
Spark定製版2:通過案例對SparkStreaming透徹理解三板斧之二
本節課主要從以下二個方面來解密SparkStreaming:
一、解密SparkStreaming執行機制
二、解密SparkStreaming架構
SparkStreaming執行時更像SparkCore上的應用程式,SparkStreaming程式啟動後會啟動很多job,每個batchIntval、windowByKey的job、框架執行啟動的job。例如,Receiver啟動時也啟動了job,此job為其他job服務,所以需要做複雜的spark程式,往往多個job之間互相配合。SparkStreaming是最複雜的應用程式,如果對SparkStreaming瞭如指掌的話,做其他的Spark應用程式沒有任何問題。看下官網:Spark sql,SparkStreaming,Spark ml,Spark graphx子框架都是後面開發出來的,我們要洞悉Spark Core 的話,SparkStreaming是最好的切入方式。
進入Spark官網,可以看到SparkCore和其他子框架的關係:
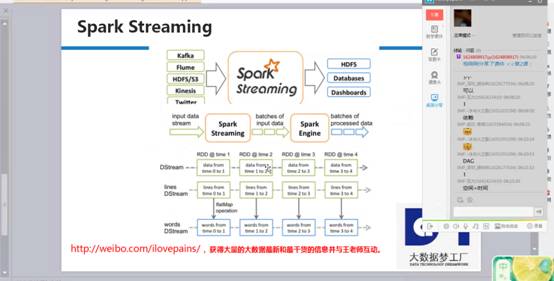
SparkStreaming啟動後,資料不斷通過inputStream流進來,根據時間劃分成不同的job、就是batchs of input data,每個job有一序列rdd的依賴。Rdd的依賴有輸入的資料,所以這裡就是不同的rdd依賴構成的batch,這些batch是不同的job,根據spark引擎來得出一個個結果。DStream是邏輯級別的,而RDD是物理級別的。DStream是隨著時間的流動內部將集合封裝RDD。對DStream的操作,轉過來是對其內部的RDD操作。
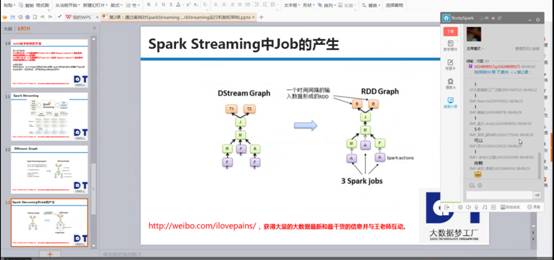
我是使用SparkCore 程式設計都是基於rdd程式設計,rdd間有依賴關係,如下圖右側的依賴關係圖,SparkStreaming執行時,根據時間為維度不斷的執行。Rdd的dag依賴是空間維度,而DStream在rdd的基礎上加上了時間維度,所以構成了SparkStreaming的時空維度。
SparkStreaming在rdd的基礎上增加了時間維度,執行時可以清晰看到jobscheduler、mappartitionrdd、shuffledrdd、blockmaanager等等,這些都是SparkCore的內容,而DStream、jobgenerator、socketInputDstream等等都是SparkStreaming的內容,如下圖執行過程可以很清晰的看到:

現在通過SparkStreaming的時空維度來細緻說明SparkStreaming執行機制

時間維度:按照固定時間間隔不斷地產生job物件,並在叢集上執行:
包含有batch interval,視窗長度,視窗滑動時間等
空間維度:代表的是RDD的依賴關係構成的具體的處理邏輯的步驟,是用DStream來表示的:
1、需要RDD,DAG的生成模板
2、TimeLine的job控制器、
3、InputStream和outputstream代表的資料輸入輸出
4、具體Job執行在Spark Cluster之上,此時系統容錯就至關重要
5、事務處理,在處理出現奔潰的情況下保證Exactly once的事務語義一致性
隨著時間的流動,基於DStream Graph不斷生成RDD Graph,也就是DAG的方式生成job,並通過Job Scheduler的執行緒池的方式提交給Spark Cluster不斷的執行,
由上圖可知,RDD 與 DStream之間的關係如下:
1、RDD是物理級別的,而 DStream 是邏輯級別的;
2、DStream是RDD的封裝模板類,是RDD進一步的抽象;
3、DStream要依賴RDD進行具體的資料計算;
Spark Streaming原始碼解析
1、StreamingContext方法中呼叫JobScheduler的start方法:
val ssc = new StreamingContext(conf, Seconds(5))
val lines = ssc.socketTextStream("Master", 9999)
