
Spark 入門之十二:再看Spark中的排程策略(Standlone)
資源排程是Spark中比較重要的內容,對排程的相關原理以及策略的瞭解對叢集的執行以及優化都會有很大的幫助,資源排程的方式有多種,Local,Standlone,Yarn,Mesos等,本文只針對Standlone的方式做簡介
幾個重要的概念
開始文章之前,再次對幾個核心的概念做一個總結
被呼叫物件
- Application:Spark 的應用程式,使用者提交後,Spark為App分配資源,將程式轉換並執行,其中Application包含一個Driver program和若干Executor
- Job:一個RDD Graph觸發的作業,往往由Spark Action運算元觸發,在SparkContext中通過runJob方法向Spark提交Job
Stage:每個Job會根據RDD的寬依賴關係被切分很多Stage, 每個Stage中包含一組相同的Task, 這一組Task也叫TaskSet
Task:一個分割槽對應一個Task,Task執行RDD中對應Stage中包含的運算元。Task被封裝好後放入Executor的執行緒池中執行
呼叫參與方
Driver:執行Application的main()函式並且建立SparkContext
Worker Node:叢集中任何可以執行Application程式碼的節點,執行一個或多個Executor程序
- Executor:是為Application執行在Worker node上的一個程序,該程序負責執行Task,並且負責將資料存在記憶體或者磁碟上。每個Application都會申請各自的Executor來處理任務
SparkContext:Spark 應用程式的入口,負責排程各個運算資源,協調各個 WorkerNode 上的 Executor
DAGScheduler:根據Job構建基於Stage的DAG,並提交Stage給TaskScheduler
- TaskScheduler:將Taskset提交給Worker node叢集執行並返回結果,一個應用對應一個TaskScheduler
- TaskSetManager:每個Stage對應一個TaskSetManager,排程的時候以TaskSetManager為排程單位
- ExecutorBackend:在Worker上執行Task的執行緒組
- SchedulerBackend:主要用來與Worker中的ExecutorBackend建立連線,用來向Executor傳送要執行任務,或是接受執行任務的結果,也可以用來建立AppClient(包裝App資訊,包含可以建立CoarseGrainedExecutorBackend例項Command),用於向Master彙報資源需求
SparkContext的初始化以及互動
SparkContext的初始化
SparkContext是開發Spark應用的入口,它負責和整個叢集的互動,包括建立RDD,accumulators and broadcast variables。理解Spark的架構,需要從這個入口開始。下圖是官網的架構圖。
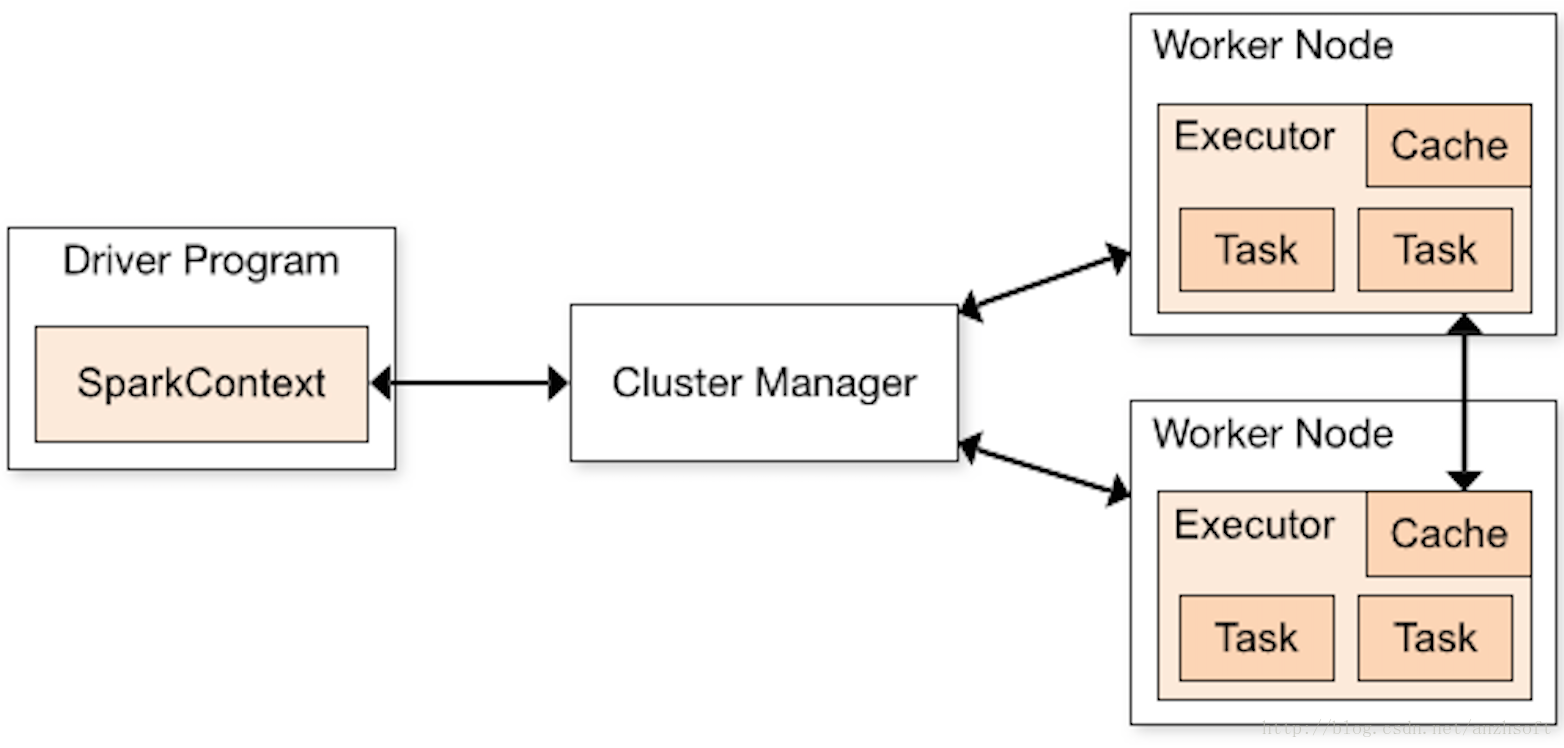
DriverProgram就是使用者提交的程式,這裡邊定義了SparkContext的例項。SparkContext定義在core/src/main/scala/org/apache/spark/SparkContext.scala。
SparkContext的主要初始化工作,主要是在SparkContext.scala的一個超大的try…catch 塊中,其中主要完成了以下幾件事情
- SparkConf的檢測,包括預設值的設定
- EventLog的初始化
- 狀態檢測物件的初始化
- Application WebUI的初始化
- Executor環境變數的配置
- 啟動心跳維持監聽actor,因為executors需要同driver維持心跳
- 呼叫createTaskScheduler方法,根據masters uri的格式,確定schedulerBackend和taskScheduler的取值,該過程還會呼叫schedtaskScheduler的initialize方法確定task pool的排程演算法
- 由AppClient/ClientActor代理,同masters互動,確定可用master,由後者代理獲取並啟動workers上的可用executors資源
- 呼叫_taskScheduler.start()方法,該方法會呼叫SparkDeploySchedulerBackend的start方法,該方法會使用appDescription啟動executor子程序
元件間的互動
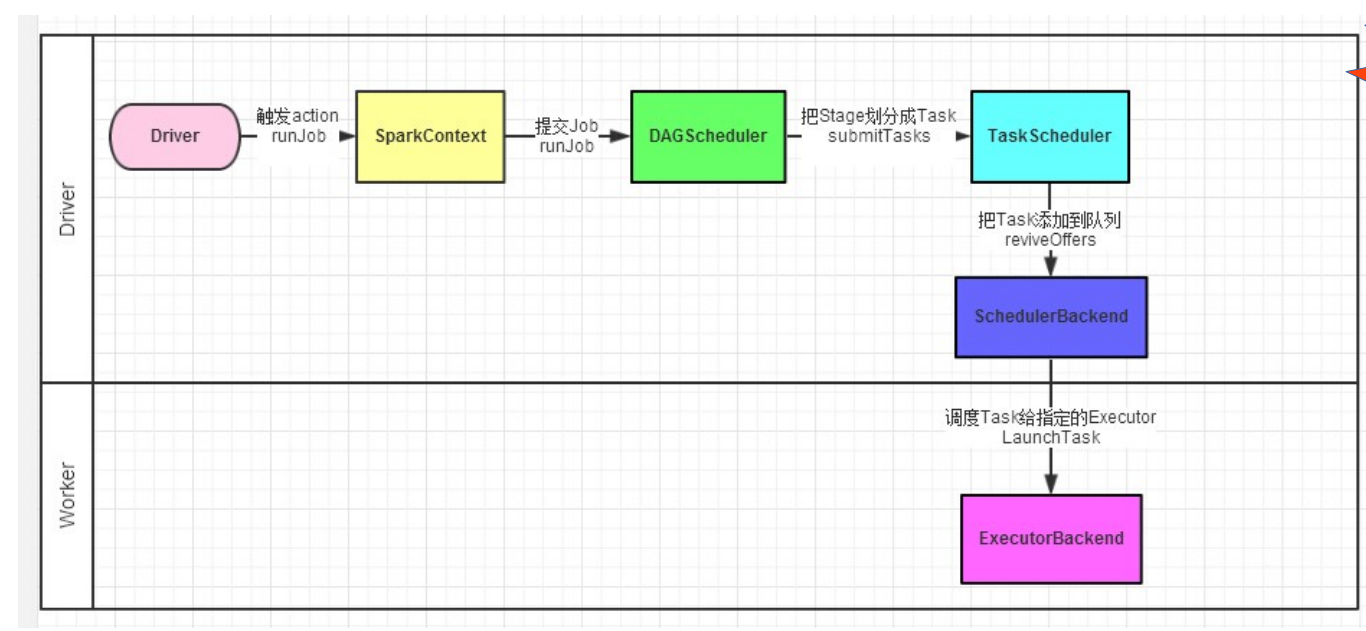
提交一個JOB
下面的圖說明了在一個JOB提交的過程中涉及到的元件以及互動過程
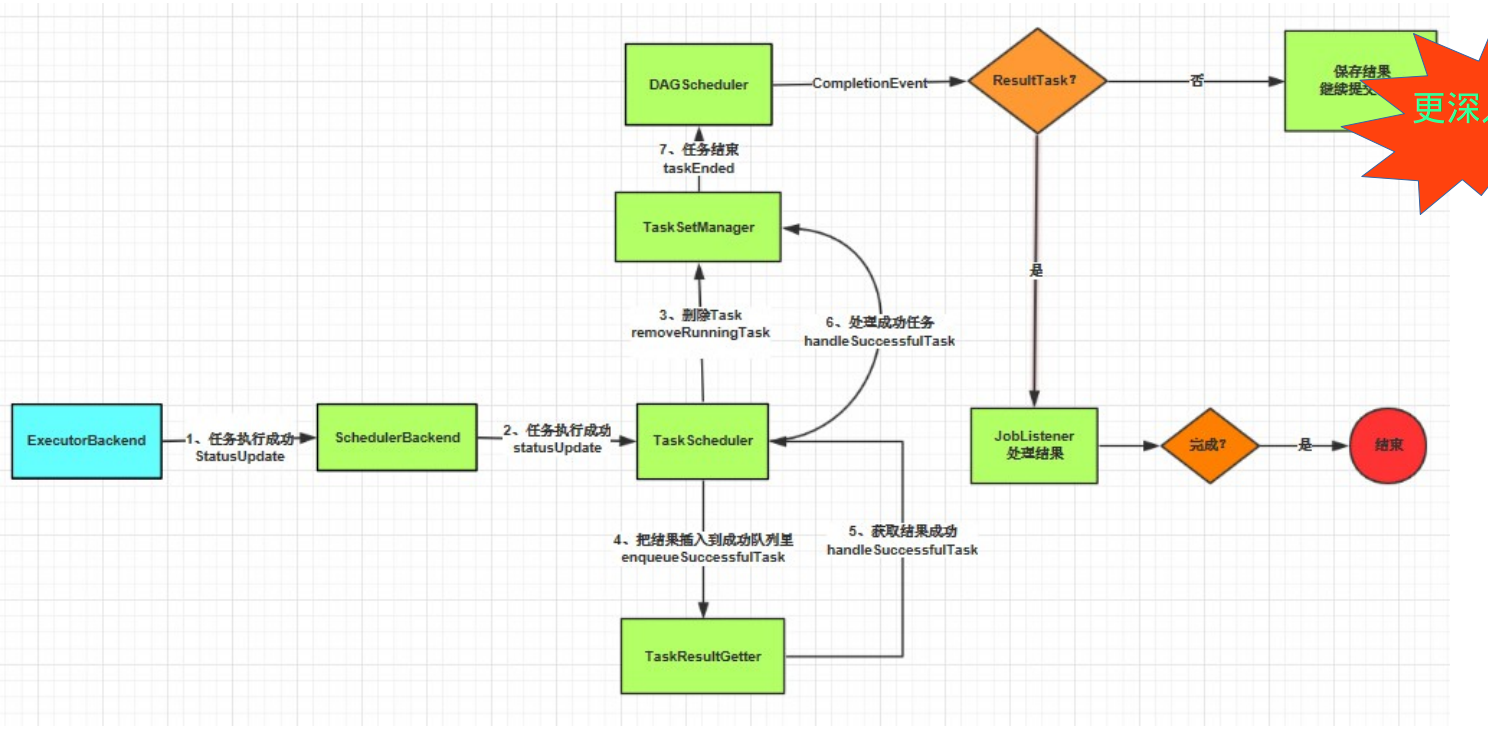
Executor返回執行結果
下面的圖說明了在一個JOB執行返回的過程
幾個重要的排程規則
APP排程
預設情況下,使用者向以Standalone模式執行的Spark叢集提交的應用使用FIFO(先進先
出)的順序進行排程。 每個應用會獨佔所有可用節點的資源。 使用者可以通過配置引數
spark.cores.max決定一個應用可以在整個叢集申請的CPU core數。 注意,這個引數不是控
制單節點可用多少核。 如果使用者沒有配置這個引數,則在Standalone模式下,預設每個應用
可以分配由引數spark.deploy.defaultCores決定的可用核數。
演算法對應的類
- FIFO:FIFOSchedulingAlgorithm
- FAIR:FairSchedulingAlgorithm
JOB排程
Action 觸發的JOB的本質就是呼叫了SparkContent 的runjob方法。JOB的排程在FIFO與FAIR的行為有點不同
FIFO
在預設情況下,Spark的排程器以FIFO(先進先出)方式排程Job的執行。 每個Job被切分為多個Stage。 第一個Job優先獲取所有可用的資源,接下來第二個Job再獲取剩餘資源。 以此類推,如果第一個Job並沒有佔用所有的資源,則第二個Job還可以繼續獲取剩餘資源,這樣多個Job可以並行執行。 如果第一個Job很大,佔用所有資源,則第二個Job就需要等待第一個任務執行完,釋放空餘資源,再申請和分配Job。
FAIR
在FAIR共享模式排程下,Spark在多Job之間以輪詢(round robin)方式為任務分配資源,所有的任務擁有大致相當的優先順序來共享叢集的資源。
這就意味著當一個長任務正在執行時,短任務仍可以分配到資源,提交併執行,並且獲得不錯的響應時間。 這樣就不用像以前一樣需要等待長任務執行完才可以。 這種排程模式很適合多使用者的場景。
使用者可以通過配置spark.scheduler.mode方式來讓應用以FAIR模式排程。
FAIR排程器同樣支援將Job分組加入排程池中排程,使用者可以同時針對不同優先順序對每個排程池配置不同的排程權重
在預設情況下,每個排程池擁有相同的優先順序來共享整個叢集的資源,同樣default pool中的每個Job也擁有同樣優先順序進行資源共享,但是在使用者建立的每個資源池中,Job是通過FIFO方式進行排程的。
Stage排程
每個Stage對應的一個TaskSetManager,通過Stage回溯到最源頭缺失的Stage提交到排程池pool中,在排程池中,
這些TaskSetMananger又會根據Job ID排序,先提交的Job的TaskSetManager優先排程,然
後一個Job內的TaskSetManager ID小的先排程,並且如果有未執行完的父母Stage的
TaskSetManager,則是不會提交到排程池中。
Task排程
