
資料結構--七大查詢演算法總結
當查詢不成功時,需要n+1次比較,時間複雜度為O(n); 所以,順序查詢的時間複雜度為O(n)。 C++實現原始碼:
int SequenceSearch(int a[], int value, int n)
{
int i;
for(i=0; i<n; i++)
if(a[i]==value)
return i;
return -1;
}
2. 二分查詢
說明:元素必須是有序的,如果是無序的則要先進行排序操作。
基本思想:也稱為是折半查詢,屬於有序查詢演算法。用給定值k先與中間結點的關鍵字比較,中間結點把線形表分成兩個子表,若相等則查詢成功;若不相等,再根據k與該中間結點關鍵字的比較結果確定下一步查詢哪個子表,這樣遞迴進行,直到查詢到或查詢結束髮現表中沒有這樣的結點。
複雜度分析:最壞情況下,關鍵詞比較次數為log2(n+1),且期望時間複雜度為O(log2n);
注:折半查詢的前提條件是需要有序表順序儲存,對於靜態查詢表,一次排序後不再變化,折半查詢能得到不錯的效率。但對於需要頻繁執行插入或刪除操作的資料集來說,維護有序的排序會帶來不小的工作量,那就不建議使用。——《大話資料結構》
C++實現原始碼:
//二分查詢(折半查詢),版本1
int BinarySearch1(int a[], int value, int n)
{
int low, high, mid;
low = 0;
high = n-1;
while(low<=high)
{
mid = (low+high)/2;
if(a[mid]==value)
return mid;
if(a[mid]>value)
high = mid-1;
if(a[mid]<value)
low = mid+1;
}
return -1;
}
//二分查詢,遞迴版本
int BinarySearch2(int a[], int value, int low, int high)
{
int mid = low+(high-low)/2;
if(a[mid]==value)
return mid;
if(a[mid]>value)
return BinarySearch2(a, value, low, mid-1);
if(a[mid]<value)
return BinarySearch2(a, value, mid+1, high);
}3. 插值查詢
在介紹插值查詢之前,首先考慮一個新問題,為什麼上述演算法一定要是折半,而不是折四分之一或者折更多呢? 打個比方,在英文字典裡面查“apple”,你下意識翻開字典是翻前面的書頁還是後面的書頁呢?如果再讓你查“zoo”,你又怎麼查?很顯然,這裡你絕對不會是從中間開始查起,而是有一定目的的往前或往後翻。 同樣的,比如要在取值範圍1 ~ 10000 之間 100 個元素從小到大均勻分佈的陣列中查詢5, 我們自然會考慮從陣列下標較小的開始查詢。 經過以上分析,折半查詢這種查詢方式,不是自適應的(也就是說是傻瓜式的)。二分查詢中查詢點計算如下: mid=(low+high)/2, 即mid=low+1/2*(high-low); 通過類比,我們可以將查詢的點改進為如下: mid=low+(key-a[low])/(a[high]-a[low])*(high-low), 也就是將上述的比例引數1/2改進為自適應的,根據關鍵字在整個有序表中所處的位置,讓mid值的變化更靠近關鍵字key,這樣也就間接地減少了比較次數。 基本思想://插值查詢
int InsertionSearch(int a[], int value, int low, int high)
{
int mid = low+(value-a[low])/(a[high]-a[low])*(high-low);
if(a[mid]==value)
return mid;
if(a[mid]>value)
return InsertionSearch(a, value, low, mid-1);
if(a[mid]<value)
return InsertionSearch(a, value, mid+1, high);
}
4. 斐波那契查詢
在介紹斐波那契查詢演算法之前,我們先介紹一下很它緊密相連並且大家都熟知的一個概念——黃金分割。
黃金比例又稱黃金分割,是指事物各部分間一定的數學比例關係,即將整體一分為二,較大部分與較小部分之比等於整體與較大部分之比,其比值約為1:0.618或1.618:1。
0.618被公認為最具有審美意義的比例數字,這個數值的作用不僅僅體現在諸如繪畫、雕塑、音樂、建築等藝術領域,而且在管理、工程設計等方面也有著不可忽視的作用。因此被稱為黃金分割。
大家記不記得斐波那契數列:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89…….(從第三個數開始,後邊每一個數都是前兩個數的和)。然後我們會發現,隨著斐波那契數列的遞增,前後兩個數的比值會越來越接近0.618,利用這個特性,我們就可以將黃金比例運用到查詢技術中。

