
影象後處理 降噪 增強
針對模糊影象的處理,個人覺得主要分兩條路,一種是自我激發型,另外一種屬於外部學習型。接下來我們一起學習這兩條路的具體方式。
第一種 自我激發型
基於影象處理的方法,如影象增強和影象復原,以及曾經很火的超解析度演算法。都是在不增加額外資訊的前提下的實現方式。
1. 影象增強
影象增強是影象預處理中非常重要且常用的一種方法,影象增強不考慮影象質量下降的原因,只是選擇地突出影象中感興趣的特徵,抑制其它不需要的特徵,主要目的就是提高影象的視覺效果。先上一張示例圖:

影象增強中常見的幾種具體處理方法為:
直方圖均衡
在影象處理中,影象直方圖表示了影象中畫素灰度值的分佈情況。為使影象變得清晰,增大反差,凸顯影象細節,通常希望影象灰度的分佈從暗到亮大致均勻。直方圖均衡就是把那些直方圖分佈不均勻的影象(如大部分畫素灰度集中分佈在某一段)經過一種函式變換,使之成一幅具有均勻灰度分佈的新影象,其灰度直方圖的動態範圍擴大。用於直方均衡化的變換函式不是統一的,它是輸入影象直方圖的積分,即累積分佈函式。
灰度變換
灰度變換可使影象動態範圍增大,對比度得到擴充套件,使影象清晰、特徵明顯,是影象增強的重要手段之一。它主要利用影象的點運算來修正畫素灰度,由輸入畫素點的灰度值確定相應輸出畫素點的灰度值,可以看作是“從畫素到畫素”的變換操作,不改變影象內的空間關係。畫素灰度級的改變是根據輸入影象f(x,y)灰度值和輸出影象g(x,y)灰度值之間的轉換函式g(x,y)=T[f(x,y)]進行的。
灰度變換包含的方法很多,如逆反處理、閾值變換、灰度拉伸、灰度切分、灰度級修正、動態範圍調整等。影象平滑
在空間域中進行平滑濾波技術主要用於消除影象中的噪聲,主要有鄰域平均法、中值濾波法等等。這種區域性平均的方法在削弱噪聲的同時,常常會帶來影象細節資訊的損失。
鄰域平均,也稱均值濾波,對於給定的影象f(x,y)中的每個畫素點(x,y),它所在鄰域S中所有M個畫素灰度值平均值為其濾波輸出,即用一畫素鄰域內所有畫素的灰度平均值來代替該畫素原來的灰度。
中值濾波,對於給定畫素點(x,y)所在領域S中的n個畫素值數值{f1,f2,…,fn},將它們按大小進行有序排列,位於中間位置的那個畫素數值稱為這n個數值的中值。某畫素點中值濾波後的輸出等於該畫素點鄰域中所有畫素灰度的中值。中值濾波是一種非線性濾波,運算簡單,實現方便,而且能較好的保護邊界。影象銳化
採集影象變得模糊的原因往往是影象受到了平均或者積分運算,因此,如果對其進行微分運算,就可以使邊緣等細節資訊變得清晰。這就是在空間域中的影象銳化處理,其的基本方法是對影象進行微分處理,並且將運算結果與原影象疊加。從頻域中來看,銳化或微分運算意味著對高頻分量的提升。常見的連續變數的微分運算有一階的梯度運算、二階的拉普拉斯運算元運算,它們分別對應離散變數的一階差分和二階差分運算。
2. 影象復原