當Stage不存在缺失的ParentStage時,會將其轉換為TaskSet並提交。轉換時依Stage型別進行轉換:將ResultStage轉換成ResultTask, ShuffleMapStage轉換成ShuffleMapTask. Task個數由Stage中finalRDD 的分割槽數決定。
當轉換成的TaskSet提交之後,將其通過taskScheduler包裝成TaskSetManager並新增至排程佇列中(Pool),等待排程。在包裝成TaskSetManager時,根據task的preferredLocatitions將任務分類存放在pendingTasksForExecutor, pendingTaskForHost, pendingTasksForRack, pendingTaskWithNoPrefs及allPendingTasks中, 前三個列表是是包含關係(本地性越來越低),範圍起來越大,例如:在pendingTasksForExecutor也在pendingTaskForHost,pendingTasksForRack中, 分類的目的是在排程時,依次由本地性高à低的查詢task。
在進行Task排程時,首先根據排程策略將可排程所有taskset進行排序,然後對排好序的taskset待排程列表中的taskset,按序進行分配Executor。再分配Executor時,然後逐個為Executor列表中可用的Executor在此次選擇的taskset中==按本地性由高到低查詢適配任==務。此處任務排程為延遲排程,即若本次排程時間距上一任務結束時間小於當前本地性配製時間則等待,若過了配製時間,本地性要求逐漸降低,再去查詢適配的task。當選定某一task後後將其加入runningtask列表,當其執行完成時會加入success列表,下次排程時就會過濾過存在這兩個列表中的任務,避免重複排程。
當一個任務執行結束時,會將其從runningtask中移除,並加入success,並會適放其佔用的執行資源,供後序task使用, 將判斷其執行成功的task數與此taskset任務總數相等時,意為taskset中所有任務執行結束,也就是taskset結束。此時會將taskset移除出可排程佇列。
重複上述過程直到taskset待排程列表為空。即所有作業(job)執行完成。
總結:整體的Task分發由TaskSchedulerImpl來實現,但是Task的排程(本質上是Task在哪個
分割槽執行)邏輯由TaskSetManager完成。 這個類監控整個任務的生命週期,當任務失敗時
(如執行時間超過一定的閾值),重新排程,也會通過delay scheduling進行基於位置感知
(locality-aware)的任務排程