Merge Join vs. Hash Join vs. Nested Loop
Nested Loop,Hash Join,Merge Join介紹
-
Nested Loop:
對於被連線的資料子集較小的情況,Nested Loop是個較好的選擇。Nested Loop就是掃描一個表(外表),每讀到一條記錄,就根據Join欄位上的索引去另一張表(內表)裡面查詢,若Join欄位上沒有索引查詢優化器一般就不會選擇 Nested Loop。在Nested Loop中,內表(一般是帶索引的大表)被外表(也叫“驅動表”,一般為小表——不緊相對其它表為小表,而且記錄數的絕對值也較小,不要求有索引)驅動,外表返回的每一行都要在內表中檢索找到與它匹配的行,因此整個查詢返回的結果集不能太大(大於1 萬不適合)。 -
Hash Join:
Hash Join是做大資料集連線時的常用方式,優化器使用兩個表中較小(相對較小)的表利用Join Key在記憶體中建立散列表,然後掃描較大的表並探測散列表,找出與Hash表匹配的行。
這種方式適用於較小的表完全可以放於記憶體中的情況,這樣總成本就是訪問兩個表的成本之和。但是在表很大的情況下並不能完全放入記憶體,這時優化器會將它分割成若干不同的分割槽,不能放入記憶體的部分就把該分割槽寫入磁碟的臨時段,此時要求有較大的臨時段從而儘量提高I/O 的效能。它能夠很好的工作於沒有索引的大表和並行查詢的環境中,並提供最好的效能。大多數人都說它是Join的重型升降機。Hash Join只能應用於等值連線(如WHERE A.COL3 = B.COL4),這是由Hash的特點決定的。 -
Merge Join:
通常情況下Hash Join的效果都比排序合併連線要好,然而如果兩表已經被排過序,在執行排序合併連線時不需要再排序了,這時Merge Join的效能會優於Hash Join。Merge join的操作通常分三步:
1. 對連線的每個表做table access full;
2. 對table access full的結果進行排序。
3. 進行merge join對排序結果進行合併。
在全表掃描比索引範圍掃描再進行表訪問更可取的情況下,Merge Join會比Nested Loop效能更佳。當表特別小或特別巨大的時候,實行全表訪問可能會比索引範圍掃描更有效。Merge Join的效能開銷幾乎都在前兩步。Merge Join可適於於非等值Join(>,<,>=,<=,但是不包含!=,也即<>)
Nested Loop,Hash JOin,Merge Join對比
| 類別 | Nested Loop | Hash Join | Merge Join |
|---|---|---|---|
| 使用條件 | 任何條件 | 等值連線(=) | 等值或非等值連線(>,<,=,>=,<=),‘<>’除外 |
| 相關資源 | CPU、磁碟I/O | 記憶體、臨時空間 | 記憶體、臨時空間 |
| 特點 | 當有高選擇性索引或進行限制性搜尋時效率比較高,能夠快速返回第一次的搜尋結果。 | 當缺乏索引或者索引條件模糊時,Hash Join比Nested Loop有效。通常比Merge Join快。在資料倉庫環境下,如果表的紀錄數多,效率高。 | 當缺乏索引或者索引條件模糊時,Merge Join比Nested Loop有效。非等值連線時,Merge Join比Hash Join更有效 |
| 缺點 | 當索引丟失或者查詢條件限制不夠時,效率很低;當表的紀錄數多時,效率低。 | 為建立雜湊表,需要大量記憶體。第一次的結果返回較慢。 | 所有的表都需要排序。它為最優化的吞吐量而設計,並且在結果沒有全部找到前不返回資料。 |
