
Tensorflow與深度學習筆記
根據學習《TensorFlow實戰Goolgle深度學習框架》摘抄的三四章重點
一、計算圖——Tensorflow的計算模型
1.1 計算圖的概念
TensorFlow中的每一個計算都是計算圖上的一個節點,而節點之間的邊描述了計算之間的依賴關係
- 兩個向量相加樣例的計算圖:
1.2 計算圖的使用
Tensorflow程式一般可以分為兩個階段:
- 第一個階段需要定義計算圖中所有的計算
- 第二個階段為執行階段
定義階段的樣例:
import tensorflow as tf a = tf.constant([1.0, 2.0], name="a") b = tf.constant([2.0, 3.0], name="b") result = a + b
- 在TensorFlow程式中,系統會自動維護一個預設的計算圖,通過tf.get_default_graph函式可以獲取當前預設的計算圖
- 除了使用預設的計算圖,TensorFlow支援通過tf.Graph函式來生成新的計算圖。不同計算圖上的張量和運算都不會共享
- 在一個計算圖中,可以通過集合(collection)來管理不同類別的資源。比如通過tf.add_to_collection函式可以將資源加入一個或多個集合中,然後通過tf.get_collection獲取一個集合裡面的所有資源
二、張量——TensorFlow的資料模型
在TensorFlow程式中,所有資料都通過張量(tensor)的形式來表示
例如:
import tensorflow as tf
a = tf.constant([1.0, 2.0], name="a")
b = tf.constant([2.0, 3.0], name="b")
result = a + b
print result
##############################
# 輸出:
# Tensor("add:0", shape=(2,), dtype=float32)
一個張量中主要儲存了三個屬性:名字、維度和型別
三、會話——TensorFlow的執行模型
會話(session)擁有並管理TensorFlow程式執行時的所有資源。
當所有計算完成之後需要關閉會話來幫助系統回收資源,否則就可能出現資源洩露的問題
使用TensorFlow中的會話來執行定義好的運算:
- 第一種模式需要明確呼叫會話生成函式和關閉會話函式:
# 建立一個會話
sess = tf.Session()
# 使用這個建立好的會話來得到關心的運算的結果。
# 比如可以呼叫sess.run(result)來的到張量result的取值
sess.run(...)
# 關閉會話使得本次執行中使用到的資源可以被釋放
sess.close()
- TensorFlow可以通過Python的上下文管理器來使用會話:
# 建立一個會話,並通過Python中的上下文管理器來管理這個會話
with tf.Session() as sess:
# 使用這個建立好的會話來計算關心的結果
sess.run(...)
# 不需要再呼叫"Session.close()"函式來關閉對話
# 當上下文退出時會話關閉和資源釋放也自動完成了
四、神經網路相關
使用神經網路解決分類問題主要分為4個步驟
- 提取問題中實體的特徵向量作為神經網路的輸入
- 定義神經網路的結構,並定義如何從神經網路的輸入得到輸出。(神經網路的前向傳播演算法)
- 通過訓練資料來調整神經網路中引數的取值,這就是訓練神經網路的過程
- 使用訓練好的神經網路來預測未知的資料
4.1 全連線網路結構的前向傳播演算法
神經元結構示意圖:
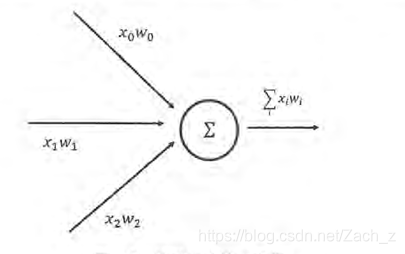
- 一個神經元有多個輸入和一個輸出,每個神經元的輸入既可以是其他神經元的輸出,也可以是整個神經網路的輸入
- 所謂神經網路的結構就是指的不同神經元之間的連線結構
