
文字聚類演算法介紹
個人部落格站已經上線了,網址 www.llwjy.com ~歡迎各位吐槽~
-------------------------------------------------------------------------------------------------
本部落格通過對當前比較成熟的聚類演算法分析,介紹如何對非結構的資料(文件)做聚類演算法,第一大部分的內容來源百度百科,第二部分是對文字聚類演算法思想的介紹。這裡因為各種原因就不給出具體的程式碼實現,如若有興趣,可以在後面留言一起討論。
###################################################################################
#####以下內容為聚類介紹,來源百度百科,如果已經瞭解,可以直接忽略跳到下一部分
###################################################################################
聚類概念
聚類分析又稱群分析,它是研究(樣品或指標)分類問題的一種統計分析方法,同時也是資料探勘的一個重要演算法。聚類(Cluster)分析是由若干模式(Pattern)組成的,通常,模式是一個度量(Measurement)的向量,或者是多維空間中的一個點。聚類分析以相似性為基礎,在一個聚類中的模式之間比不在同一聚類中的模式之間具有更多的相似性。
演算法用途
在商業上,聚類可以幫助市場分析人員從消費者資料庫中區分出不同的消費群體來,並且概括出每一類消費者的消費模式或者說習慣。它作為資料探勘中的一個模組,可以作為一個單獨的工具以發現數據庫中分佈的一些深層的資訊,並且概括出每一類的特點,或者把注意力放在某一個特定的類上以作進一步的分析;並且,聚類分析也可以作為資料探勘演算法中其他分析演算法的一個預處理步驟。
聚類分析的演算法可以分為劃分法(Partitioning Methods)、層次法(Hierarchical Methods)、基於密度的方法(density-based methods)、基於網格的方法(grid-based methods)、基於模型的方法(Model-Based Methods)。
演算法分類
很難對聚類方法提出一個簡潔的分類,因為這些類別可能重疊,從而使得一種方法具有幾類的特徵,儘管如此,對於各種不同的聚類方法提供一個相對有組織的描述依然是有用的,為聚類分析計算方法主要有如下幾種:
劃分法
劃分法(partitioning methods),給定一個有N個元組或者紀錄的資料集,分裂法將構造K個分組,每一個分組就代表一個聚類,K<N。而且這K個分組滿足下列條件:
(1) 每一個分組至少包含一個數據紀錄;
(2)每一個數據紀錄屬於且僅屬於一個分組(注意:這個要求在某些模糊聚類演算法中可以放寬);
對於給定的K,演算法首先給出一個初始的分組方法,以後通過反覆迭代的方法改變分組,使得每一次改進之後的分組方案都較前一次好,而所謂好的標準就是:同一分組中的記錄越近越好,而不同分組中的紀錄越遠越好。
大部分劃分方法是基於距離的。給定要構建的分割槽數k,劃分方法首先建立一個初始化劃分。然後,它採用一種迭代的重定位技術,通過把物件從一個組移動到另一個組來進行劃分。一個好的劃分的一般準備是:同一個簇中的物件儘可能相互接近或相關,而不同的簇中的物件儘可能遠離或不同。還有許多評判劃分質量的其他準則。傳統的劃分方法可以擴充套件到子空間聚類,而不是搜尋整個資料空間。當存在很多屬性並且資料稀疏時,這是有用的。為了達到全域性最優,基於劃分的聚類可能需要窮舉所有可能的劃分,計算量極大。實際上,大多數應用都採用了流行的啟發式方法,如k-均值和k-中心演算法,漸近的提高聚類質量,逼近區域性最優解。這些啟發式聚類方法很適合發現中小規模的資料庫中小規模的資料庫中的球狀簇。為了發現具有複雜形狀的簇和對超大型資料集進行聚類,需要進一步擴充套件基於劃分的方法。
使用這個基本思想的演算法有:K-MEANS演算法、K-MEDOIDS演算法、CLARANS演算法;
層次法
層次法(hierarchical methods),這種方法對給定的資料集進行層次似的分解,直到某種條件滿足為止。具體又可分為“自底向上”和“自頂向下”兩種方案。
例如,在“自底向上”方案中,初始時每一個數據紀錄都組成一個單獨的組,在接下來的迭代中,它把那些相互鄰近的組合併成一個組,直到所有的記錄組成一個分組或者某個條件滿足為止。
層次聚類方法可以是基於距離的或基於密度或連通性的。層次聚類方法的一些擴充套件也考慮了子空間聚類。層次方法的缺陷在於,一旦一個步驟(合併或分裂)完成,它就不能被撤銷。這個嚴格規定是有用的,因為不用擔心不同選擇的組合數目,它將產生較小的計算開銷。然而這種技術不能更正錯誤的決定。已經提出了一些提高層次聚類質量的方法。
代表演算法有:BIRCH演算法、CURE演算法、CHAMELEON演算法等;
密度演算法
