、上下線、狀態檢測等。
該系統主要是解決運維水平參差不齊,工具又各有各的用法,比如說批量重啟操作,有用ssh、有用fabric、有自己寫shell指令碼的。 乾脆直接統一,進行規範,定義出來操作,通過平臺化進行標準化。 由於長時間不出問題,偶爾出一下,運維長時間不操作,找個批量重啟指令碼還要找半天。 哪些不能自動化的,我們基本都做到go裡了,在這裡基本都是一鍵式的傻瓜操作了。
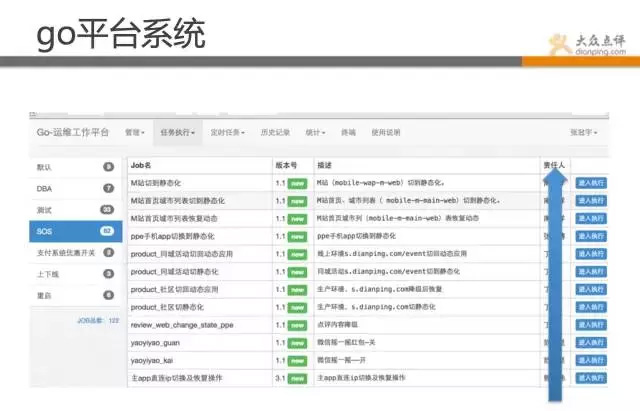
現在,我們監控團隊就可以靈活操作,不需要有多高的技術含量,並且每次操作都有記錄,做好審計和授權。
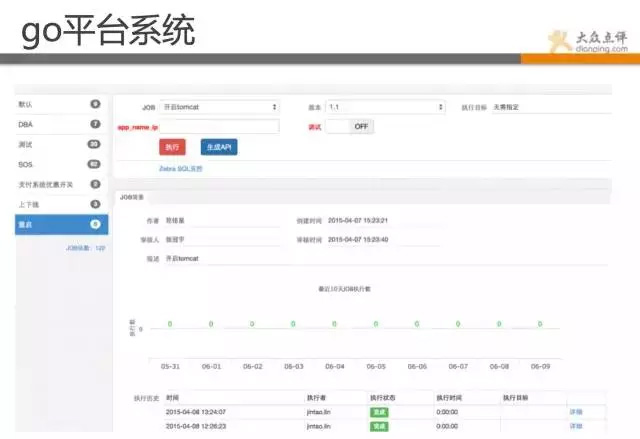
所有後臺基本都是python、shell指令碼實現,小的指令碼組再整合成任務,這也是我們的重要理念之一。 對於比較複雜的任務,我們進行分解,然後用小的,單一的功能,組合起來完成複雜的操作(任務分解)。 其實我們實現自動化也是這個思路,先造零件,再拼裝。
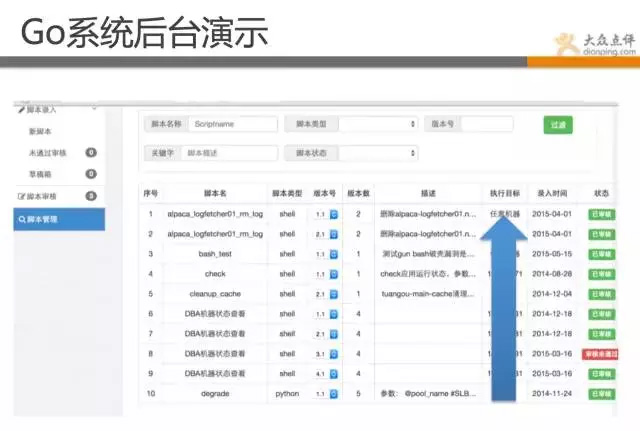
儘管有了puppet,go等工具,但對於一些job作業的管理,也顯得非常吃力,我們架構組的同學做出一套任務排程系統。相當於分散式的crontab,並且有強大的管理端。 完全自主化管理,只需要定義你需要跑的job,你的策略,就完全不用管了。會自動去做,並且狀態彙報、監控、等等全部都有記錄,並實現完全自助化。
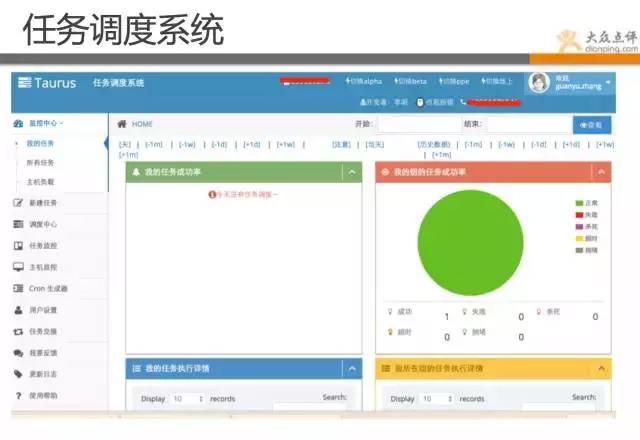

以上這些系統都非常注重體驗,都有非常詳細的資料統計和分析,每過一段時間,都有人去看,不斷改進和優化,真正做到產品自運營。還有一些自動化系統就不一一介紹了。
3.3 配置和管理系統
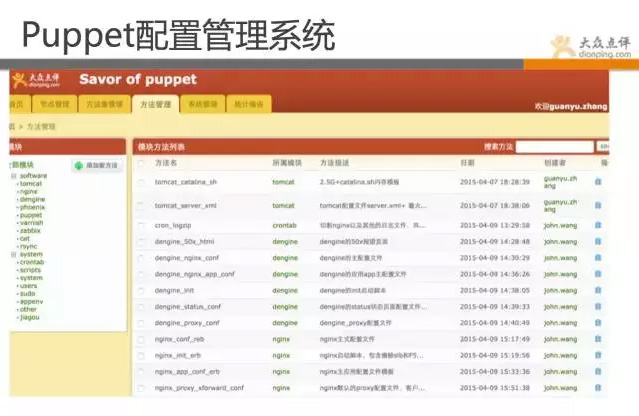