- 如圖所示,一個最簡單的神經元結構的輸出就是所有輸入的加權和,而不同輸入的權重就是神經元的引數
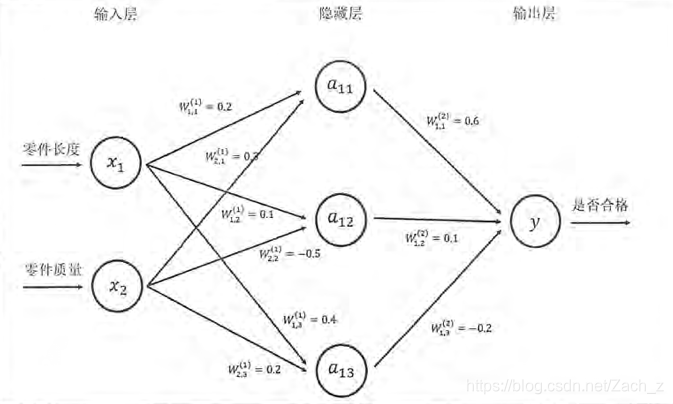
全連線即相鄰兩層之間任意兩個節點之間都有連線
三層神經網路結構圖:
全連線的神經網路前向傳播演算法示意圖:
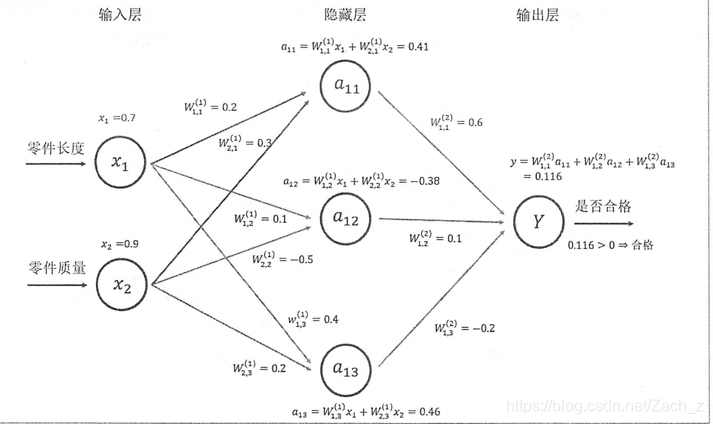
可以通過矩陣乘法得到隱藏層三個節點所組成的向量取值:
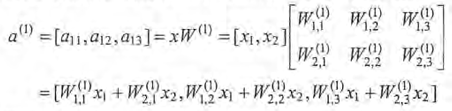
類似的輸出層也可以用矩陣乘法表示:
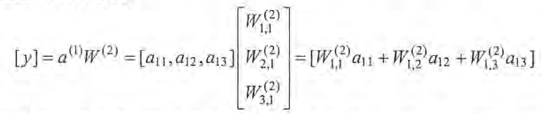
TensorFlow中矩陣乘法使用tf.matmul函式實現,上述矩陣乘法可以寫成:
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
4.2 TensorFlow變數
TensorFlow變數宣告函式tf.Variable:
#變數w為:一個2x3的矩陣,矩陣中元素是均值為0,標準差為2的隨機數
w = tf.Variable(tf.random_normal([2, 3], stddev = 2))
#變數b為: 初始值全部為0且長度為3的變數
b = tf.Variable(tf.zeros[3])
初始化所有變數:
init_op = tf.initialize_all_variables()
sess.run(init_op)
4.3 通過TensorFlow訓練神經網路模型
神經網路反向傳播優化流程圖:
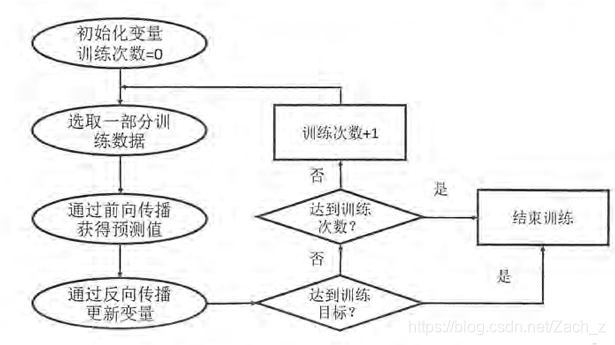
- 反向傳播演算法實現了一個迭代的過程。
- 在每次迭代的開始,首先需要選取一小部分訓練資料,這一小部分資料叫做一個batch
- 之後,這個batch的樣例會通過前向傳播演算法得到神經網路模型的預測結果
- 將預測答案與正確答案進行比較,計算出差距
- 最後根據預測值和真實值之間的差距,反向傳播演算法會相應更新神經網路引數的取值,使得在這個batch上神經網路模型的預測結果和真實答案更加接近
placeholder機制是TensorFlow中用於提供輸入資料的,相當於定義了一個位置,這個位置中的資料在程式執行時再指定
通過placeholder實現前向傳播演算法的程式碼:
import tensorflow as tf
w1 = tf.Variable(tf.random_normal[2, 3], stddev = 1))
w2 = tf.Variable(tf.random_normal[3, 1], stddev = 1))
# 定義placeholder作為存放輸入資料的地方
# 這裡維度也不一定要定義
# 但如果維度是確定的,那麼給出維度可以降低出錯的概率
x = tf.placeholder(tf.float32, shape = (1, 2), name = "inout")
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
sess = tf.Session()
init_op = tf.initialize_all_variables()
sess.run(init_op)
print(sees.run(y, feed_dict = {x: [[0.7, 0.9]]}))
- feed_dict來指定x的取值
- 上述例子值計算了一個樣例的前向傳播結果,如果每次提供一個batch的訓練樣例,將輸入的1x2矩陣改為nx2的矩陣,就可以得到n個樣例的前向傳播結果了
x = tf.placeholder(tf.float32, shape=(3, 2), name = "input")
print(sess.run(y, feed_dict={x: [[0.7, 0.9], [0.1, 0.4], [0.5, 0.8]]}))
在得到一個batch的前向傳播結果之後,需要定義一個損失函式來刻畫當前的預測值和真實答案之間的差距。
定義一個簡單的損失函式,並通過TensorFlow定義了反向傳播演算法:
# 定義損失函式來刻畫預測值與真實值得差距
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
# 定義學習率
learning_rate = 0.001
# 定義反向傳播演算法來優化神經網路中的引數
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
4.4 通過啟用函式實現去線性化
如果將每一個神經元(也就是神經網路中的節點)的輸出通過一個非線性函式,那麼整個神經網路的模型也就不再是線性的了。這個非線性函式就是啟用函式。
加入偏置項和啟用函式的神經元結構示意圖:
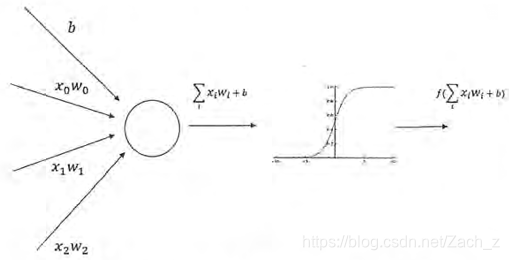
常用的神經網路啟用函式的函式影象:
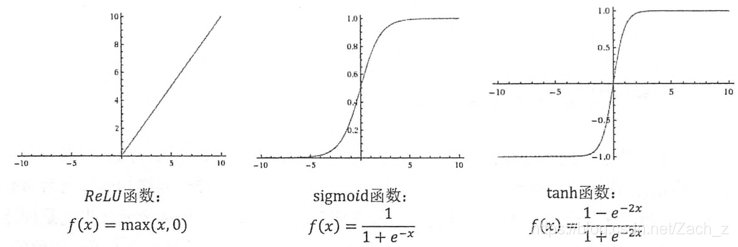
TensorFlow實現三層全相連的前向傳播演算法,加入偏置項和啟用函式:
a = tf.nn.relu(tf.matmul(x, w1) + biases1)
y = tf.nn.relu(tf.matmul(a, w2) + biases2)
4.5 損失函式
損失函式被用來測試神經網路模型的效果,即用來判定預測結果和正確結果之間差距,並且通過差距來優化引數
交叉熵用來刻畫兩個概率分佈之間的距離,給定兩個概率分佈p和q,通過q來表示p的交叉熵為:
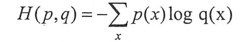
Softmax用來把輸出的資料對映成為(0, 1)的值,而這些值的累和為1。
假設有一個三分類問題,某個樣例的正確答案是(1,0,0)。
某模型經過Softmax迴歸之後的預測答案是(0.5,0.4,0.1),那麼這個預測和正確答案之間的交叉熵為:
H((1,0,0),(0.5,0.4,0.1)) = -(1*log0.5+0*log0.4+0*log0.1)≈0.3
如果另外一個模型的預測是(0.8,0.1,0.1),那麼這個測試值和真實值之間的交叉熵是:
H((1,0,0),(0.8,0.1,0.1)) = -(1*log0.8+0*log0.1+0*log0.1)≈0.1
通過TensorFlow實現交叉熵:
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10 1.0)))
- y_代表正確結果,y代表預測結果
- tf.clip_by_value用來把y值限制在1e-10 ~ 1.0之間
- tf.log函式完成了對張量中所有元素依次求對數的功能
- 計算得到結果是n x m的二維矩陣,其中n為一個batch中樣例的數量,m為分類的類別數量
- 根據交叉熵的公式,應該將每行中的m個結果相加得到所有樣例的交叉熵,然後再對這n行取平均得到一個batch的交叉平均熵,使用tf.reduce_mean來完成這一操作:
v = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
# 輸出3.5
print tf.reduce_mean(v).eval()
- 交叉熵與softmax迴歸一起封裝,使用tf.nn.softmax_cross_entropy_with_logits函式得到softmax迴歸之後的交叉熵損失函式:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y, y_)
與分類問題不同,迴歸問題解決的是對具體數值的預測,最常用的損失函式是均方誤差MSE,定義為:
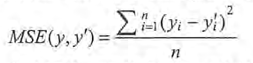
