
Faster R-CNN論文及原始碼解讀
R-CNN是目標檢測領域中十分經典的方法,相比於傳統的手工特徵,R-CNN將卷積神經網路引入,用於提取深度特徵,後接一個分類器判決搜尋區域是否包含目標及其置信度,取得了較為準確的檢測結果。Fast R-CNN和Faster R-CNN是R-CNN的升級版本,在準確率和實時性方面都得到了較大提升。在Fast R-CNN中,首先需要使用Selective Search的方法提取影象的候選目標區域(Proposal)。而新提出的Faster R-CNN模型則引入了RPN網路(Region Proposal Network),將Proposal的提取部分嵌入到內部網路,實現了卷積層特徵共享,Fast R-CNN則基於RPN提取的Proposal做進一步的分類判決和迴歸預測,因此,整個網路模型可以完成端到端的檢測任務,而不需要先執行特定的候選框搜尋演算法,顯著提升了演算法模型的實時性。
模型概述
Faster R-CNN模型主要由兩個模組組成:RPN候選框提取模組和Fast R-CNN檢測模組,如下圖所示,又可細分為4個部分;Conv Layer,Region Proposal Network(RPN),RoI Pooling,Classification and Regression。
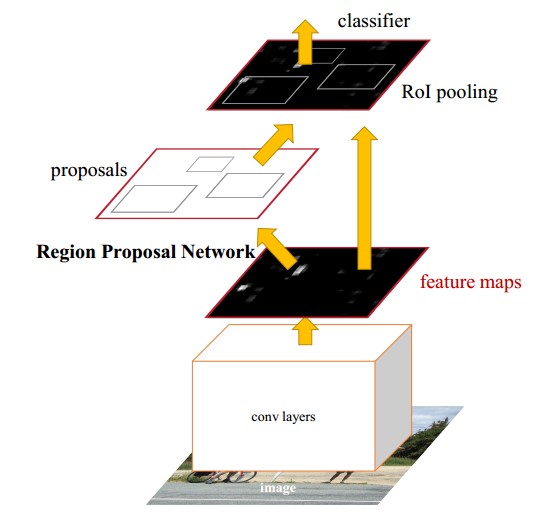
- Conv Layer: 卷積層包括一系列卷積(Conv + Relu)和池化(Pooling)操作,用於提取影象的特徵(feature maps),一般直接使用現有的經典網路模型ZF或者VGG16,而且卷積層的權值引數為RPN和Fast RCNN所共享,這也是能夠加快訓練過程、提升模型實時性的關鍵所在。
- Region Proposal Network: RPN網路用於生成區域候選框Proposal,基於網路模型引入的多尺度Anchor,通過Softmax對anchors屬於目標(foreground)還是背景(background)進行分類判決,並使用Bounding Box Regression對anchors進行迴歸預測,獲取Proposal的精確位置,並用於後續的目標識別與檢測。
- RoI Pooling: 綜合卷積層特徵feature maps和候選框proposal的資訊,將propopal在輸入影象中的座標對映到最後一層feature map(conv5-3)中,對feature map中的對應區域進行池化操作,得到固定大小(7×77×7)輸出的池化結果,並與後面的全連線層相連。
- Classification and Regression: 全連線層後接兩個子連線層——分類層(cls)和迴歸層(reg),分類層用於判斷Proposal的類別,迴歸層則通過bounding box regression預測Proposal的準確位置。
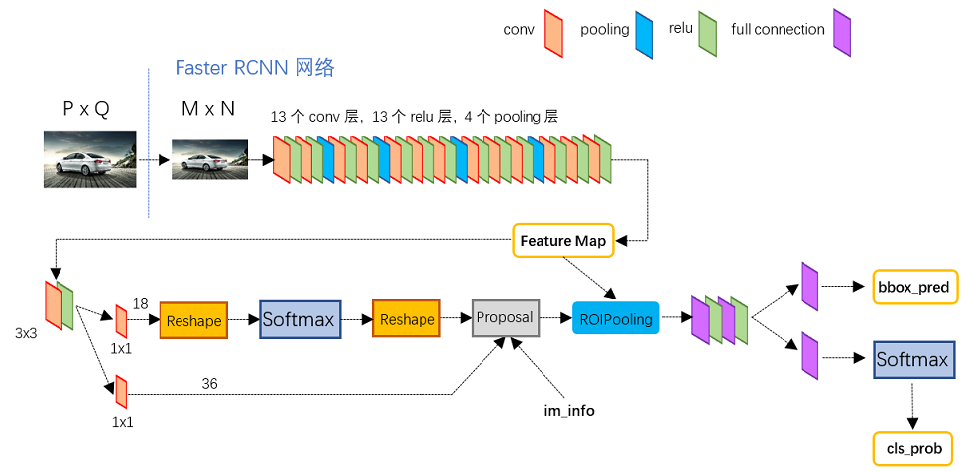
下圖為Faster R-CNN測試網路結構(網路模型檔案為faster_rcnn_test.pt),可以清楚地看到影象在網路中的前向計算過程。對於一幅任意大小P×QP×Q的影象,首先縮放至固定大小M×NM×N(原始碼中是要求長邊不超過1000,短邊不超過600),然後將縮放後的影象輸入至採用VGG16模型的Conv Layer中,最後一個feature map為conv5-3,特徵數(channels)為512。