先介紹下puppet管理系統,相信不少同學對puppet語法格式深惡痛絕,並且也領教過一旦改錯造成的故障嚴重性。
而且隨著多人協同工作後,模板和檔案命名千奇百怪,無法識別。
針對這些問題,點評就做了一套管理工具,主要是針對puppet語法進行解析,實現web化管理,並進行規範化約束。
跟go系統一樣的想法,將puppet中模組進行組合,組合成模組集(方法集),可方便識別和靈活管理。
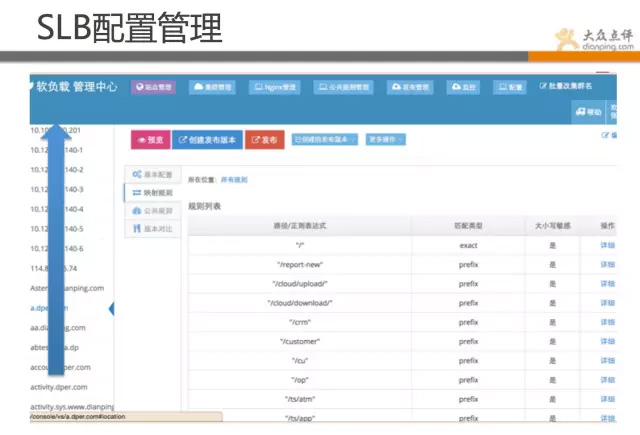
下面展示的是我們的軟負載均衡管理頁面,該系統是線上SLB的管理系統。 其核心在於把nginx語法通過xml進行解析,實現web化管理,傻瓜式配置,規範化配置,避免誤操作,版本控制,故障回滾等。
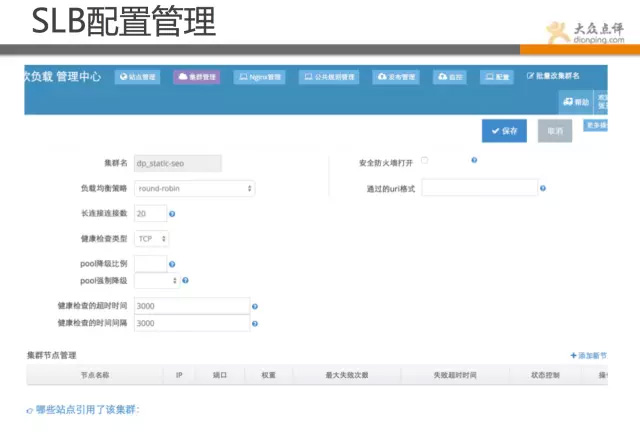
點評系統很多,基本上遇到個痛點,都會有人想辦法把痛點解決。
下面就介紹下點評另一套強大配置系統,lion。
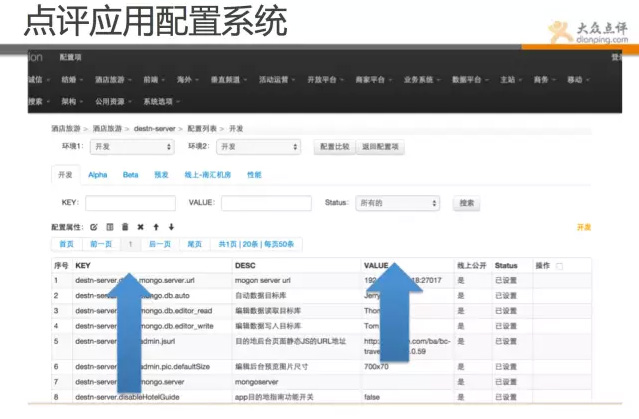
Lion是一套應用配置管理系統,點評的所有應用用到的配置,不在本地文字檔案儲存,都在一個單獨系統儲存,儲存以key/value的方式儲存。並且也是完全平臺化,運維負責做好許可權控制和審計。開發全部自助。
其核心是用了zookeeper的管理機制,將配置資訊儲存在 Zookeeper 的某個目錄節點中,然後將所有需要修改的應用機器監控配置資訊的狀態,一旦配置資訊發生變化,每臺應用機器就會收到 Zookeeper 的通知,然後從 Zookeeper 獲取新的配置資訊應用到系統中。
是不是在點評做運維輕鬆很多?各種操作都工具化,自助化,自動化了。那運維還需要做什麼。
3.4 記錄和分析系統