其目標是對退化(傳播過程中的噪聲啊,大氣擾動啊好多原因)的影象進行處理,儘可能獲得未退化的原始影象。如果把退化過程當一個黑匣子(系統H),圖片經過這個系統變成了一個較爛的圖。這類原因可能是光學系統的像差或離焦、攝像系統與被攝物之間的相對運動、電子或光學系統的噪聲和介於攝像系統與被攝像物間的大氣湍流等。影象復原常用二種方法。當不知道影象本身的性質時,可以建立退化源的數學模型,然後施行復原演算法除去或減少退化源的影響。當有了關於影象本身的先驗知識時,可以建立原始影象的模型,然後在觀測到的退化影象中通過檢測原始影象而復原影象。
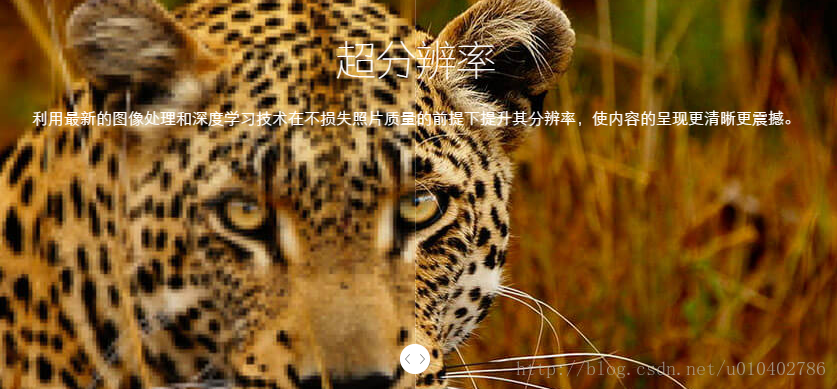
3. 影象超解析度
一張圖我們想腦補細節資訊好難,但是相似的多幅圖我們就能互相腦洞了。所以,我們可以通過一系列相似的低分辨圖來共同腦補出一張高清晰圖啊,有了這一張犯罪人的臉,我就可以畫通緝令了啊。。。
超解析度復原技術的目的就是要在提高影象質量的同時恢復成像系統截止頻率之外的資訊,重建高於系統解析度的影象。繼續說超分辨,它其實就是根據多幅低質量的圖片間的關係以及一些先驗知識來重構一個高分辨的圖片。示例圖如下:
第二種 外部學習型
外部學習型,就如同照葫蘆畫瓢一樣的道理。其演算法主要是深度學習中的卷積神經網路,我們在待處理資訊量不可擴充的前提下(即模糊的影象本身就未包含場景中的細節資訊),可以藉助海量的同類資料或相似資料訓練一個神經網路,然後讓神經網路獲得對影象內容進行理解、判斷和預測的功能,這時候,再把待處理的模糊影象輸入,神經網路就會自動為其新增細節,儘管這種新增僅僅是一種概率層面的預測,並非一定準確。
本文介紹一種在灰度影象復原成彩色RGB影象方面的代表性工作:《全域性和區域性影象的聯合端到端學習影象自動著色並且同時進行分類》。利用神經網路給黑白影象上色,使其變為彩色影象。稍作解釋,黑白影象,實際上只有一個通道的資訊,即灰度資訊。彩色影象,則為RGB影象(其他顏色空間不一一列舉,僅以RGB為例講解),有三個通道的資訊。彩色影象轉換為黑白影象極其簡單,屬於有失真壓縮資料;反之則很難,因為資料不會憑空增多。
搭建一個神經網路,給一張黑白影象,然後提供大量與其相同年代的彩色影象作為訓練資料(色調比較接近),然後輸入黑白影象,人工智慧按照之前的訓練結果為其上色,輸出彩色影象,先來看一張效果圖:

本文工作
• 使用者無干預的灰度影象著色方法。
• 一個新穎的端到端網路,聯合學習影象的全域性和區域性特徵。
• 一種利用分類標籤提高效能的學習方法。
• 基於利用全域性特徵的風格轉換技術。
• 通過使用者研究和許多不同的例子深入評估模型,包括百年的黑白照片。著色框架
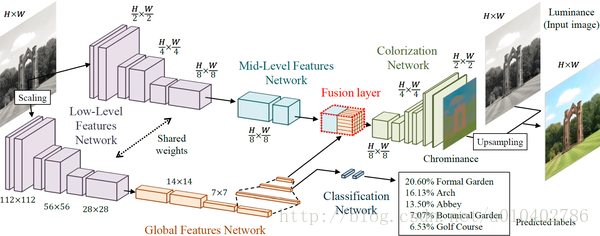
模型框架包括四個主要元件:低階特徵提取網路,中級特徵提取網路,全域性特徵提取網路和著色網路。 這些部件都以端對端的方式緊密耦合和訓練。 模型的輸出是影象的色度,其與亮度融合以形成輸出影象。
與另外兩個工作對比
• Gustav Larsson, Michael Maire, and Gregory Shakhnarovich. Learning Representations for Automatic Colorization. In ECCV 2016.