基於密度的方法(density-based methods),基於密度的方法與其它方法的一個根本區別是:它不是基於各種各樣的距離的,而是基於密度的。這樣就能克服基於距離的演算法只能發現“類圓形”的聚類的缺點。
這個方法的指導思想就是,只要一個區域中的點的密度大過某個閾值,就把它加到與之相近的聚類中去。
代表演算法有:DBSCAN演算法、OPTICS演算法、DENCLUE演算法等;
圖論聚類法
圖論聚類方法解決的第一步是建立與問題相適應的圖,圖的節點對應於被分析資料的最小單元,圖的邊(或弧)對應於最小處理單元資料之間的相似性度量。因此,每一個最小處理單元資料之間都會有一個度量表達,這就確保了資料的區域性特性比較易於處理。圖論聚類法是以樣本資料的局域連線特徵作為聚類的主要資訊源,因而其主要優點是易於處理區域性資料的特性。
網格演算法
基於網格的方法(grid-based methods),這種方法首先將資料空間劃分成為有限個單元(cell)的網格結構,所有的處理都是以單個的單元為物件的。這麼處理的一個突出的優點就是處理速度很快,通常這是與目標資料庫中記錄的個數無關的,它只與把資料空間分為多少個單元有關。
代表演算法有:STING演算法、CLIQUE演算法、WAVE-CLUSTER演算法;
模型演算法
基於模型的方法(model-based methods),基於模型的方法給每一個聚類假定一個模型,然後去尋找能夠很好的滿足這個模型的資料集。這樣一個模型可能是資料點在空間中的密度分佈函式或者其它。它的一個潛在的假定就是:目標資料集是由一系列的概率分佈所決定的。
通常有兩種嘗試方向:統計的方案和神經網路的方案。
###################################################################################
#####以下內容為文字聚類方法分析
###################################################################################
文字聚類
目前針對聚類演算法的研究多數都是基於結構化資料,很少有針對非結構化資料的,這裡就介紹下自己對這方面的研究。由於原始碼目前牽扯到一系列的問題,所以這裡就只介紹思想,不提供原始碼,如有想進一步瞭解的,可以在下方留言。
文字聚類(Text clustering)文件聚類主要是依據著名的聚類假設:同類的文件相似度較大,而不同類的文件相似度較小。作為一種無監督的機器學習方法,聚類由於不需要訓練過程,以及不需要預先對文件手工標註類別,因此具有一定的靈活性和較高的自動化處理能力,已經成為對文字資訊進行有效地組織、摘要和導航的重要手段。
我們本次的介紹重點就是介紹如何對非結構化的文字做聚類。
文字聚類思想
由於目前對結構化的資料的聚類研究已經十分成熟,所以我們就要想辦法把這種非結構化的資料轉化為結構化的資料,這樣也許就會很好處理。
由於自己的工作方向是搜尋引擎,所以自己的一些演算法思想也都是基於它來的,對於如何將非結構話的資料轉化為結構化的資料,可以參照下部落格《基於lucene的案例開發:索引數學模型》。
下面給出具體的演算法說明:
第一步:記錄分詞
這裡為了簡化模型,我們就直接預設一篇文字只有一個屬性。在這一步中,我們需要對所有的文件做初始化分析,過程中我們需要統計如下幾個值:第N篇文件包含哪些詞元、第N篇文件中的詞元M在文件N中出現的次數、詞元M在多少篇文件中出現、詞元M在所有文件中出現的次數。在這一步中,需要使用到分詞技術,當處理中文的時候,建議使用IK等中文分詞器,其他通用分詞器處理的效果不是太好。這一步將文件轉化為Document = {term1,
term2, term3 …… termN};
第二步:計算權重
這裡的計算權重方法和之前的稍微有一點區別,具體計算公式如下:
通過這一步的處理,我們就將Document = {term1, term2, term3 …… termN}轉化為DocumentVector = {weight1, weight2, weight3 …… weightN}
第三步:N維空間向量模型
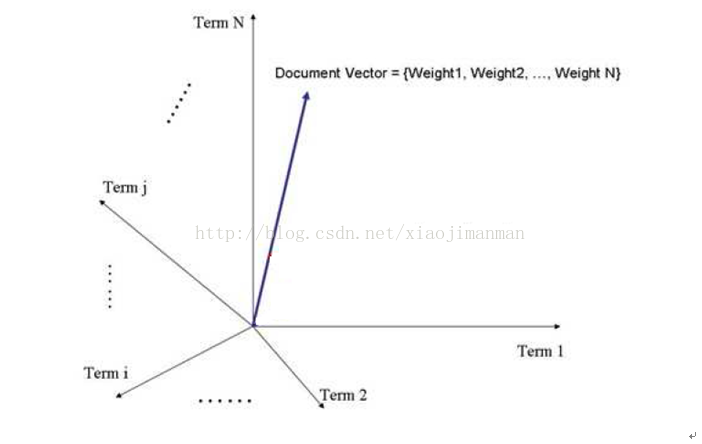
我們將第二步得到的DocumentVector放到N維空間向量模型中(N是詞元的總數),文件D在m座標上的對映為文件D中的m詞元的權重,具體如下圖:

第四步:最相近的文件
在N維空間向量模型中,我們規定夾角越小,兩篇文件就越相似。這一步,我們需要找到兩個夾角最小的兩個向量(即最相似的兩篇文件);
第五步:合併文件
將第四步得到的兩篇文件視為一篇文件(即將這兩篇文件當作一個類別);
第六步:驗證
判斷這時的文件數目是否滿足要求(目前剩餘的文件數是否等於要聚類的類別數),如果滿足要求結束本次演算法,不滿足要求,跳到第二步迴圈2、3、4、5、6。
演算法評估
目前在自己工作筆記本(配置一般,記憶體4G)上的測試結果是聚類1W篇文件耗時在40s~50s,下圖是對10條資料的聚類效果截圖:
