
Merge join、Hash join、Nested loop join對比分析
SQL server 內部實現了三種類型的內連線運算,大多數人從來沒有聽說過這些連線型別,因為它們不是邏輯連線也很少被用於程式碼中。那麼它們什麼時候會被用到呢?答案是要依情況而定。這就意味著要依賴於記錄集和索引。查詢優化器總是智慧的選擇最優的物理連線型別。我們知道SQL優化器建立一個計劃開銷是基於查詢開銷的,並依據此來選擇最佳連線型別。
那查詢優化器究竟是怎樣從內部選擇連線型別的呢?
SQLServer在內部為查詢優化器對連線型別的選擇實現了一些演算法,讓我們來看下面的一些練習示例,最後來做總結。
首先我給出一些基本的思想,連線是怎樣工作什麼時候工作,優化器又是怎樣決定使用哪種型別的內連線。
· 取決於表大小
· 取決於連線列是否有索引
· 取決於連線列是否排序
測試環境:
記憶體:4GB
資料庫伺服器:SQLServer 2008 (RTM)
create table tableA (id int identity ,name varchar(50)) declare @i int set @i=0 while (@i<100) begin insert into tableA (name) select name from master.dbo.spt_values set @[email protected]+1 end --select COUNT(*) from dbo.tableA --250600 go create table tableB (id int identity ,name varchar(50)) declare @i int set @i=0 while (@i<100) begin insert into tableB (name) select name from master.dbo.spt_values set @[email protected]+1 end -- select COUNT(*) from dbo.tableB --250600 select * from dbo.tableA A join tableB B on (a.id=b.id)
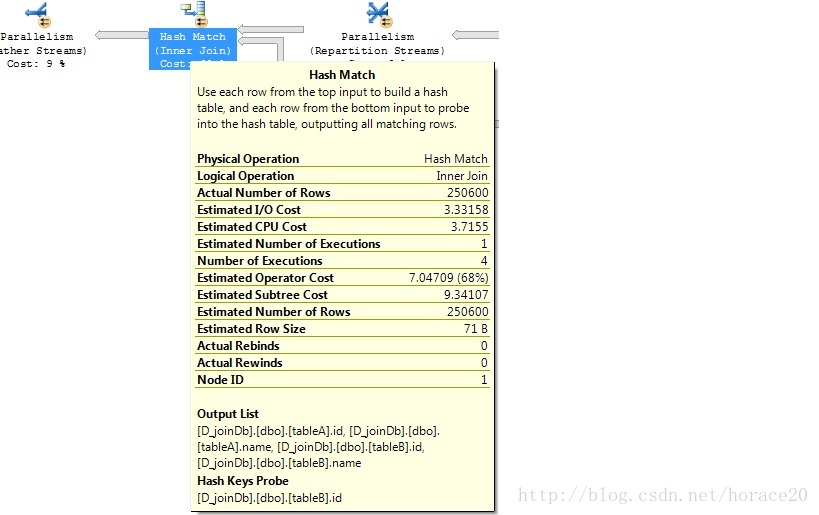
測試1:大表,沒有索引
現在來建立一個聚族索引:
create unique clustered index cx_tableA on tableA (id)
create unique clustered index cx_tableB on tableB (id)測試1:大表,有索引
如果連線中的任何一個表有索引那麼將採用Hash Join。我並沒有貼上所有結果截圖,如果你感興趣你可以刪除任何一個表中的索引來做測試。
測試2:中表,沒有索引
首先建立表:
create table tableC (id int identity,name varchar(50))
insert into tableC (name)
select name from master.dbo.spt_values
