
訊息佇列面試相關
(1)為什麼使用訊息佇列啊?
其實就是問問你訊息佇列都有哪些使用場景,然後你專案裡具體是什麼場景,說說你在這個場景裡用訊息佇列是什麼
面試官問你這個問題,期望的一個回答是說,你們公司有個什麼業務場景,這個業務場景有個什麼技術挑戰,如果不用MQ可能會很麻煩,但是你現在用了MQ之後帶給了你很多的好處
先說一下訊息佇列的常見使用場景吧,其實場景有很多,但是比較核心的有3個:解耦、非同步、削峰
解耦:現場畫個圖來說明一下,
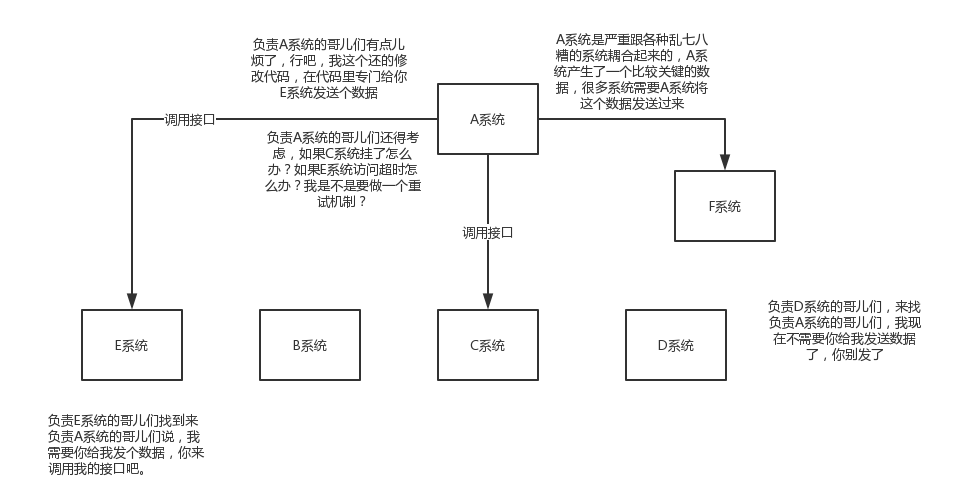
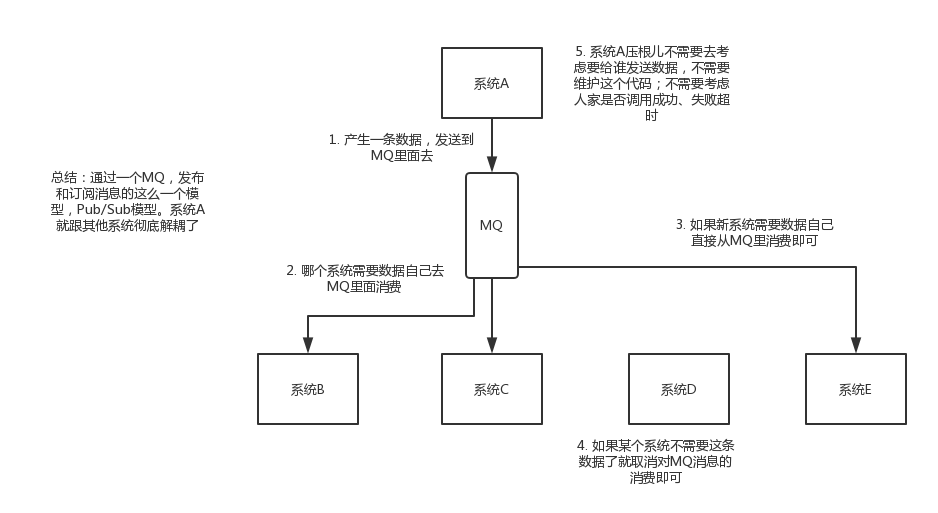
面試技巧:你需要去考慮一下你負責的系統中是否有類似的場景,就是一個系統或者一個模組,呼叫了多個系統或者模組,互相之間的呼叫很複雜,維護起來很麻煩。但是其實這個呼叫是不需要直接同步呼叫介面的,如果用MQ給他非同步化解耦,也是可以的,你就需要去考慮在你的專案裡,是不是可以運用這個MQ去進行系統的解耦。在簡歷中體現出來這塊東西,用MQ作解耦。
非同步:現場畫個圖來說明一下,
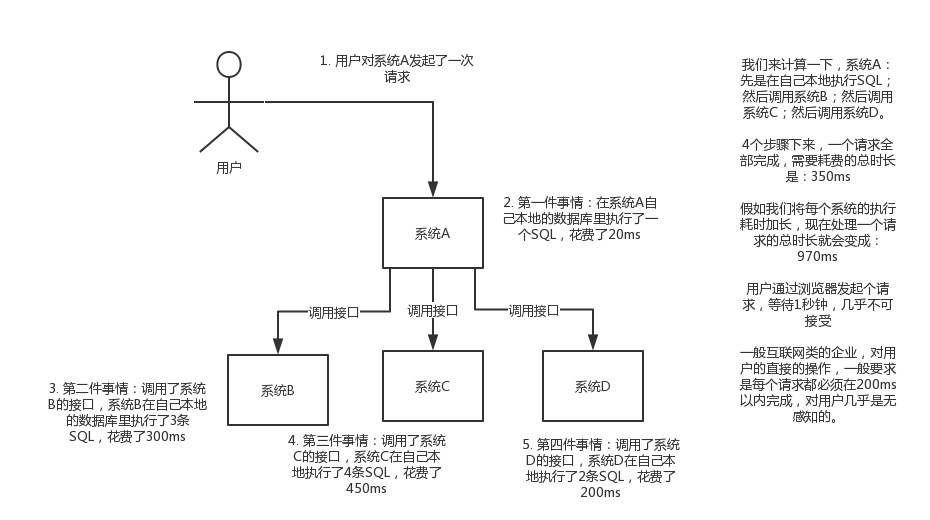
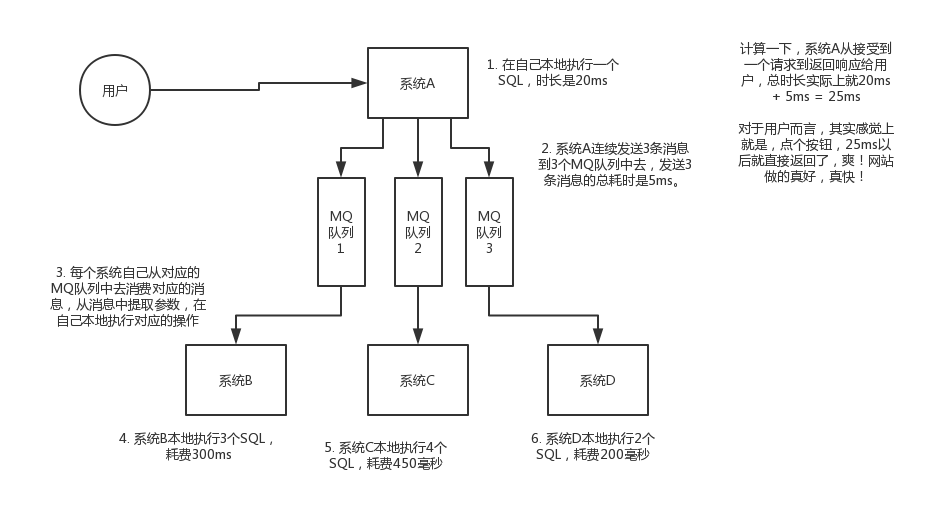
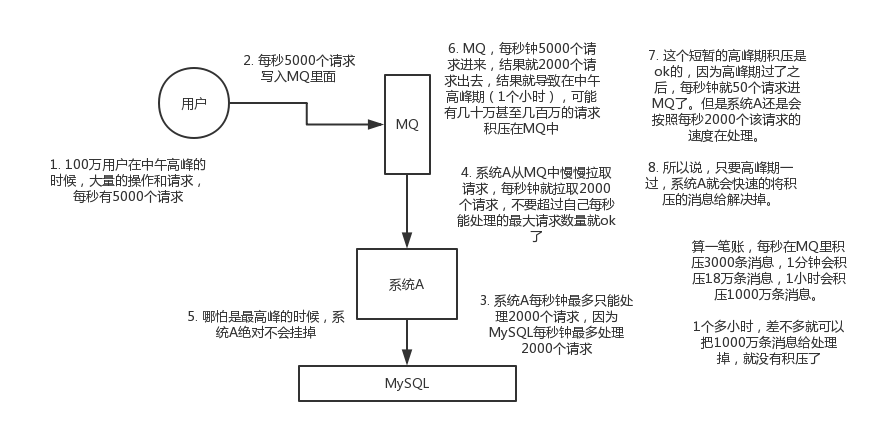
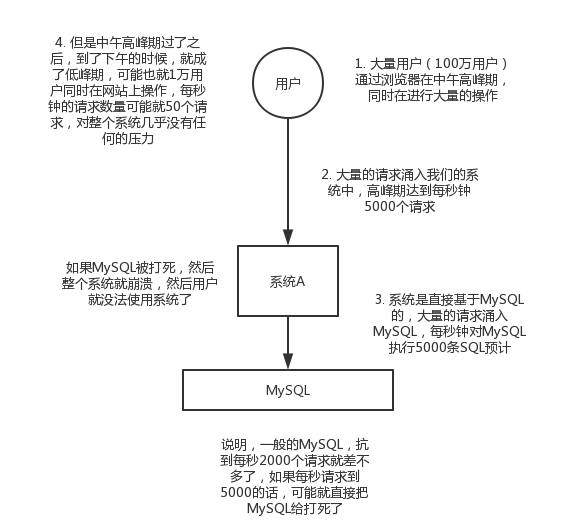
削峰:每天0點到11點,A系統風平浪靜,每秒併發請求數量就100個。結果每次一到11點~1點,每秒併發請求數量突然會暴增到1萬條。但是系統最大的處理能力就只能是每秒鐘處理1000個請求啊。。。尷尬了,系統會死。。。
(2)訊息佇列有什麼優點和缺點啊?
優點上面已經說了,就是在特殊場景下有其對應的好處,解耦、非同步、削峰
缺點呢?顯而易見的
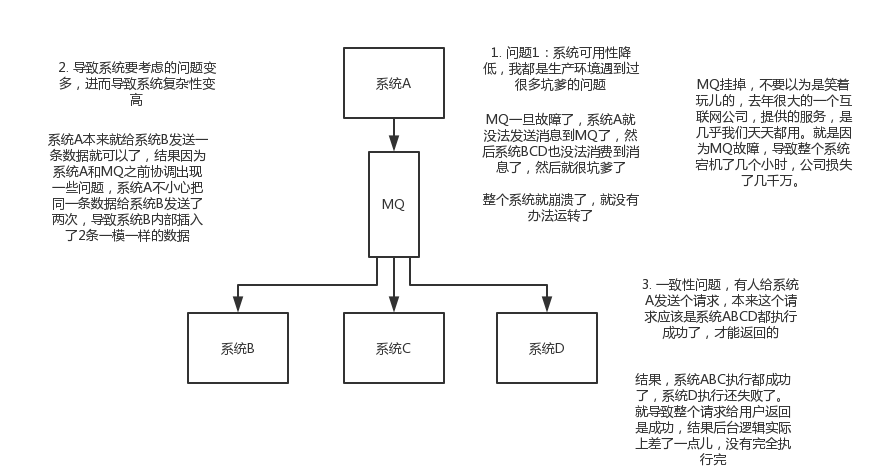
系統可用性降低:系統引入的外部依賴越多,越容易掛掉,本來你就是A系統呼叫BCD三個系統的介面就好了,人ABCD四個系統好好的,沒啥問題,你偏加個MQ進來,萬一
系統複雜性提高:硬生生加個MQ進來,你怎麼保證訊息沒有重複消費?怎麼處理訊息丟失的情況?怎麼保證訊息傳遞的順序性?頭大頭大,問題一大堆,痛苦不已
一致性問題:A系統處理完了直接返回成功了,人都以為你這個請求就成功了;但是問題是,要是BCD三個系統那裡,BD兩個系統寫庫成功了,結果C系統寫庫失敗了,咋整?你這資料就不一致了。
所以訊息佇列實際是一種非常複雜的架構,你引入它有很多好處,但是也得針對它帶來的壞處做各種額外的技術方案和架構來規避掉,最好之後,你會發現,媽呀,系統複雜度提升了一個數量級,也許是複雜了10倍。但是關鍵時刻,用,還是得用的。。。
(3)kafka、activemq、rabbitmq、rocketmq都有什麼優點和缺點啊?