RPN網路在特徵圖conv5-3上執行3×33×3卷積操作,後接一個512維的全連線層,全連線層後接兩個子連線層,分別用於anchors的分類和迴歸,再通過計算篩選得到proposals。RoIs Pooling層則利用Proposal從feature maps中提取Proposal feature進行池化操作,送入後續的Fast R-CNN網路做分類和迴歸。RPN網路和Fast R-CNN網路中均有分類和迴歸,但兩者有所不同,RPN中分類是判斷conv5-3中對應的anchors屬於目標和背景的概率(score),並通過迴歸獲取anchors的偏移和縮放尺度,根據目標得分值篩選用於後續檢測識別的Proposal;Fast R-CNN是對RPN網路提取的Proposal做分類識別,並通過迴歸引數調整得到目標(Object)的精確位置。具體的訓練過程會在後面詳述。接下來會重點介紹RPN網路和Fast R-CNN網路這兩個模組,包括RPN網路中引入的Anchor機制、訓練資料的生成、分類和迴歸的損失函式(Loss Function)計算以及RoI Pooling等。
Region Proposal Network(RPN)
傳統的目標檢測方法中生成候選框都比較耗時,例如使用滑動視窗加影象金字塔的方式遍歷影象,獲取多尺度的候選區域;以及R-CNN、Fast R-CNN中均使用到的Selective Search的方法生成候選框。而Faster R-CNN則直接使用RPN網路,將檢測框Proposal的提取嵌入到網路內部,通過共享卷積層引數的方式提升了Proposal的生成速度。
Anchor
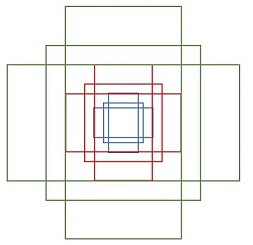
Anchor是RPN網路中一個較為重要的概念,傳統的檢測方法中為了能夠得到多尺度的檢測框,需要通過建立影象金字塔的方式,對影象或者濾波器(滑動視窗)進行多尺度取樣。RPN網路則是使用一個3×33×3的卷積核,在最後一個特徵圖(conv5-3)上滑動,將卷積核中心對應位置映射回輸入影象,生成3種尺度(scale){1282,2562,5122}{1282,2562,5122}和3種長寬比(aspect ratio){1:1,1:2,2:1}{1:1,1:2,2:1}共9種Anchor,如下圖所示。特徵圖conv5-3每個位置都對應9個anchors,如果feature map的大小為W×HW×H,則一共有W×H×9W×H×9個anchors,滑動視窗的方式保證能夠關聯conv5-3的全部特徵空間,最後在原圖上得到多尺度多長寬比的anchors。
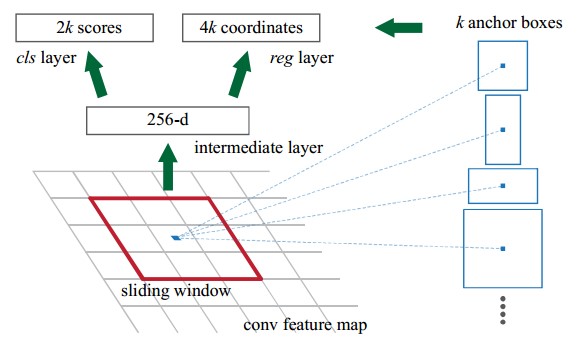
最後一個feature map後面會接一個全連線層,如下圖所示,全連線的維數和feature map的特徵數(channels)相同。對於原論文中採用的ZF模型,conv5的特徵數為256,全連線層的維數也為256;對於VGG模型,conv5-3的特徵數為512,全連線的的維數則為512,相當於feature map上的每一個點都輸出一個512維的特徵向量。
關於anchors還有幾點需要說明:
- conv5-3上使用了3×33×3的卷積核,每個點都可以關聯區域性鄰域的空間資訊。
- conv5-3上每個點前向對映得到k(k=9)個anchors,並且後向輸出512維的特徵向量,而anchors的作用是分類和迴歸得到Proposal,因此全連線層後須接兩個子連線層————分類層(cls)和迴歸層(reg),分類層用於判斷anchors屬於目標還是背景,向量維數為2k;迴歸層用於計算anchors的偏移量和縮放量,共4個引數[dx,dy,dw,dh][dx,dy,dw,dh],向量維數為4k。