實驗
本文所做實驗均基於PostgreSQL 9.3.5平臺
小於萬條記錄小表與大表Join
一張記錄數1萬以下的小表nbar.mse_test_test,一張大表165萬條記錄的大表nbar.nbar_test,大表上建有索引
Query 1:等值Join
| 1234567 | select count(*)from mse_test_test, nbar_test where mse_test_test.client_key = nbar_test.client_key; |
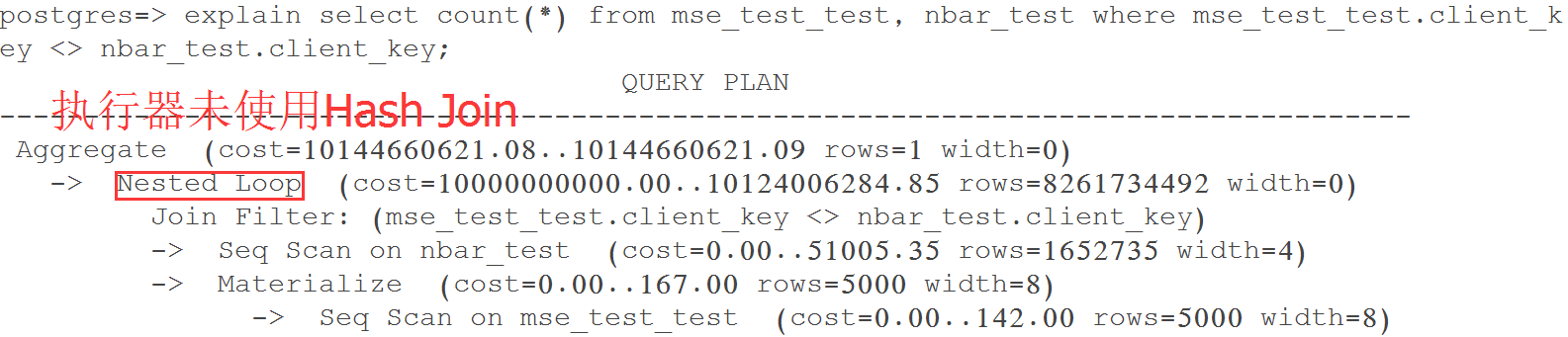
Query 1 Test 1: 查詢優化器自動選擇Nested Loop,耗時784.845 ms

如下圖所示,執行器將小表mse_test_test作為外表(驅動表),對於其中的每條記錄,通過大表(nbar_test)上的索引匹配相應記錄。
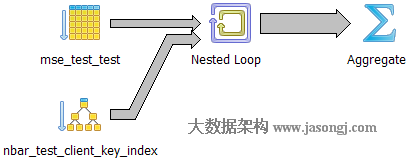
Query 1 Test 2:強制使用Hash Join,耗時1731.836ms

如下圖所示,執行器選擇一張表將其對映成散列表,再遍歷另外一張表並從散列表中匹配相應記錄。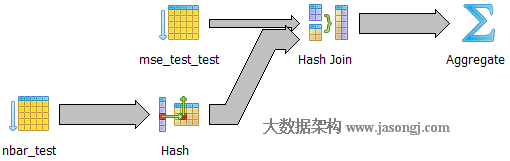
Query 1 Test 3:強制使用Merge Join,耗時4956.768 ms
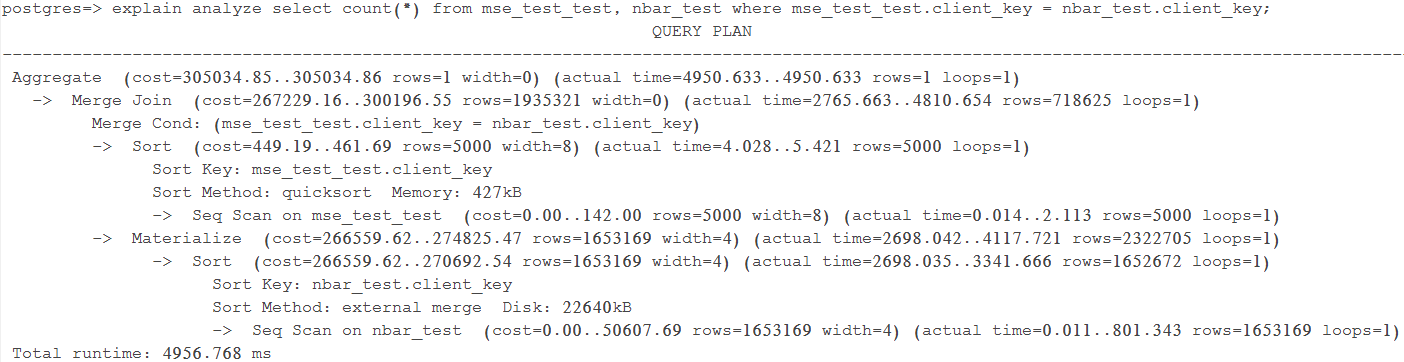
如下圖所示,執行器先分別對mse_test_test和nbar_test按client_key排序。其中mse_test_test使用快速排序,而nbar_test使用external merge排序,之後對二者進行Merge Join。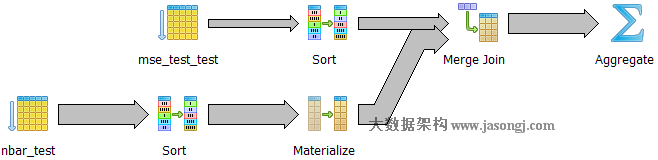
Query 1 總結 1 :
通過對比Query 1 Test 1,Query
1 Test 2,Query 1 Test 3可以看出Nested Loop適用於結果集很小(一般要求小於一萬條),並且內表在Join欄位上建有索引(這點非常非常非常重要)。
- 在大表上建立聚簇索引
Query 1 Test 4:強制使用Merge Join,耗時1660.228 ms
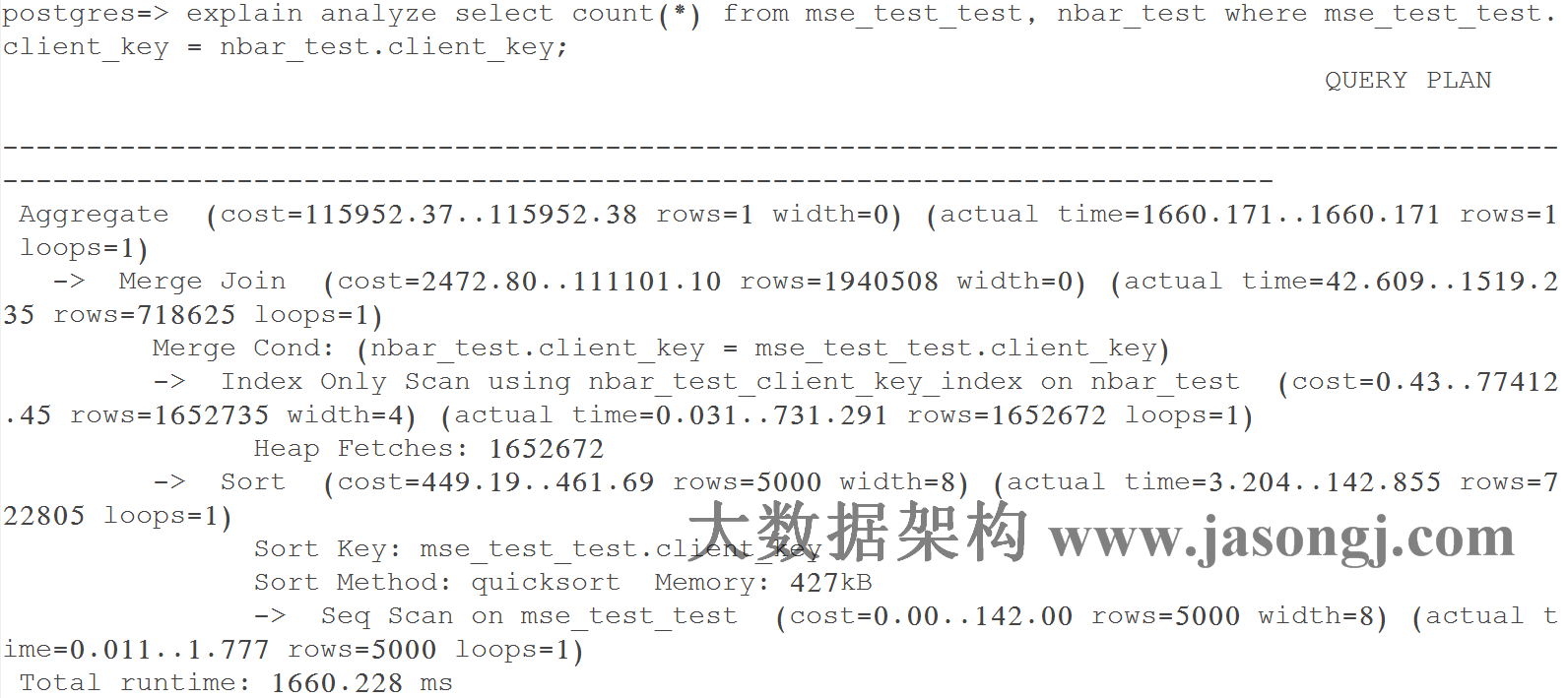
如下圖所示,執行器通過聚簇索引對大表(nbar_test)排序,直接通過快排對無索引的小表(mse_test_test)排序,之後對二才進行Merge Join。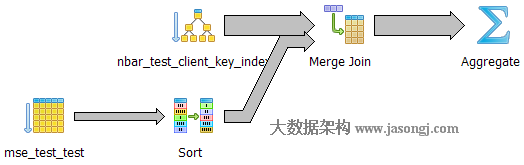
Query 1 總結 2:
通過對比Query 1 Test 3和Query
1 Test 4可以看出,Merge Join的主要開銷是排序開銷,如果能通過建立聚簇索引(如果Query必須顯示排序),可以極大提高Merge Join的效能。從這兩個實驗可以看出,建立聚簇索引後,查詢時間從4956.768 ms縮減到了1815.238 ms。
- 在兩表上同時建立聚簇索引
Query 1 Test 5:強制使用Merge Join,耗時2575.498 ms。
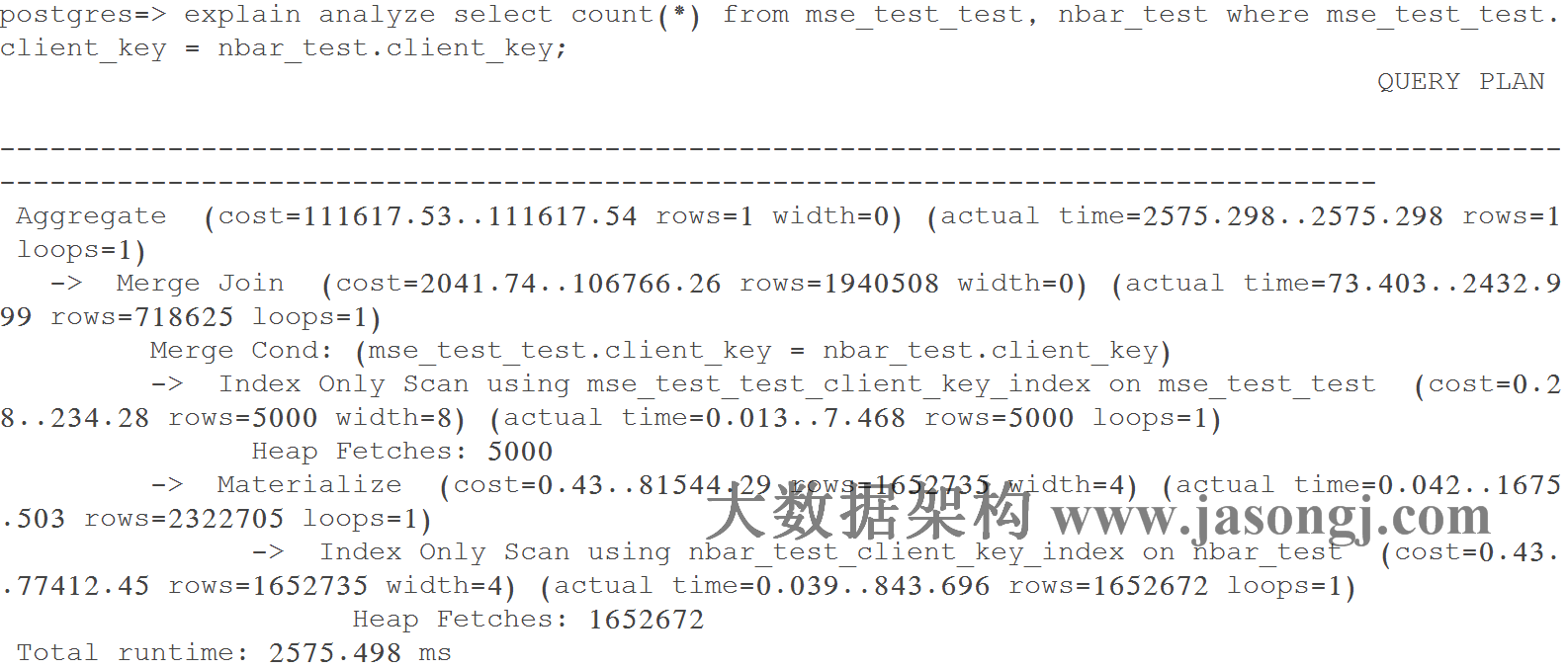
如下圖所示,執行器通過聚簇索引對大表(nbar_test)和小表(mse_test_test)排序,之後才進行Merge Join。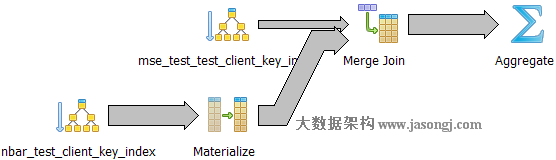
Query 1 總結 3:
對比Query 1 Test 4和Query