1)相等,mid位置的元素即為所求
2)>,low=mid+1;
3)<,high=mid-1。
斐波那契查詢與折半查詢很相似,他是根據斐波那契序列的特點對有序表進行分割的。他要求開始表中記錄的個數為某個斐波那契數小1,及n=F(k)-1;
開始將k值與第F(k-1)位置的記錄進行比較(及mid=low+F(k-1)-1),比較結果也分為三種
1)相等,mid位置的元素即為所求
2)>,low=mid+1,k-=2;
說明:low=mid+1說明待查詢的元素在[mid+1,high]範圍內,k-=2 說明範圍[mid+1,high]內的元素個數為n-(F(k-1))= Fk-1-F(k-1)=Fk-F(k-1)-1=F(k-2)-1個,所以可以遞迴的應用斐波那契查詢。
3)<,high=mid-1,k-=1。
說明:low=mid+1說明待查詢的元素在[low,mid-1]範圍內,k-=1 說明範圍[low,mid-1]內的元素個數為F(k-1)-1個,所以可以遞迴 的應用斐波那契查詢。
複雜度分析:最壞情況下,時間複雜度為O(log2n),且其期望複雜度也為O(log2n)。C++實現原始碼:
// 斐波那契查詢.cpp
#include "stdafx.h"
#include <memory>
#include <iostream>
using namespace std;
const int max_size=20;//斐波那契陣列的長度
/*構造一個斐波那契陣列*/
void Fibonacci(int * F)
{
F[0]=0;
F[1]=1;
for(int i=2;i<max_size;++i)
F[i]=F[i-1]+F[i-2];
}
/*定義斐波那契查詢法*/
int FibonacciSearch(int *a, int n, int key) //a為要查詢的陣列,n為要查詢的陣列長度,key為要查詢的關鍵字
{
int low=0;
int high=n-1;
int F[max_size];
Fibonacci(F);//構造一個斐波那契陣列F
int k=0;
while(n>F[k]-1)//計算n位於斐波那契數列的位置
++k;
int * temp;//將陣列a擴充套件到F[k]-1的長度
temp=new int [F[k]-1];
memcpy(temp,a,n*sizeof(int));
for(int i=n;i<F[k]-1;++i)
temp[i]=a[n-1];
while(low<=high)
{
int mid=low+F[k-1]-1;
if(key<temp[mid])
{
high=mid-1;
k-=1;
}
else if(key>temp[mid])
{
low=mid+1;
k-=2;
}
else
{
if(mid<n)
return mid; //若相等則說明mid即為查詢到的位置
else
return n-1; //若mid>=n則說明是擴充套件的數值,返回n-1
}
}
delete [] temp;
return -1;
}
int main()
{
int a[] = {0,16,24,35,47,59,62,73,88,99};
int key=100;
int index=FibonacciSearch(a,sizeof(a)/sizeof(int),key);
cout<<key<<" is located at:"<<index;
return 0;
}
5. 樹表查詢
5.1 最簡單的樹表查詢演算法——二叉樹查詢演算法。
基本思想:二叉查詢樹是先對待查詢的資料進行生成樹,確保樹的左分支的值小於右分支的值,然後在就行和每個節點的父節點比較大小,查詢最適合的範圍。 這個演算法的查詢效率很高,但是如果使用這種查詢方法要首先建立樹。
二叉查詢樹(BinarySearch Tree,也叫二叉搜尋樹,或稱二叉排序樹Binary Sort Tree)或者是一棵空樹,或者是具有下列性質的二叉樹:
1)若任意節點的左子樹不空,則左子樹上所有結點的值均小於它的根結點的值;
2)若任意節點的右子樹不空,則右子樹上所有結點的值均大於它的根結點的值;
3)任意節點的左、右子樹也分別為二叉查詢樹。
二叉查詢樹性質:對二叉查詢樹進行中序遍歷,即可得到有序的數列。
不同形態的二叉查詢樹如下圖所示:
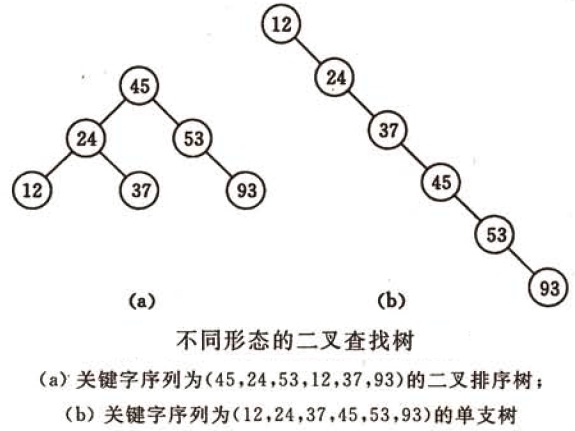
有關二叉查詢樹的查詢、插入、刪除等操作的詳細講解,請移步淺談演算法和資料結構: 七 二叉查詢樹。
複雜度分析:它和二分查詢一樣,插入和查詢的時間複雜度均為O(logn),但是在最壞的情況下仍然會有O(n)的時間複雜度。原因在於插入和刪除元素的時候,樹沒有保持平衡(比如,我們查詢上圖(b)中的“93”,我們需要進行n次查詢操作)。我們追求的是在最壞的情況下仍然有較好的時間複雜度,這就是平衡查詢樹設計的初衷。
下圖為二叉樹查詢和順序查詢以及二分查詢效能的對比圖:

基於二叉查詢樹進行優化,進而可以得到其他的樹表查詢演算法,如平衡樹、紅黑樹等高效演算法。
5.2 平衡查詢樹之2-3查詢樹(2-3 Tree)
2-3查詢樹定義:和二叉樹不一樣,2-3樹執行每個節點儲存1個或者兩個的值。對於普通的2節點(2-node),他儲存1個key和左右兩個自己點。對應3節點(3-node),儲存兩個Key,2-3查詢樹的定義如下:
1)要麼為空,要麼:
2)對於2節點,該節點儲存一個key及對應value,以及兩個指向左右節點的節點,左節點也是一個2-3節點,所有的值都比key要小,右節點也是一個2-3節點,所有的值比key要大。
3)對於3節點,該節點儲存兩個key及對應value,以及三個指向左中右的節點。左節點也是一個2-3節點,所有的值均比兩個key中的最小的key還要小;中間節點也是一個2-3節點,中間節點的key值在兩個跟節點key值之間;右節點也是一個2-3節點,節點的所有key值比兩個key中的最大的key還要大。

2-3查詢樹的性質:
1)如果中序遍歷2-3查詢樹,就可以得到排好序的序列;
2)在一個完全平衡的2-3查詢樹中,根節點到每一個為空節點的距離都相同。(這也是平衡樹中“平衡”一詞的概念,根節點到葉節點的最長距離對應於查詢演算法的最壞情況,而平衡樹中根節點到葉節點的距離都一樣,最壞情況也具有對數複雜度。)
性質2)如下圖所示:

複雜度分析:
2-3樹的查詢效率與樹的高度是息息相關的。
- 在最壞的情況下,也就是所有的節點都是2-node節點,查詢效率為lgN
- 在最好的情況下,所有的節點都是3-node節點,查詢效率為log3N約等於0.631lgN
距離來說,對於1百萬個節點的2-3樹,樹的高度為12-20之間,對於10億個節點的2-3樹,樹的高度為18-30之間。
對於插入來說,只需要常數次操作即可完成,因為他只需要修改與該節點關聯的節點即可,不需要檢查其他節點,所以效率和查詢類似。下面是2-3查詢樹的效率:

5.3 平衡查詢樹之紅黑樹(Red-Black Tree)
2-3查詢樹能保證在插入元素之後能保持樹的平衡狀態,最壞情況下即所有的子節點都是2-node,樹的高度為lgn,從而保證了最壞情況下的時間複雜度。但是2-3樹實現起來比較複雜,於是就有了一種簡單實現2-3樹的資料結構,即紅黑樹(Red-Black Tree)。
基本思想:紅黑樹的思想就是對2-3查詢樹進行編碼,尤其是對2-3查詢樹中的3-nodes節點新增額外的資訊。紅黑樹中將節點之間的連結分為兩種不同型別,紅色連結,他用來連結兩個2-nodes節點來表示一個3-nodes節點。黑色連結用來連結普通的2-3節點。特別的,使用紅色連結的兩個2-nodes來表示一個3-nodes節點,並且向左傾斜,即一個2-node是另一個2-node的左子節點。這種做法的好處是查詢的時候不用做任何修改,和普通的二叉查詢樹相同。

紅黑樹的定義:
紅黑樹是一種具有紅色和黑色連結的平衡查詢樹,同時滿足:
- 紅色節點向左傾斜
- 一個節點不可能有兩個紅色連結
- 整個樹完全黑色平衡,即從根節點到所以葉子結點的路徑上,黑色連結的個數都相同。
下圖可以看到紅黑樹其實是2-3樹的另外一種表現形式:如果我們將紅色的連線水平繪製,那麼他連結的兩個2-node節點就是2-3樹中的一個3-node節點了。

紅黑樹的性質:整個樹完全黑色平衡,即從根節點到所以葉子結點的路徑上,黑色連結的個數都相同(2-3樹的第2)性質,從根節點到葉子節點的距離都相等)。
複雜度分析:最壞的情況就是,紅黑樹中除了最左側路徑全部是由3-node節點組成,即紅黑相間的路徑長度是全黑路徑長度的2倍。
下圖是一個典型的紅黑樹,從中可以看到最長的路徑(紅黑相間的路徑)是最短路徑的2倍:

紅黑樹的平均高度大約為logn。
下圖是紅黑樹在各種情況下的時間複雜度,可以看出紅黑樹是2-3查詢樹的一種實現,它能保證最壞情況下仍然具有對數的時間複雜度。

紅黑樹這種資料結構應用十分廣泛,在多種程式語言中被用作符號表的實現,如:
- Java中的java.util.TreeMap,java.util.TreeSet;
- C++ STL中的:map,multimap,multiset;
- .NET中的:SortedDictionary,SortedSet 等。
5.4 B樹和B+樹(B Tree/B+ Tree)
平衡查詢樹中的2-3樹以及其實現紅黑樹。2-3樹種,一個節點最多有2個key,而紅黑樹則使用染色的方式來標識這兩個key。
維基百科對B樹的定義為“在電腦科學中,B樹(B-tree)是一種樹狀資料結構,它能夠儲存資料、對其進行排序並允許以O(log n)的時間複雜度執行進行查詢、順序讀取、插入和刪除的資料結構。B樹,概括來說是一個節點可以擁有多於2個子節點的二叉查詢樹。與自平衡二叉查詢樹不同,B樹為系統最優化大塊資料的讀和寫操作。B-tree演算法減少定位記錄時所經歷的中間過程,從而加快存取速度。普遍運用在資料庫和檔案系統。
B樹定義:
B樹可以看作是對2-3查詢樹的一種擴充套件,即他允許每個節點有M-1個子節點。
-
根節點至少有兩個子節點
-
每個節點有M-1個key,並且以升序排列
-
位於M-1和M key的子節點的值位於M-1 和M key對應的Value之間
-
其它節點至少有M/2個子節點
下圖是一個M=4 階的B樹:

可以看到B樹是2-3樹的一種擴充套件,他允許一個節點有多於2個的元素。B樹的插入及平衡化操作和2-3樹很相似,這裡就不介紹了。下面是往B樹中依次插入
6 10 4 14 5 11 15 3 2 12 1 7 8 8 6 3 6 21 5 15 15 6 32 23 45 65 7 8 6 5 4
的演示動畫:

B+樹定義:
B+樹是對B樹的一種變形樹,它與B樹的差異在於:
- 有k個子結點的結點必然有k個關鍵碼;
- 非葉結點僅具有索引作用,跟記錄有關的資訊均存放在葉結點中。
- 樹的所有葉結點構成一個有序連結串列,可以按照關鍵碼排序的次序遍歷全部記錄。
如下圖,是一個B+樹:

下圖是B+樹的插入動畫:

B和B+樹的區別在於,B+樹的非葉子結點只包含導航資訊,不包含實際的值,所有的葉子結點和相連的節點使用連結串列相連,便於區間查詢和遍歷。
B+ 樹的優點在於:
- 由於B+樹在內部節點上不好含資料資訊,因此在記憶體頁中能夠存放更多的key。 資料存放的更加緊密,具有更好的空間區域性性。因此訪問葉子幾點上關聯的資料也具有更好的快取命中率。
- B+樹的葉子結點都是相鏈的,因此對整棵樹的便利只需要一次線性遍歷葉子結點即可。而且由於資料順序排列並且相連,所以便於區間查詢和搜尋。而B樹則需要進行每一層的遞迴遍歷。相鄰的元素可能在記憶體中不相鄰,所以快取命中性沒有B+樹好。
但是B樹也有優點,其優點在於,由於B樹的每一個節點都包含key和value,因此經常訪問的元素可能離根節點更近,因此訪問也更迅速。
下面是B 樹和B+樹的區別圖:

B/B+樹常用於檔案系統和資料庫系統中,它通過對每個節點儲存個數的擴充套件,使得對連續的資料能夠進行較快的定位和訪問,能夠有效減少查詢時間,提高儲存的空間區域性性從而減少IO操作。它廣泛用於檔案系統及資料庫中,如:
- Windows:HPFS檔案系統;
- Mac:HFS,HFS+檔案系統;
- Linux:ResiserFS,XFS,Ext3FS,JFS檔案系統;
- 資料庫:ORACLE,MYSQL,SQLSERVER等中。
有關B/B+樹在資料庫索引中的應用,請看張洋的MySQL索引背後的資料結構及演算法原理這篇文章,這篇文章對MySQL中的如何使用B+樹進行索引有比較詳細的介紹,推薦閱讀。
樹表查詢總結:
二叉查詢樹平均查詢效能不錯,為O(logn),但是最壞情況會退化為O(n)。在二叉查詢樹的基礎上進行優化,我們可以使用平衡查詢樹。平衡查詢樹中的2-3查詢樹,這種資料結構在插入之後能夠進行自平衡操作,從而保證了樹的高度在一定的範圍內進而能夠保證最壞情況下的時間複雜度。但是2-3查詢樹實現起來比較困難,紅黑樹是2-3樹的一種簡單高效的實現,他巧妙地使用顏色標記來替代2-3樹中比較難處理的3-node節點問題。紅黑樹是一種比較高效的平衡查詢樹,應用非常廣泛,很多程式語言的內部實現都或多或少的採用了紅黑樹。
除此之外,2-3查詢樹的另一個擴充套件——B/B+平衡樹,在檔案系統和資料庫系統中有著廣泛的應用。
6. 分塊查詢
分塊查詢又稱索引順序查詢,它是順序查詢的一種改進方法。
演算法思想:將n個數據元素"按塊有序"劃分為m塊(m ≤ n)。每一塊中的結點不必有序,但塊與塊之間必須"按塊有序";即第1塊中任一元素的關鍵字都必須小於第2塊中任一元素的關鍵字;而第2塊中任一元素又都必須小於第3塊中的任一元素,……
演算法流程:
step1 先選取各塊中的最大關鍵字構成一個索引表;
step2 查詢分兩個部分:先對索引表進行二分查詢或順序查詢,以確定待查記錄在哪一塊中;然後,在已確定的塊中用順序法進行查詢。
7. 雜湊查詢
什麼是雜湊表(Hash)?
我們使用一個下標範圍比較大的陣列來儲存元素。可以設計一個函式(雜湊函式, 也叫做雜湊函式),使得每個元素的關鍵字都與一個函式值(即陣列下標)相對應,於是用這個陣列單元來儲存這個元素;也可以簡單的理解為,按照關鍵字為每一個元素"分類",然後將這個元素儲存在相應"類"所對應的地方。但是,不能夠保證每個元素的關鍵字與函式值是一一對應的,因此極有可能出現對於不同的元素,卻計算出了相同的函式值,這樣就產生了"衝突",換句話說,就是把不同的元素分在了相同的"類"之中。後面我們將看到一種解決"衝突"的簡便做法。 總的來說,"直接定址"與"解決衝突"是雜湊表的兩大特點。什麼是雜湊函式?
雜湊函式的規則是:通過某種轉換關係,使關鍵字適度的分散到指定大小的的順序結構中,越分散,則以後查詢的時間複雜度越小,空間複雜度越高。
演算法思想:雜湊的思路很簡單,如果所有的鍵都是整數,那麼就可以使用一個簡單的無序陣列來實現:將鍵作為索引,值即為其對應的值,這樣就可以快速訪問任意鍵的值。這是對於簡單的鍵的情況,我們將其擴充套件到可以處理更加複雜的型別的鍵。
演算法流程:
1)用給定的雜湊函式構造雜湊表; 2)根據選擇的衝突處理方法解決地址衝突; 常見的解決衝突的方法:拉鍊法和線性探測法。詳細的介紹可以參見:淺談演算法和資料結構: 十一 雜湊表。 3)在雜湊表的基礎上執行雜湊查詢。 雜湊表是一個在時間和空間上做出權衡的經典例子。如果沒有記憶體限制,那麼可以直接將鍵作為陣列的索引。那麼所有的查詢時間複雜度為O(1);如果沒有時間限制,那麼我們可以使用無序陣列並進行順序查詢,這樣只需要很少的記憶體。雜湊表使用了適度的時間和空間來在這兩個極端之間找到了平衡。只需要調整雜湊函式演算法即可在時間和空間上做出取捨。複雜度分析:
單純論查詢複雜度:對於無衝突的Hash表而言,查詢複雜度為O(1)(注意,在查詢之前我們需要構建相應的Hash表)。
使用Hash,我們付出了什麼?
我們在實際程式設計中儲存一個大規模的資料,最先想到的儲存結構可能就是map,也就是我們常說的KV pair,經常使用Python的博友可能更有這種體會。使用map的好處就是,我們在後續處理資料處理時,可以根據資料的key快速的查詢到對應的value值。map的本質就是Hash表,那我們在獲取了超高查詢效率的基礎上,我們付出了什麼?
Hash是一種典型以空間換時間的演算法,比如原來一個長度為100的陣列,對其查詢,只需要遍歷且匹配相應記錄即可,從空間複雜度上來看,假如陣列儲存的是byte型別資料,那麼該陣列佔用100byte空間。現在我們採用Hash演算法,我們前面說的Hash必須有一個規則,約束鍵與儲存位置的關係,那麼就需要一個固定長度的hash表,此時,仍然是100byte的陣列,假設我們需要的100byte用來記錄鍵與位置的關係,那麼總的空間為200byte,而且用於記錄規則的表大小會根據規則,大小可能是不定的。
Hash演算法和其他查詢演算法的效能對比:
