
再探spark之二
在Spark2.X.X後,想要在Spark-shell中執行這個命令,你需要使用spark.sqlContext.sql()的形式。
spark的cache快取其中的方法 (儲存在記憶體中)
.cache() //進行快取
.unpresist(true) //對資源進行釋放
spark的checkpoint機制(儲存在hdfs中)(checkpoint和cache都屬於transformation 需要action才能執行)
sc.setCheckpointDir("hdfs://hadoop01:9000/ck2018523")
val rdd = sc.textFile("hdfs://hadoop01:9000/itcast")
rdd.checkpoint
rdd.count //這裡會執行兩次,一個是本身的計算,一個是額外的checkpoint寫到hdfs
val rdd2=rdd.map(_.split("\t")).map(x =>(x(1), 1)).reduceByKey(_+_)
rdd2.cache //如果在checkpoint前面新加一個cache,會提高很快的效率,而不需要重新啟動一個額外的任務
rdd2.checkpoint
rdd2.collect
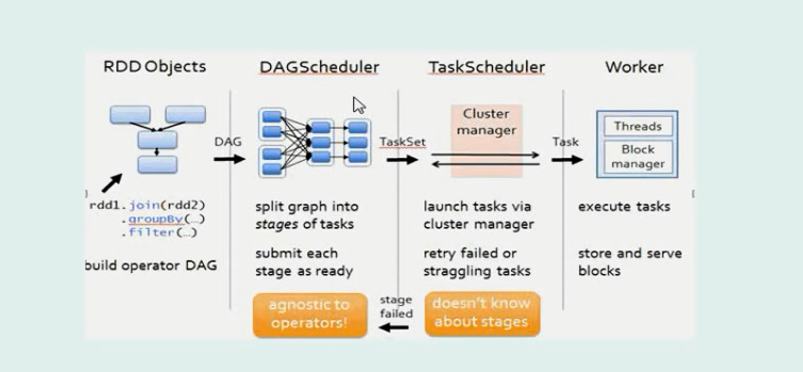
spark的提交流程如下圖
1、driver端向master端通訊,然後master端通知並分配任務給各個worker端
worker端啟動excutor剩下的就沒master什麼事了,主要是worker和driver之間的通訊
2、sc的產生標誌著driver和master端之間開始通訊
3、下面途中RDD objects 和DAGschedule都是在driver端完成的
1.1.1. 窄依賴
窄依賴指的是每一個父RDD的Partition最多被子RDD的一個Partition使用
總結:窄依賴我們形象的比喻為獨生子女
1.1.2. 寬依賴
寬依賴指的是多個子RDD的Partition會依賴同一個父RDD的Partition
總結:窄依賴我們形象的比喻為超生
stage 的劃分是根據寬依賴,寬依賴大多伴隨著shuffle所以不能在一條流水線(pipeline)上
SparkSQL
第一種dataframe建立的方式
package com.wxa.spark.four
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}
object SQLDemowxa {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SQLDemo").setMaster("local[2]")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
System.setProperty("user.name","root") //這步設定登陸名
val personRdd=sc.textFile("hdfs://hadoop01:9000/person.txt").map(line=>{
val field =line.split(",")
person(field(0).toLong,field(1),field(2).toInt)
})
import sqlContext.implicits._
val personDF = personRdd.toDF() //轉為dataframe
personDF.show() //這是DSL風格的方式模仿R語言 如 res1.select("id","name").show 有點像sql但不是SQL方式 以json形式寫到hdfs上面 res1.select("id","name").write.json("hdfs://hadoop01:9000/json")
在Spark-Sell下啟用SQL報錯:error: not found: value sqlContext解決方案
在Spark2.X.X後,想要在Spark-shell中執行這個命令,你需要使用spark.sqlContext.sql()的形式。
將json資料直接讀取進來,直接變成dataframe
val df=spark.sqlContext.load("hdfs://hadoop01:9000/json","json")
parquet檔案型別
res1.select("id","name").save("hdfs://hadoop01:9000/out000")儲存在hdfs上面會產生parquet這類的檔案
df上面的一些方法

第二種構建dataframe的方法(通過StructType)
object SpecifyingSchema {
def main(args: Array[String]) {
//建立SparkConf()並設定App名稱
val conf = new SparkConf().setAppName("SQL-2")
//SQLContext要依賴SparkContext
val sc = new SparkContext(conf)
//建立SQLContext
val sqlContext = new SQLContext(sc)
//從指定的地址建立RDD
val personRDD = sc.textFile(args(0)).map(_.split(" "))
//通過StructType直接指定每個欄位的schema
val schema = StructType(
List(
StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
)
)
//將RDD對映到rowRDD
val rowRDD = personRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).toInt))
//將schema資訊應用到rowRDD上
val personDataFrame = sqlContext.createDataFrame(rowRDD, schema)
//登錄檔
personDataFrame.registerTempTable("t_person")
//執行SQL
val df = sqlContext.sql("select * from t_person order by age desc limit 4")
//將結果以JSON的方式儲存到指定位置
df.write.json(args(1))
//停止Spark Context
sc.stop()
}
}