此類系統雖然不怎麼起眼,但對我們幫助也是特別大的,我們通過一些系統的資料記錄和分析,發現了不少問題,也解決不少潛在問題,更重要的是,在這個不斷完善總結的過程中,學習到了很多東西。
這個是我們故障分析系統,所有的故障都會做記錄,故障結束後都會case by case的進行深入分析和總結。其實以上很多系統,都是從這些記錄中總結出來的。

該系統為故障記錄系統,每個故障都有發生的緣由和改進的方案,定期有人review。
運維起來很輕鬆嗎?也不輕鬆,只是工作重點有了轉移,避開了那些重複繁瑣的工作,和開發同學深度結合,共同注重運營質量和持續優化。
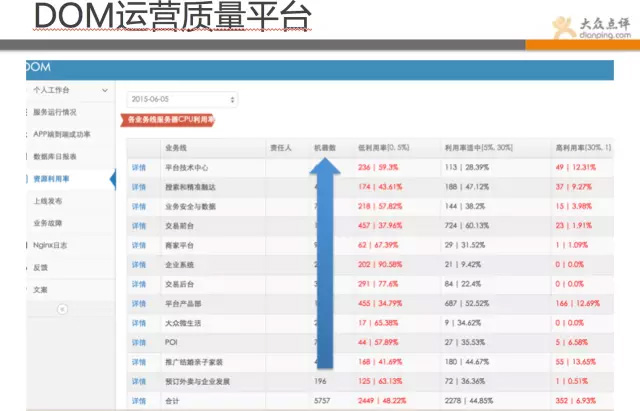
再來看下圖所示是點評的DOM系統,即運營質量管理平臺,該平臺彙總了線上的伺服器狀態、應用響應質量、資源利用率、業務故障等全方位的資料彙總平臺。
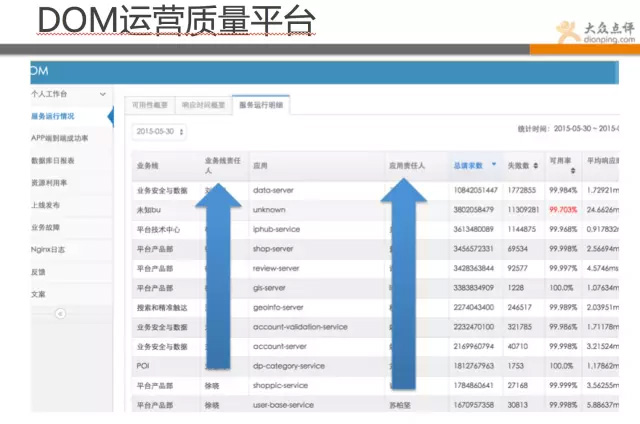
並通過同比和環比,以及平均指標等資料,讓各開發團隊進行平臺化PK,效能差的運維會去推動改進。
最後一個需要介紹的是雷達系統,該系統是我們最近在做的,一個比較高大上的專案。
朋友們也感受到了,我們系統之多,出問題查起來也比較費時。 不少同學生產環節也遇到過類似問題,出了問題到底是什麼鬼?到底哪一塊引起的呢? 結合這個問題,我們把線上的問題做了個分類,並給了一些策略層面的演算法,能快速顯示。 可讓故障有個上下文的聯絡,如:上線時間、請求數下降、錯誤數增多等,哪個先出現,哪個後出現? 當然,這塊功能還在做,目標是實現 出問題的時候,一眼就能從雷達系統定位問題型別和範圍。
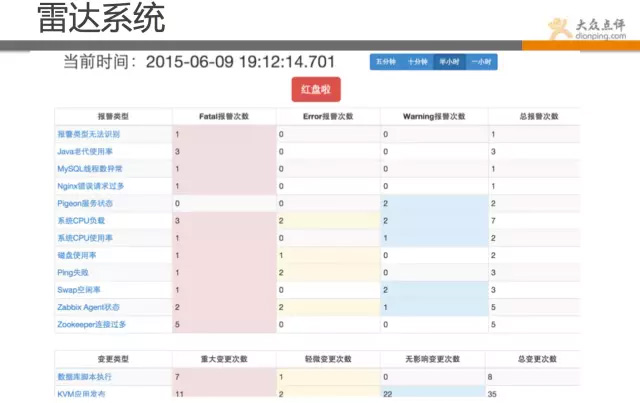
以上向大家演示的就是點評的運維繫統,相信我們點評的運維思想都在裡面體現了。
運維點評這幾年的發展,主要目標是實現平臺規範化、運維高效化、開發自主化 。
之前也是通過運維root登入,然後寫指令碼批量跑命令的低效運維。也經歷過CMDB系統資訊不準確,上線資訊錯亂的尷尬局面。也遇到過出了很大問題,運維忙來忙去,找不到rootcase。
好在,通過努力,這些問題現在都有了很大改觀,相信朋友們通過展示的系統,能感覺出點評運維的進步。
4、運維踩過的坑和改進的地方
我就這些年,點評運維出的一些case案例,跟大家聊一聊我們做了哪些具體工作:
-
變更不知道誰做的,無法恢復,變更完也找不到根據,造成重大故障。//之前線上puppet通過vim的管理方式,由於運維同學失誤推了一個錯誤配置,導致全部業務不可用1個小時,我們後面通過規範puppet配置修改並做成工具,進行許可權控制,還加了流程系統,進行避免。
-
出了問題,開發說程式碼沒問題,運維說環境沒問題,該找誰?//我們後面做了工具,通過DOM和cat系統,可進行深度診斷,基本很容易定位問題所屬。
-
執行了個錯誤命令,全線都變更了,導致服務不可用。//我們通過go系統,進行日常操作梳理,並做成工具,運維90%操作都可通過自動化流程和go平臺完成。大大縮減故障產生率,並且之後進行許可權回收。
-
出問題了,各種系統翻來查去,無法快速定位,找不到rootcase。//點評正在做雷達系統,就是將歷史存在的問題,進行復盤,將一些故障型別,進行分級,然後通過策略和演算法,在雷達系統上進行掃描,出問題環節可快速第一時間優先顯示。
-
運維天天忙成狗,還不出成績,天天被開發吐槽。//點評這兩年完全扭轉了局勢,現在是運維吊打開發,因為我們目前,大部分系統都實現了開發自助化,運維被解放出來,開始不斷完善平臺和關注業務運營質量,我們dom系統是可定製的,運維每天都把各業務的核心指標報表發到各位老大那裡,哪些服務質量差,響應慢,開發都會立即去改。(當然,需要老大們支援)。
5、未來關注的領域和方向