常見的MQ其實就這幾種,別的還有很多其他MQ,但是比較冷門的,那麼就別多說了
作為一個碼農,你起碼得知道各種mq的優點和缺點吧,咱們來畫個表格看看
特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
單機吞吐量 | 萬級,吞吐量比RocketMQ和Kafka要低了一個數量級 | 萬級,吞吐量比RocketMQ和Kafka要低了一個數量級 | 10萬級,RocketMQ也是可以支撐高吞吐的一種MQ | 10萬級別,這是kafka最大的優點,就是吞吐量高。 一般配合大資料類的系統來進行實時資料計算、日誌採集等場景 |
topic數量對吞吐量的影響 | topic可以達到幾百,幾千個的級別,吞吐量會有較小幅度的下降 這是RocketMQ的一大優勢,在同等機器下,可以支撐大量的topic | topic從幾十個到幾百個的時候,吞吐量會大幅度下降 所以在同等機器下,kafka儘量保證topic數量不要過多。如果要支撐大規模topic,需要增加更多的機器資源 | ||
時效性 | ms級 | 微秒級,這是rabbitmq的一大特點,延遲是最低的 | ms級 | 延遲在ms級以內 |
可用性 | 高,基於主從架構實現高可用性 | 高,基於主從架構實現高可用性 | 非常高,分散式架構 | 非常高,kafka是分散式的,一個數據多個副本,少數機器宕機,不會丟失資料,不會導致不可用 |
訊息可靠性 | 有較低的概率丟失資料 | 經過引數優化配置,可以做到0丟失 | 經過引數優化配置,訊息可以做到0丟失 | |
功能支援 | MQ領域的功能極其完備 | 基於erlang開發,所以併發能力很強,效能極其好,延時很低 | MQ功能較為完善,還是分散式的,擴充套件性好 | 功能較為簡單,主要支援簡單的MQ功能,在大資料領域的實時計算以及日誌採集被大規模使用,是事實上的標準 |
優劣勢總結 | 非常成熟,功能強大,在業內大量的公司以及專案中都有應用 偶爾會有較低概率丟失訊息 而且現在社群以及國內應用都越來越少,官方社群現在對ActiveMQ 5.x維護越來越少,幾個月才釋出一個版本 而且確實主要是基於解耦和非同步來用的,較少在大規模吞吐的場景中使用 | erlang語言開發,效能極其好,延時很低; 吞吐量到萬級,MQ功能比較完備 而且開源提供的管理介面非常棒,用起來很好用 社群相對比較活躍,幾乎每個月都發布幾個版本分 在國內一些網際網路公司近幾年用rabbitmq也比較多一些 但是問題也是顯而易見的,RabbitMQ確實吞吐量會低一些,這是因為他做的實現機制比較重。 而且erlang開發,國內有幾個公司有實力做erlang原始碼級別的研究和定製?如果說你沒這個實力的話,確實偶爾會有一些問題,你很難去看懂原始碼,你公司對這個東西的掌控很弱,基本職能依賴於開源社群的快速維護和修復bug。 而且rabbitmq叢集動態擴充套件會很麻煩,不過這個我覺得還好。其實主要是erlang語言本身帶來的問題。很難讀原始碼,很難定製和掌控。 | 介面簡單易用,而且畢竟在阿里大規模應用過,有阿里品牌保障 日處理訊息上百億之多,可以做到大規模吞吐,效能也非常好,分散式擴充套件也很方便,社群維護還可以,可靠性和可用性都是ok的,還可以支撐大規模的topic數量,支援複雜MQ業務場景 而且一個很大的優勢在於,阿里出品都是java系的,我們可以自己閱讀原始碼,定製自己公司的MQ,可以掌控 社群活躍度相對較為一般,不過也還可以,文件相對來說簡單一些,然後介面這塊不是按照標準JMS規範走的有些系統要遷移需要修改大量程式碼 還有就是阿里出臺的技術,你得做好這個技術萬一被拋棄,社群黃掉的風險,那如果你們公司有技術實力我覺得用RocketMQ挺好的 | kafka的特點其實很明顯,就是僅僅提供較少的核心功能,但是提供超高的吞吐量,ms級的延遲,極高的可用性以及可靠性,而且分散式可以任意擴充套件 同時kafka最好是支撐較少的topic數量即可,保證其超高吞吐量 而且kafka唯一的一點劣勢是有可能訊息重複消費,那麼對資料準確性會造成極其輕微的影響,在大資料領域中以及日誌採集中,這點輕微影響可以忽略 這個特性天然適合大資料實時計算以及日誌收集 |
綜上所述,各種對比之後,我個人傾向於是:
一般的業務系統要引入MQ,最早大家都用ActiveMQ,但是現在確實大家用的不多了,沒經過大規模吞吐量場景的驗證,社群也不是很活躍,所以大家還是算了吧,我個人不推薦用這個了;
後來大家開始用RabbitMQ,但是確實erlang語言阻止了大量的java工程師去深入研究和掌控他,對公司而言,幾乎處於不可控的狀態,但是確實人是開源的,比較穩定的支援,活躍度也高;
不過現在確實越來越多的公司,會去用RocketMQ,確實很不錯,但是我提醒一下自己想好社群萬一突然黃掉的風險,對自己公司技術實力有絕對自信的,我推薦用RocketMQ,否則回去老老實實用RabbitMQ吧,人是活躍開源社群,絕對不會黃
所以中小型公司,技術實力較為一般,技術挑戰不是特別高,用RabbitMQ是不錯的選擇;大型公司,基礎架構研發實力較強,用RocketMQ是很好的選擇
如果是大資料領域的實時計算、日誌採集等場景,用Kafka是業內標準的,絕對沒問題,社群活躍度很高,絕對不會黃,何況幾乎是全世界這個領域的事實性規範