訓練樣本的生成
一般而言,特徵圖conv5-3的實際尺寸大致為60×4060×40,那麼一共可以生成60×40×9≈20k60×40×9≈20k個anchors,顯然不會將所有anchors用於訓練,而是篩選一定數量的正負樣本。對於資料集中包含有人工標定ground truth的影象,考慮一張影象上所有anchors:
- 首先過濾掉超出影象邊界的anchors
- 對每個標定的ground truth,與其重疊比例IoU最大的anchor記為正樣本,這樣可以保證每個ground truth至少對應一個正樣本anchor
- 對每個anchors,如果其與某個ground truth的重疊比例IoU大於0.7,則記為正樣本(目標);如果小於0.3,則記為負樣本(背景)
- 再從已經得到的正負樣本中隨機選取256個anchors組成一個minibatch用於訓練,而且正負樣本的比例為1:1,;如果正樣本不夠,則補充一些負樣本以滿足256個anchors用於訓練,反之亦然。
Multi-task Loss Function
由於涉及到分類和迴歸,所以需要定義一個多工損失函式(Multi-task Loss Function),包括Softmax Classification Loss和Bounding Box Regression Loss,公式定義如下:
L({pi},{ti})=1NclsΣiLcls(pi,p∗i)+λ1NregΣip∗iLreg(ti,t∗i)L({pi},{ti})=1NclsΣiLcls(pi,pi∗)+λ1NregΣipi∗Lreg(ti,ti∗)
Softmax Classification:對於RPN網路的分類層(cls),其向量維數為2k = 18,考慮整個特徵圖conv5-3,則輸出大小為W×H×18W×H×18,正好對應conv5-3上每個點有9個anchors,而每個anchor又有兩個score(fg/bg)輸出,對於單個anchor訓練樣本,其實是一個二分類問題。為了便於Softmax分類,需要對分類層執行reshape操作,這也是由底層資料結構決定的。在caffe中,Blob的資料儲存形式為Blob=[batch_size,channel,height,width]Blob=[batch_size,channel,height,width],而對於分類層(cls),其在Blob中的實際儲存形式為[1,2k,H,W][1,2k,H,W],而Softmax針對每個anchor進行二分類,所以需要在分類層後面增加一個reshape layer,將資料組織形式變換為[1,2,k∗H,W][1,2,k∗H,W],之後再reshape回原來的結構,caffe中有對softmax_loss_layer.cpp的reshape函式做如下解釋:
| 1 2 3 4 |
"Number of labels must match number of predictions; " "e.g., if softmax axis == 1 and prediction shape is (N, C, H, W), " "label count (number of labels) must be N*H*W, " "with integer values in {0, 1, ..., C-1}."; |
在上式中,pipi為樣本分類的概率值,p∗ipi∗為樣本的標定值(label),anchor為正樣本時p∗ipi∗為1,為負樣本時p∗ipi∗為0,LclsLcls為兩種類別的對數損失(log loss)。
Bounding Box Regression:RPN網路的迴歸層輸出向量的維數為4k = 36,迴歸引數為每個樣本的座標[x,y,w,h][x,y,w,h],分別為box的中心位置和寬高,考慮三組引數預測框(predicted box)座標[x,y,w,h][x,y,w,h],anchor座標[xa,ya,wa,ha][xa,ya,wa,ha],ground truth座標[x∗,y∗,w∗,h∗][x∗,y∗,w∗,h∗],分別計算預測框相對anchor中心位置的偏移量以及寬高的縮放量{t}{t},ground truth相對anchor的偏移量和縮放量{t∗}{t∗}
tx=(x−xa)/wa, ty=(y−ya)/ha, tw=log(w/wa), th=log(h/ha) (1)tx=(x−xa)/wa, ty=(y−ya)/ha, tw=log(w/wa), th=log(h/ha) (1)
t∗x=(x∗−xa)/wa, t∗y=(y∗−ya)/ha, t∗w=log(w∗/wa), t∗h=log(h∗/ha) (2)tx∗=(x∗−xa)/wa, ty∗=(y∗−ya)/ha, tw∗=log(w∗/wa), th∗=log(h∗/ha) (2)
迴歸目標就是讓{t}{t}儘可能地接近{t∗}{t∗},所以迴歸真正預測輸出的是{t}{t},而訓練樣本的標定真值為{t∗}{t∗}。得到預測輸出{t}{t}後,通過上式(1)即可反推獲取預測框的真實座標。在損失函式中,迴歸損失採用Smooth L1函式
SmoothL1(x)={0.5x2 |x|≤1|x|−0.5 otherwiseSmoothL1(x)={0.5x2 |x|≤1|x|−0.5 otherwise
Lreg=SmoothL1(t−t∗)Lreg=SmoothL1(t−t∗)
Smooth L1損失函式曲線如下圖所示,相比於L2損失函式,L1對離群點或異常值不敏感,可控制梯度的量級使訓練更易收斂。
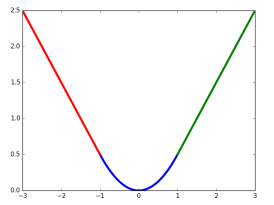
在損失函式中,p∗iLregpi∗Lreg這一項表示只有目標anchor(p∗i=1pi∗=1)才有迴歸損失,其他anchor不參與計算。這裡需要注意的是,當樣本bbox和ground truth比較接近時(IoU大於某一閾值),可以認為上式的座標變換是一種線性變換,因此可將樣本用於訓練線性迴歸模型,否則當bbox與ground truth離得較遠時,就是非線性問題,用線性迴歸建模顯然不合理,會導致模型不work。分類層(cls)和迴歸層(reg)的輸出分別為{p}{p}和{t}{t},兩項損失函式分別由NclsNcls和NregNreg以及一個平衡權重λλ歸一化。分類損失的歸一化值為minibatch的大小,即Ncls=256Ncls=256;迴歸損失的歸一化值為anchor位置的數量,即Nreg≈2400Nreg≈2400;λλ一般取值為10,這樣分類損失和迴歸損失差不多是等權重的。
Proposal的生成
Proposal的生成就是將影象輸入到RPN網路中進行一次前向(forward)計算,處理流程如下:
- 計算特徵圖conv5-3對映到輸入影象的所有anchors,並通過RPN網路前向計算得到anchors的score輸出和bbox迴歸引數
- 由anchors座標和bbox迴歸引數計算得到預測框proposal的座標