點評也有些前沿的關注點,比如比較熱的Paas技術。
PaaS和雲很熱,還有docker技術,點評也不能掉隊,目前點評有數千個docker的例項在跑線上的業務。
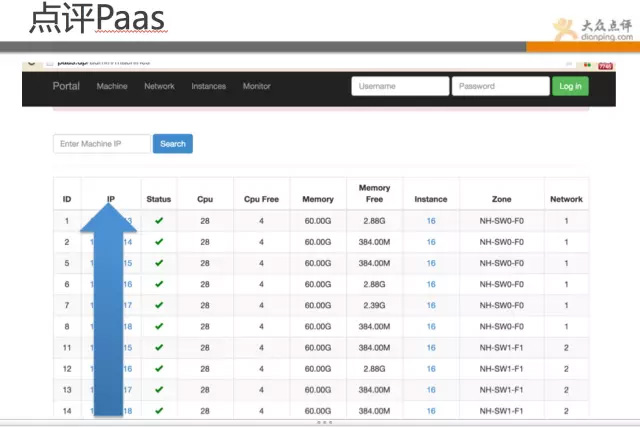
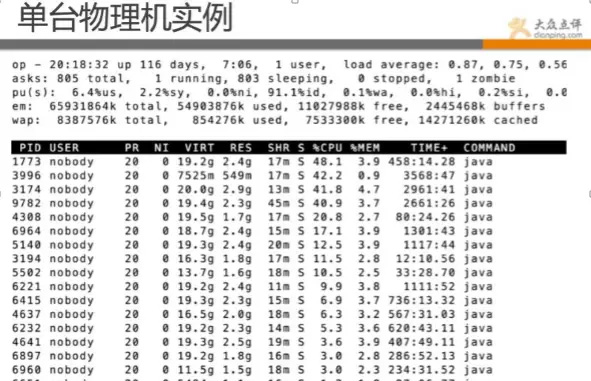
上圖java都是跑的docker例項
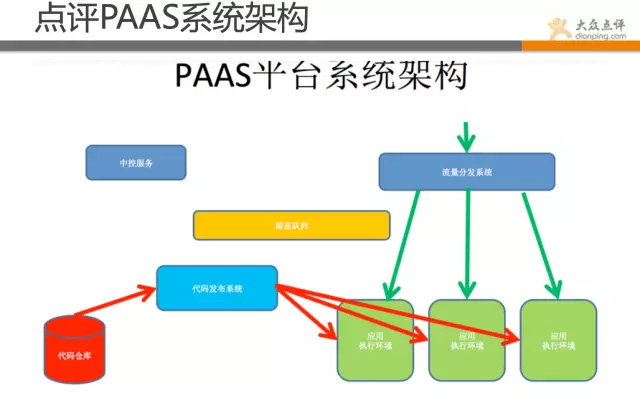
目前點評Docker這塊可做到10秒內快速部署業務並可響應使用者請求。30秒內可完成一次例項無縫遷移。 個人感覺docker技術不在於底層這塊,在於上層管理系統的構造。底層一方面是持續優化,挖掘效能,但更重要的是在策略層和排程層。 如何快速部署、遷移、恢復、降級、擴容等,做好這些還有不少挑戰。
點評這兩年成長很多,但需要走的路也很多,未來關注的點會在多系統的有機整合和新技術的嘗試以及發展,還會更多的關注智慧策略層面。
結束語
在最後結束時,感謝各位到場朋友捧場,也感謝點評運維和平臺架構的每一位同事,有了你們,點評運維才走到了今天,我們共同努力,來創造新時代的運維體系。
點評很多系統都是第一次拿出跟大家分享,大家可看一下設計理念和思想。
如何一起愉快地發展
這是一個新的時代!每個人都有自己的聲音,值得被尊重,並且有機會被尊重。
高效運維繫列微信群於2015年4月底建立,已然成為國內高階運維圈子,主力成員分佈甚廣,不僅來自網際網路大廠,更有包括移動、銀聯、農業等各產業朋友。“高效運維”公眾號值得您的關注。本公眾號基本上每天一篇文章(90%為原創),來自高效運維繫列群的討論精華,“高效運維”也是InfoQ專欄《高效運維最佳實踐》及運維2.0官方公眾號。
來吧朋友,共襄盛舉。
重要提示:如需轉載本文,請必須全文轉載,幷包括本行及如下二維碼。