•Richard Zhang, Phillip Isola, and Alexei A. Efros. Colorful Image Colorization. In ECCV 2016.

參考文獻:
網頁:
http://hi.cs.waseda.ac.jp/~iizuka/projects/colorization/extra.html
程式碼:
https://github.com/satoshiiizuka/siggraph2016_colorization
論文2:
http://richzhang.github.io/colorization/
線上demo:
http://demos.algorithmia.com/colorize-photos/
針對模糊影象的處理,個人覺得主要分兩條路,一種是自我激發型,另外一種屬於外部學習型。接下來我們一起學習這兩條路的具體方式。
第一種 自我激發型
基於影象處理的方法,如影象增強和影象復原,以及曾經很火的超解析度演算法。都是在不增加額外資訊的前提下的實現方式。
1. 影象增強
影象增強是影象預處理中非常重要且常用的一種方法,影象增強不考慮影象質量下降的原因,只是選擇地突出影象中感興趣的特徵,抑制其它不需要的特徵,主要目的就是提高影象的視覺效果。先上一張示例圖:
影象增強中常見的幾種具體處理方法為:
直方圖均衡
在影象處理中,影象直方圖表示了影象中畫素灰度值的分佈情況。為使影象變得清晰,增大反差,凸顯影象細節,通常希望影象灰度的分佈從暗到亮大致均勻。直方圖均衡就是把那些直方圖分佈不均勻的影象(如大部分畫素灰度集中分佈在某一段)經過一種函式變換,使之成一幅具有均勻灰度分佈的新影象,其灰度直方圖的動態範圍擴大。用於直方均衡化的變換函式不是統一的,它是輸入影象直方圖的積分,即累積分佈函式。
灰度變換
灰度變換可使影象動態範圍增大,對比度得到擴充套件,使影象清晰、特徵明顯,是影象增強的重要手段之一。它主要利用影象的點運算來修正畫素灰度,由輸入畫素點的灰度值確定相應輸出畫素點的灰度值,可以看作是“從畫素到畫素”的變換操作,不改變影象內的空間關係。畫素灰度級的改變是根據輸入影象f(x,y)灰度值和輸出影象g(x,y)灰度值之間的轉換函式g(x,y)=T[f(x,y)]進行的。
灰度變換包含的方法很多,如逆反處理、閾值變換、灰度拉伸、灰度切分、灰度級修正、動態範圍調整等。影象平滑
在空間域中進行平滑濾波技術主要用於消除影象中的噪聲,主要有鄰域平均法、中值濾波法等等。這種區域性平均的方法在削弱噪聲的同時,常常會帶來影象細節資訊的損失。
鄰域平均,也稱均值濾波,對於給定的影象f(x,y)中的每個畫素點(x,y),它所在鄰域S中所有M個畫素灰度值平均值為其濾波輸出,即用一畫素鄰域內所有畫素的灰度平均值來代替該畫素原來的灰度。
中值濾波,對於給定畫素點(x,y)所在領域S中的n個畫素值數值{f1,f2,…,fn},將它們按大小進行有序排列,位於中間位置的那個畫素數值稱為這n個數值的中值。某畫素點中值濾波後的輸出等於該畫素點鄰域中所有畫素灰度的中值。中值濾波是一種非線性濾波,運算簡單,實現方便,而且能較好的保護邊界。影象銳化
採集影象變得模糊的原因往往是影象受到了平均或者積分運算,因此,如果對其進行微分運算,就可以使邊緣等細節資訊變得清晰。這就是在空間域中的影象銳化處理,其的基本方法是對影象進行微分處理,並且將運算結果與原影象疊加。從頻域中來看,銳化或微分運算意味著對高頻分量的提升。常見的連續變數的微分運算有一階的梯度運算、二階的拉普拉斯運算元運算,它們分別對應離散變數的一階差分和二階差分運算。
2. 影象復原