1 Test 5,可以看出二者唯一的不同在於對小表(mse_test_test)的訪問方式不同,前者使用快排,後者因為聚簇索引的存在而使用Index Only Scan,在表資料量比較小的情況下前者比後者效率更高。由此可看出如果通過索引排序再查詢相應的記錄比直接在原記錄上排序效率還低,則直接在原記錄上排序後Merge Join效率更高。
-
刪除nbar_test上的索引
Query 1 Test 6:強制使用Hash Join,耗時1815.238 ms
時間與
Query 1 Test 2幾乎相等。
如下圖所示,與
Query 1 Test 2相同,執行器選擇一張表將其對映成散列表,再遍歷另外一張表並從散列表中匹配相應記錄。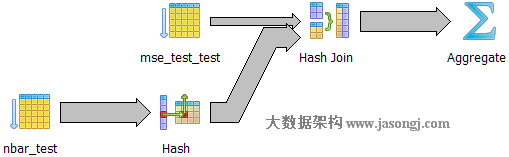
Query 1 總結 4 :
通過對比Query 1 Test 2,Query
1 Test 6可以看出Hash Join不要求表在Join欄位上建立索引。
兩大表Join
mse_test約100萬條記錄,nbar_test約165萬條記錄
###Query 2:不等值Join
| 123456789 | select count(*) from mse_test, nbar_test where mse_test.client_key = nbar_test.client_keyand mse_test.client_key between 100000 and 300000; |
Query 2 Test 1:強制使用Hash Join,失敗
本次實驗通過設定enable_hashjoin=true,enable_nestloop=false,enable_mergejoin=false來試圖強制使用Hash
Join,但是失敗了。