-- select COUNT(*) from dbo.tableC --2506
create table tableD (id int identity,name varchar(50))
insert into tableD (name)
select name from master.dbo.spt_values
select * from dbo.tableC C join tableD D
on (C.id=D.id)
-- select COUNT(*) from dbo.tableD --2506
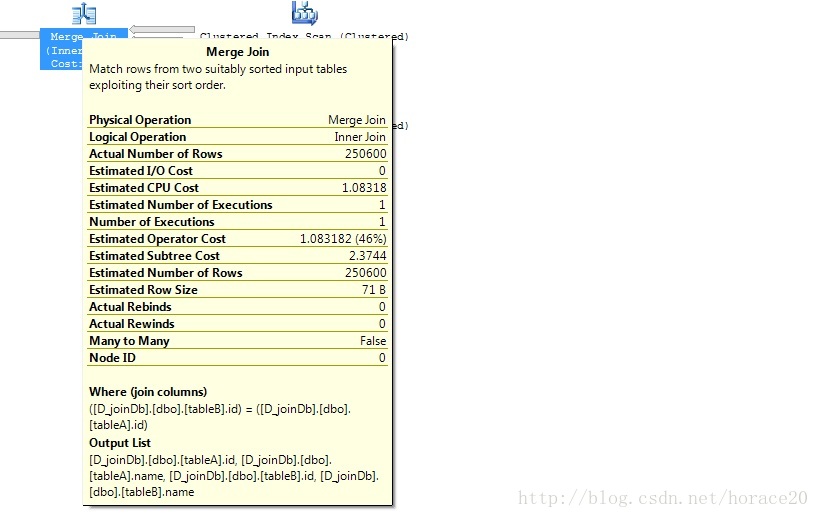
測試2:中表,有索引
首先還是建立一個聚族索引:
create unique clustered index cx_tableC on tableC (id)
create unique clustered index cx_tableD on tableD (id)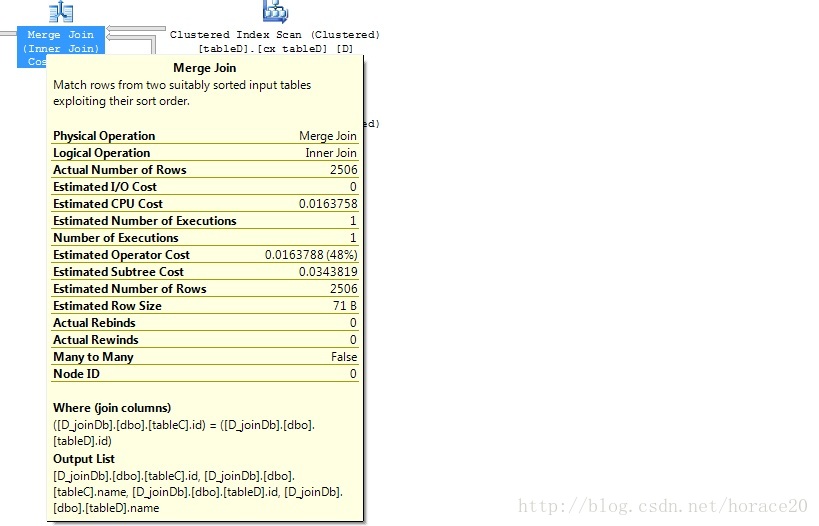
對於中等大小的表,如果連線中的任何一個表有索引,那麼將採用Merge Join。
測試3:小表,沒有索引create table tableE (id int identity,name varchar(50))
insert into tableE (name)
select top 10 name from master.dbo.spt_values
-- select COUNT(*) from dbo.tableE --10
create table tableF (id int identity,name varchar(50))
insert into tableF (name)
select top 10 name from master.dbo.spt_values
-- select COUNT(*) from dbo.tableF --10
測試3:小表,有索引
建立聚族索引:
create unique clustered index cx_tableE on tableE (id)
create unique clustered index cx_tableF on tableF (id)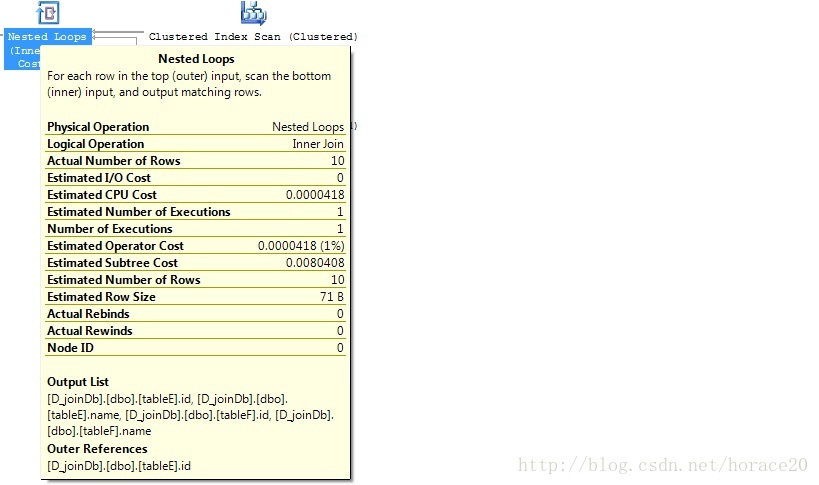
對於小表,如果任何一個表中有索引,那麼將採用Nested Loop Join。
同樣也可以從另一個方向來做比較,比如大表對比中表對比小表。
select * from dbo.tableA A join tableC C
on (a.id=C.id)
select * from dbo.tableA A join tableE E
on (a.id=E.id)
select * from dbo.tableC C join tableE E
on (C.id=E.id)在這種情況下若所有或部分表都有索引則採用Nested Loop Join,如果都沒有則使用HashJoin。