其目標是對退化(傳播過程中的噪聲啊,大氣擾動啊好多原因)的影象進行處理,儘可能獲得未退化的原始影象。如果把退化過程當一個黑匣子(系統H),圖片經過這個系統變成了一個較爛的圖。這類原因可能是光學系統的像差或離焦、攝像系統與被攝物之間的相對運動、電子或光學系統的噪聲和介於攝像系統與被攝像物間的大氣湍流等。影象復原常用二種方法。當不知道影象本身的性質時,可以建立退化源的數學模型,然後施行復原演算法除去或減少退化源的影響。當有了關於影象本身的先驗知識時,可以建立原始影象的模型,然後在觀測到的退化影象中通過檢測原始影象而復原影象。
3. 影象超解析度
一張圖我們想腦補細節資訊好難,但是相似的多幅圖我們就能互相腦洞了。所以,我們可以通過一系列相似的低分辨圖來共同腦補出一張高清晰圖啊,有了這一張犯罪人的臉,我就可以畫通緝令了啊。。。
超解析度復原技術的目的就是要在提高影象質量的同時恢復成像系統截止頻率之外的資訊,重建高於系統解析度的影象。繼續說超分辨,它其實就是根據多幅低質量的圖片間的關係以及一些先驗知識來重構一個高分辨的圖片。示例圖如下:
第二種 外部學習型
外部學習型,就如同照葫蘆畫瓢一樣的道理。其演算法主要是深度學習中的卷積神經網路,我們在待處理資訊量不可擴充的前提下(即模糊的影象本身就未包含場景中的細節資訊),可以藉助海量的同類資料或相似資料訓練一個神經網路,然後讓神經網路獲得對影象內容進行理解、判斷和預測的功能,這時候,再把待處理的模糊影象輸入,神經網路就會自動為其新增細節,儘管這種新增僅僅是一種概率層面的預測,並非一定準確。
本文介紹一種在灰度影象復原成彩色RGB影象方面的代表性工作:《全域性和區域性影象的聯合端到端學習影象自動著色並且同時進行分類》。利用神經網路給黑白影象上色,使其變為彩色影象。稍作解釋,黑白影象,實際上只有一個通道的資訊,即灰度資訊。彩色影象,則為RGB影象(其他顏色空間不一一列舉,僅以RGB為例講解),有三個通道的資訊。彩色影象轉換為黑白影象極其簡單,屬於有失真壓縮資料;反之則很難,因為資料不會憑空增多。
搭建一個神經網路,給一張黑白影象,然後提供大量與其相同年代的彩色影象作為訓練資料(色調比較接近),然後輸入黑白影象,人工智慧按照之前的訓練結果為其上色,輸出彩色影象,先來看一張效果圖:
本文工作
• 使用者無干預的灰度影象著色方法。
• 一個新穎的端到端網路,聯合學習影象的全域性和區域性特徵。
• 一種利用分類標籤提高效能的學習方法。
• 基於利用全域性特徵的風格轉換技術。
• 通過使用者研究和許多不同的例子深入評估模型,包括百年的黑白照片。著色框架
模型框架包括四個主要元件:低階特徵提取網路,中級特徵提取網路,全域性特徵提取網路和著色網路。 這些部件都以端對端的方式緊密耦合和訓練。 模型的輸出是影象的色度,其與亮度融合以形成輸出影象。
與另外兩個工作對比
• Gustav Larsson, Michael Maire, and Gregory Shakhnarovich. Learning Representations for Automatic Colorization. In ECCV 2016.
•Richard Zhang, Phillip Isola, and Alexei A. Efros. Colorful Image Colorization. In ECCV 2016.
參考文獻:
網頁:
http://hi.cs.waseda.ac.jp/~iizuka/projects/colorization/extra.html
程式碼:
https://github.com/satoshiiizuka/siggraph2016_colorization