......//業務處理程式碼略
ssc.start()
ssc.awaitTermination()
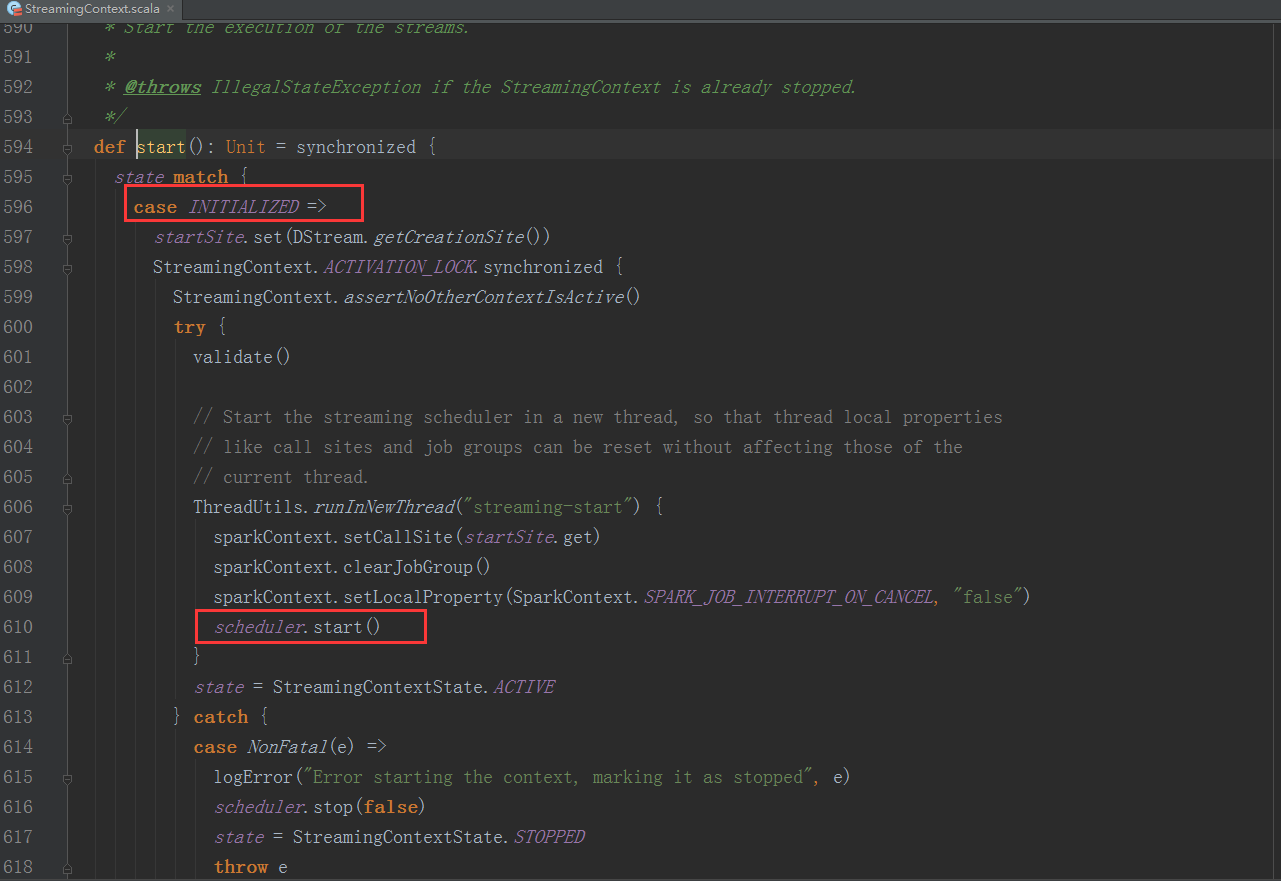
我們進入JobScheduler start方法的內部繼續分析:
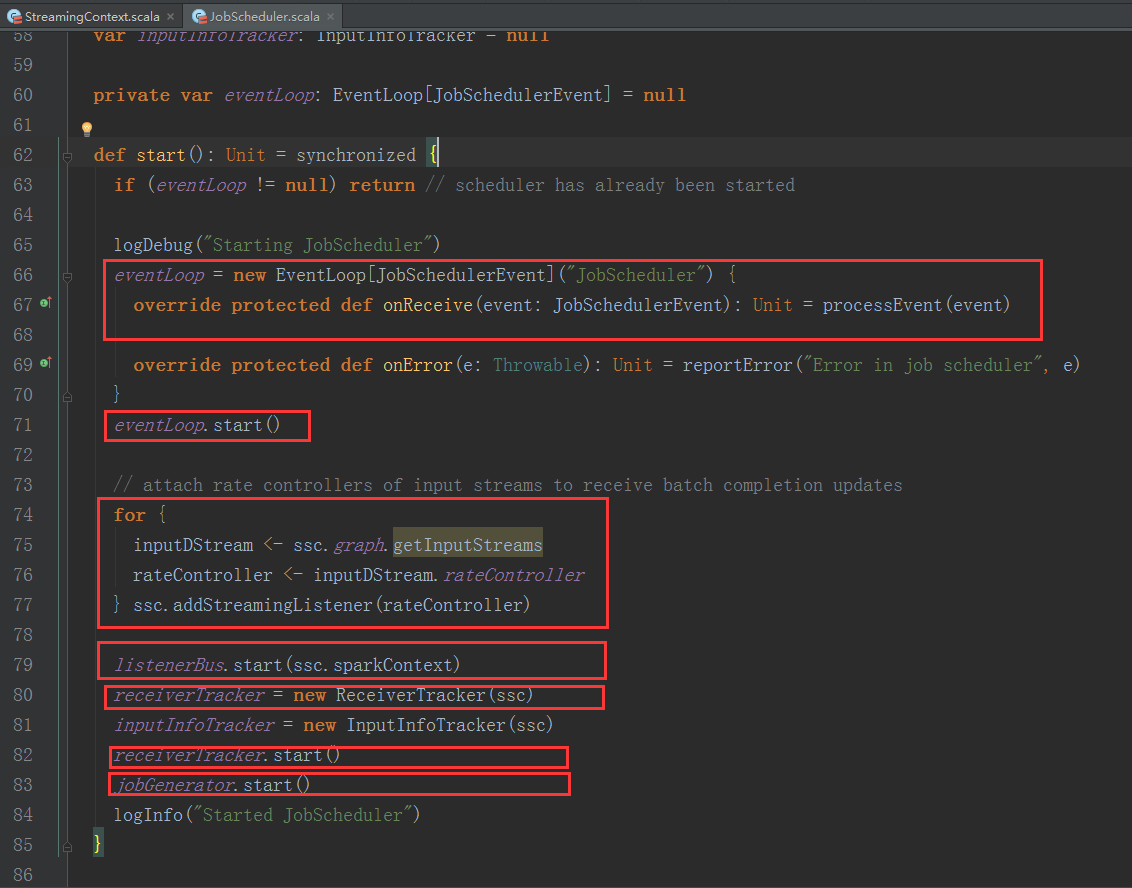
1、JobScheduler 通過onReceive方法接收各種訊息並存入enventLoop訊息迴圈體中。
2、通過rateController對流入SparkStreaming的資料進行限流控制。
3、在JobScheduler的start內部會構造JobGenerator和ReceiverTacker,並且呼叫JobGenerator和ReceiverTacker的start方法。
ReceiverTacker的啟動方法:

1、ReceiverTracker啟動後會建立ReceiverTrackerEndpoint這個訊息迴圈體,來接收執行在Executor上的Receiver傳送過來的訊息。
2、ReceiverTracker啟動後會在Spark Cluster中啟動executor中的Receivers。
JobGenerator的啟動方法:

1、JobGenerator啟動後會啟動以batchInterval時間間隔傳送GenerateJobs訊息的定時器


有興趣想學習國內頂級整套Spark+Spark Streaming+Machine learning課程的,歡迎加我qq 471186150。共享視訊,價效比超高!