- 處理proposal座標超出影象邊界的情況(使得座標最小值為0,最大值為寬或高)
- 濾除掉尺寸(寬高)小於給定閾值的proposal
- 對剩下的proposal按照目標得分(fg score)從大到小排序,提取前pre_nms_topN(e.g. 6000)個proposal
- 對提取的proposal進行非極大值抑制(non-maximum suppression,nms),再根據nms後的foreground score,篩選前post_nms_topN(e.g. 300)個proposal作為最後的輸出
Fast R-CNN
對於RPN網路中生成的proposal,需要送入Fast R-CNN網路做進一步的精確分類和座標迴歸,但proposal的尺寸可能大小不一,所以需要做RoI Pooling,輸出統一尺寸的特徵,再與後面的全連線層相連。
RoI Pooling
對於傳統的卷積神經網路,當網路訓練好後輸入影象的尺寸必須是固定值,同時網路輸出的固定大小的向量或矩陣。如果輸入影象大小不統一,則需要進行特殊處理,如下圖所示:
- 從影象中crop一部分傳入網路
- 將影象warp成需要的大小後傳入網路

可以從圖中看出,crop操作破壞了影象的完整結構,warp操作破壞了影象的原始形狀資訊,兩種方法的效果都不太理想。RPN網路生成的proposal也存在尺寸不一的情況,但論文中提出了RoI Pooling的方法解決這個問題。
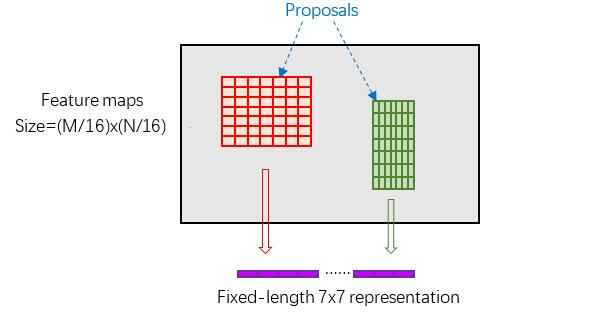
RoI Pooling結合特徵圖conv5-3和proposal的資訊,proposal在輸入影象中的座標[x1,y1,x2,y2][x1,y1,x2,y2]對應M×NM×N尺度,將proposal的座標對映到M16×N16M16×N16大小的conv5-3中,然後將Proposal在conv5-3的對應區域水平和豎直均分為7等份,並對每一份進行Max Pooling或Average Pooling處理,得到固定大小(7×77×7)輸出的池化結果,實現固定長度輸出(fixed-length output),如下圖所示。
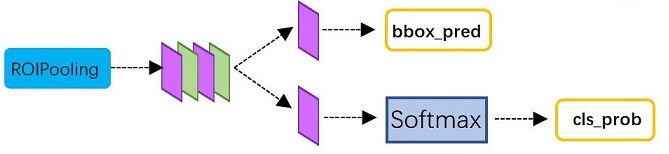
Classification and Regression
RoI Pooling層後接多個全連線層,最後為兩個子連線層——分類層(cls)和迴歸層(reg),如下圖所示,和RPN的輸出類似,只不過輸出向量的維數不一樣。如果類別數為N+1(包括背景),分類層的向量維數為N+1,迴歸層的向量維數則為4(N+1)。還有一個關鍵問題是RPN網路輸出的proposal如何組織成Fast R-CNN的訓練樣本:
- 對每個proposal,計算其與所有ground truth的重疊比例IoU
- 篩選出與每個proposal重疊比例最大的ground truth
- 如果proposal的最大IoU大於0.5則為目標(前景),標籤值(label)為對應ground truth的目標分類;如果IoU小於0.5且大於0.1則為背景,標籤值為0
- 從2張影象中隨機選取128個proposals組成一個minibatch,前景和背景的比例為1:3
- 計算樣本proposal與對應ground truth的迴歸引數作為標定值,並且將回歸引數從(4,)拓展為(4(N+1),),只有對應類的標定值才為非0。
- 設定訓練樣本的迴歸權值,權值同樣為4(N+1)維,且只有樣本對應標籤類的權值才為非0。