當然你也可以強制優化器使用任何一種連線型別,但這並不是一種值得推薦的做法。查詢優化器很智慧,能夠動態的選擇最優的一個。這裡我只是顯示呼叫了MergeJoin,所以優化器使用MergeJoin替代本來應使用HashJoin (測試1沒有索引)。
select * from dbo.tableA A join tableB B
on (A.id=B.id)option (merge join)
select * from dbo.tableA A inner merge join tableB B
on (A.id=B.id)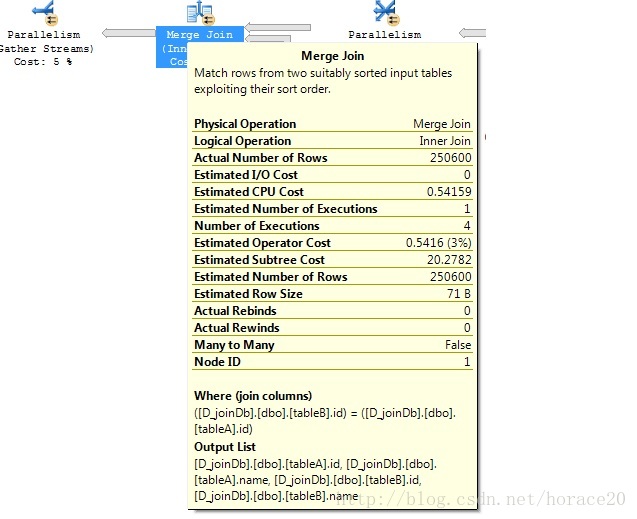
表1 測試唯一聚族索引
根據上表:
Ø 如果兩個表都沒有索引則查詢優化器內部會選擇Hash Join
Ø 如果兩個表都有索引則內部會選擇Merge Join(大表)/NestedLoop Join(小表)
Ø 如果其中的一個表有索引則查詢優化器內部會選擇Merge Join(中表)/HashJoin(大表)/NestedLoop Join(小表&大表 vs 小表)
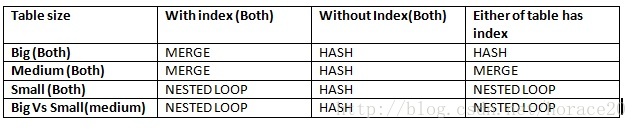
表2 測試聚族索引(createclustered indexcx_tableA ontableA (id))
|
Table size |
With index (Both) |
Without Index(Both) |
Either of table has index |
|
|
Big (Both) |
HASH |
HASH |
HASH |
|
|
Medium (Both) |
HASH |
HASH |
HASH |
|
|
Small (Both) |
NESTED LOOP |
NESTED LOOP |
HASH |
|
|
Big Vs Small(medium) |
HASH |
HASH |
HASH |
|
根據上表:
這個測試是在沒有使用唯一聚族索引下完成,可以知道如果建立索引的時候沒有使用UNIQUE關鍵字則無法保證SQLServer會知道這是UNIQUE資料,所以它預設會建立4位元組整數來作為唯一識別符號。
根據上表如果建立聚族索引沒有使用Unique關鍵字則不會使用MergeJoin。
謝謝@Dave的郵件,現在加上第二個圖表了。
總結:
Merge Join
Merge Join是為那些在連線列上有索引的表,索引可以是聚族索引或者非聚族索引。Merge是這種情況最好的Join型別,需要兩個表都有索引,所以它已經排好序並更容易匹配和返回資料。
Hash Join
Hash Join是為那些沒有索引或者其中任一個有索引的大表。對於這種情況它是最好的Join型別,為什麼呢?因為它能夠很好的工作於沒有索引的大表和並行查詢的環境中,並提供最好的效能。大多數人都說它是Join的重型升降機。
Nested Loop Join
Nested Loop Join是為那些有索引的小表或其中人一個有索引的大表。它對那些小表連線,需要迴圈執行從一個到另一個表的按行比較的情況下工作最好的。
我希望你現在能理解查詢優化器是如何選擇最優的查詢型別。