在原始碼實現中,用於訓練Fast R-CNN的Proposal除了RPN網路生成的,還有影象的ground truth,這兩者歸併到一起,然後通過篩選組成minibatch用於迭代訓練。Fast R-CNN的損失函式也與RPN類似,二分類變成了多分類,背景同樣不參與迴歸損失計算,且只考慮proposal預測為標籤類的迴歸損失。
Faster R-CNN的訓練
對於提取proposals的RPN,以及分類迴歸的Fast R-CNN,如何將這兩個網路嵌入到同一個網路結構中,訓練一個共享卷積層引數的多工(Multi-task)網路模型。原始碼中有實現交替訓練(Alternating training)和端到端訓練(end-to-end)兩種方式,這裡介紹交替訓練的方法。
- 訓練RPN網路,用ImageNet模型M0初始化,訓練得到模型M1
- 利用第一步訓練的RPN網路模型M1,生成Proposal P1
- 使用上一步生成的Proposal,訓練Fast R-CNN網路,同樣用ImageNet模型初始化,訓練得到模型M2
- 訓練RPN網路,用Fast R-CNN網路M2初始化,且固定卷積層引數,只微調RPN網路獨有的層,訓練得到模型M3
- 利用上一步訓練的RPN網路模型M3,生成Proposal P2
- 訓練Fast R-CNN網路,用RPN網路模型M3初始化,且卷積層引數和RPN引數不變,只微調Fast R-CNN獨有的網路層,得到最終模型M4
由訓練流程可知,第4步訓練RPN網路和第6步訓練Fast R-CNN網路實現了卷積層引數共享。總體上看,訓練過程只迴圈了2次,但每一步訓練(M1,M2,M3,M4)都迭代了多次(e.g. 80k,60k)。對於固定卷積層引數,只需將學習率(learning rate)設定為0即可。
原始碼解析
以上關於RPN的訓練,Proposal的生成,以及Fast R-CNN的訓練做了的詳細講解,接下來結合網路模型圖和部分原始碼,對這些模組做進一步的分析。
train RPN
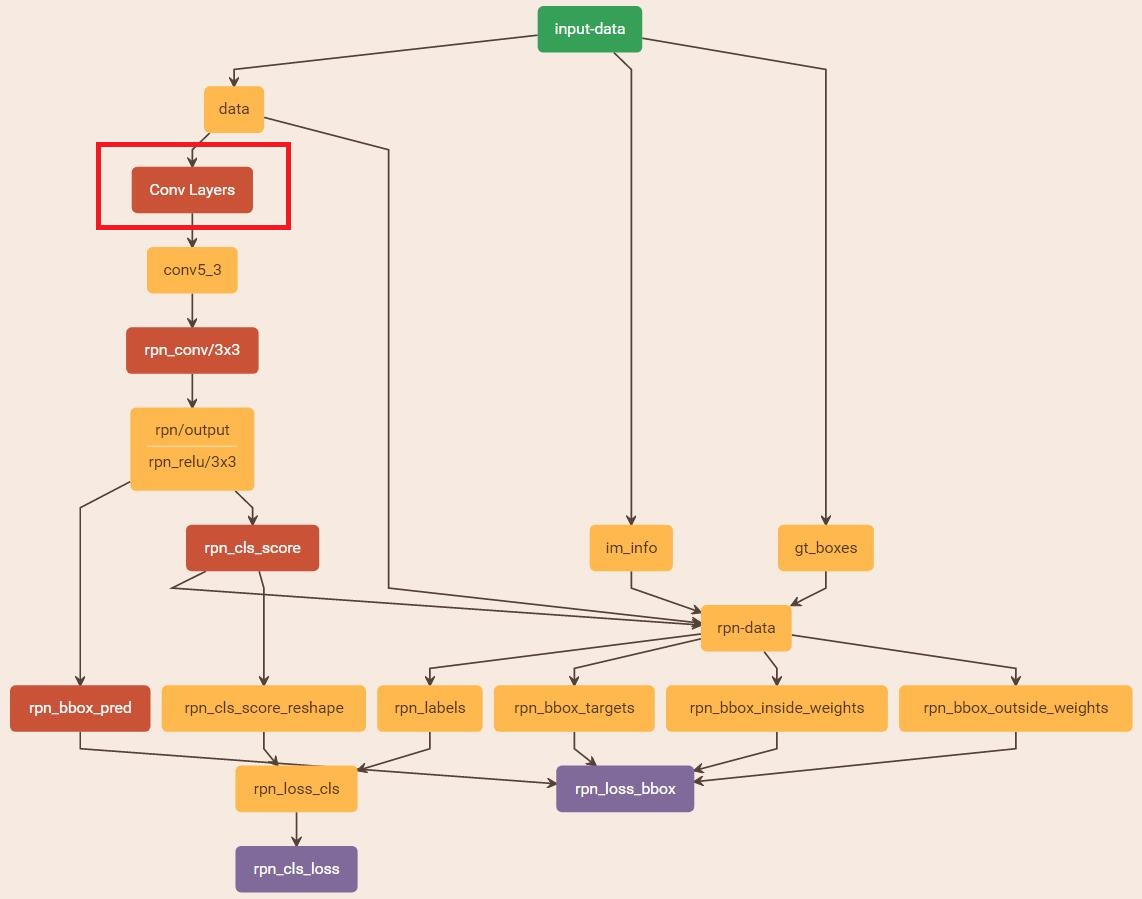
訓練RPN的網路結構如下圖所示,首先載入引數檔案,並改動一些引數適應當前訓練任務。在train_rpn函式中呼叫get_roidb、get_imdb、get_train_imdb_roidb等獲取訓練資料集,並通過呼叫gt_roidb和prepare_roidb方法對訓練資料進行預處理,為樣本增添一些屬性,資料集roidb中的每個影象樣本,主要有以下屬性:
| 1 2 3 4 5 6 7 8 9 10 |
'image':影象儲存路徑 'width':影象寬 'height':影象高 'boxes':影象中bbox(groundtruth or proposal)的座標[x1,y1,x2,y2] 'gt_classes':每個bbox對應的類索引(1~20) 'gt_overlaps':二維陣列,shape=[num_boxes * num_classes],每個bbox(ground truth)對應的類索引處取值為1,其餘為0 'flipped':取值為True/False,用於標記有無將影象水平翻轉 'seg_area':bbox的面積 'max_classes':bbox與所有ground truth的重疊比例IoU最大的類索引(gt_overlaps.argmax(axis=1)) 'max_overlaps':bbox與所有ground truth的IoU最大值(gt_overlaps.max(axis=1)) |
獲取資料集roidb中字典的屬性後,設定輸出路徑output_dir,用來儲存中間訓練結果,然後呼叫train_net函式。在train_net函式中,首先呼叫filter_roidb,濾除掉既沒有前景又沒有背景的roidb。然後呼叫layer.py中的set_roidb方法,打亂訓練樣本roidb的順序,將roidb中長寬比近似的影象放在一起。之後開始訓練模型train_model,這裡需要例項化每個層,對於第一層RoIDataLayer,通過setup方法進行例項化,並且在訓練過程中通過forward方法,呼叫get_minibatch函式,獲取每一次迭代訓練的資料,在讀取資料時,主要獲取了3個屬性組成Layer中的Blob
| 1 2 3 |
'data':單張影象資料im_blob=[1,3,H,W] 'gt_boxes':一幅影象中所有ground truth的座標和類別[x1,y1,x2,y2,cls] 'im_info':影象的寬高和縮放比例 height,width,scale = [[im_blob.shape[2], im_blob.shape[2], im_scale[0]]] |
從網路結構圖中可以看出,input-data(RoIDataLayer)的下一層是rpn-data(AnchorTargetLayer),rpn-data計算所有anchors與ground truth的重疊比例IoU,從中篩選出一定數量(256)的正負樣本組成一個minibatch,用於RPN網路的訓練,這一層的輸出有如下屬性:
| 1 2 3 4 5 |
'rpn_label':每個anchor對應的類別(1——fg,0——bg,-1——ignored),shape=[1,1,A*height,width] 'rpn_bbox_targets':anchor與ground truth的迴歸引數[dx,dy,dw,dh],shape=[1,A*4,height,width] 'rpn_box_inside_targets':迴歸損失函式中的樣本權值,正樣本為1,負樣本為0,相當於損失函式中的p*,shape=[1,A*4,height,width] 'rpn_box_outside_targets':分類損失函式和迴歸損失函式的平衡權重,相當於λ,shape=[1,A*4,height,width] 注:height、width為特徵圖conv5-3的高寬,A=9為Anchor種數 |
對於分類損失rpn_loss_cls,輸入的rpn_cls_scors_reshape和rpn_labels分別對應pp與p∗p∗;對於迴歸損失,輸入的rpn_bbox_pred和rpn_bbox_targets分別對應{t}{t}與{t∗}{t∗},pn_bbox_inside_weigths對應p∗p∗,rpn_bbox_outside_weights對應λλ。
generate proposals
Proposal的生成只需將影象輸入到RPN網路中,進行前向(forward)計算然後經過篩選即可得到,網路結構如下圖所示
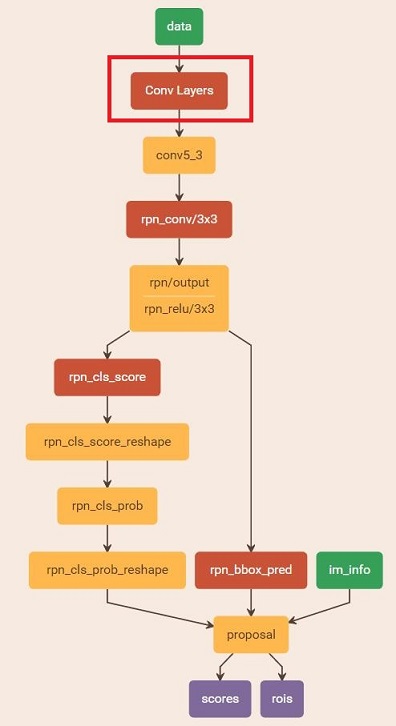
從rpn_proposals = imdb_proposals(rpn_net, imdb)開始,使用im = cv2.imread(imdb.image_path_at(i))讀入圖片資料,呼叫 im_proposals生成單張圖片的rpn proposals,以及得分。im_proposals函式會呼叫網路的forward方法,從而得到想要的boxes和scores,最後將獲取的proposal儲存在python pickle檔案中。
train Fast R-CNN
訓練Fast R-CNN的網路結構如下圖所示,首先設定引數適應訓練任務,在預處理資料時,呼叫的不再是gt_roidb方法,而是rpn_roidb,通過使用類imdb的靜態方法merge_roidb,將rpn_roidb和gt_roidb歸併為一個roidb,因此資料集中的’boxes’屬性除了包含ground truth,還有RPN網路生成的proposal,可通過上一步儲存的檔案直接讀取。通過add_bbox_regression_targets方法給roidb的樣本增添了額外的屬性’bbox_targets’,用於表示迴歸引數的標定值。屬性’gt_overlaps’是所有proposal與ground truth通過計算IoU得到的。最後就是呼叫get_minibatch方法從2張影象中選取128個proposal作為一次迭代的訓練樣本,讀取資料時,獲取如下屬性組成Layer中的Blob
| 1 2 3 4 5 6 |
'data':影象資料 'rois':proposals的座標[batch_inds,x1,y1,x2,y2] 'label':proposals對應的類別(0~20) 'bbox_targets':proposal迴歸引數的標定值,shape = [128, 4(N+1)] 'box_inside_targets':迴歸損失函式中的樣本權值,正樣本為1,負樣本為0,相當於損失函式中的p* 'rpn_box_outside_targets':分類損失函式和迴歸損失函式的平衡權重,相當於λ |
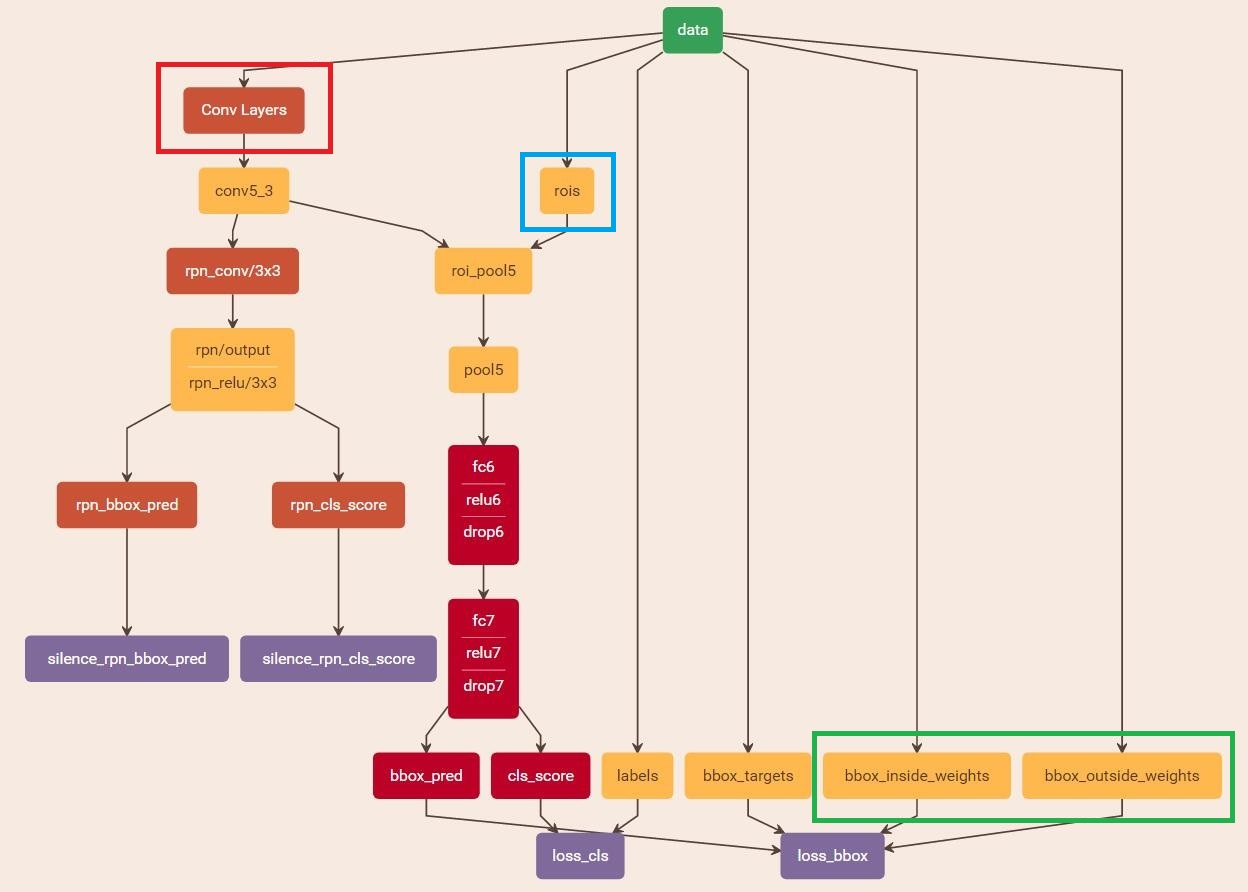
損失函式的計算與RPN網路類似。在Faster R-CNN中,自定義的Python Layer包括RoIDataLayer、AnchorTargetLay、ProposalLayer,都只實現了前向計算forward,因為這些Layer的作用是獲取用於訓練網路的資料,而對網路本身沒有貢獻任何權值引數,也不傳播梯度值,因此不需要實現反向傳播backward。
reference
- Paper: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- Paper: R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation
- Paper: SPP-Net: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Paper: Fast R-CNN
- Code: Caffe implement of Faster RCNN
- Code: Tensorflow implement of Faster RCNN
- http://blog.csdn.net/iamzhangzhuping/article/category/6230157
- http://www.infocool.net/kb/Python/201611/209696.html
- http://www.cnblogs.com/venus024/p/5717766.html
- http://blog.csdn.net/zy1034092330/article/details/62044941