通過TensorFlow實現均方誤差損失函式:
mse = tf.reduce_mean(tf.square(y_ - y))
自定義損失函式
一個當預測多於真實值和預測少於真實值有不同損失係數的損失函式:
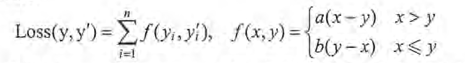
在TensorFlow中實現:
loss = tf.reduce_sum(tf.select(tf.greater(v1, v2), (v1 - v2) * a, (v2 - v1) * b))
4.6 神經網路的優化
4.6.1 batch
實際應用中一般採用 每次計算一小部分訓練資料的損失函式,這一小部分資料被稱之為一個batch。
神經網路的訓練大都遵循以下過程:
batch_size = n
# 每次讀取一小部分資料作為當前的訓練資料來執行反向傳播演算法
x = tf.placeholder(tf.float32, shape = (batch_size, 2), name = 'x-input')
y_ = tf.placeholder(tf.float32, shape = (batch_size, 1), name = 'y-input')
# 定義神經網路結構和優化演算法
loss = ...
train_step = tf.train.AdamOptimizer(0.001).minimize(loss)
# 訓練神經網路
with tf.Session() as sess:
# 引數初始化
...
# 迭代的更新引數
for i in range (STEPS):
# 準備batch_size個訓練資料。一般將所有訓練資料隨機打亂之後再選取可以得到更好的優化結果
current_X, current_Y = ...
sess.run(train_step, feed_dict = {x: current_X, y_: current_Y})
4.6.2 學習率的設定
設定學習率控制引數更新的速度
global_step = tf.Variable(0)
# 通過exponential_decay函式生成學習率
learning_rate = tf.train.exponential_decay(0.1, global_step, 100, 0.96, staircase = True)
# 使用指數衰減的學習率
# 在minimize函式中傳入global_steo將自動更新global_step引數,從而使得學習率也得到相應更新
learning_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(...my loss..., global_step = global_step)
- 上段程式碼設定了初始學習率為0.1,因為指定staircase=True,所以每訓練100輪後學習率乘以0.96
- tf.train.exponential_decay函式實現了指數衰減學習率,通過這個函式,可以先使用較大的學習率來快速得到一個比較優的解,然後隨著迭代逐步減小學習率
- exponential_decay函式會指數級地減小學習率,實現以下程式碼的功能:
decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)
- learning_rate: 初始學習率
- decay_rate: 衰減係數
- decay_steps:衰減速度
4.6.3 正則化
避免過擬合問題,假設用於刻畫模型使用J(0),優化時優化J(0)+λJ(0)
- R(w)刻畫的是模型的複雜程度,而λ表示模型複雜損失在總損失中的比例
- 0表示的是一個神經網路中的所有引數,它包括邊上的權重w和偏置項b
一個簡單的帶L2正則化損失函式定義:
w = tf.Variable(tf.random_normal([2, 1], stddev = 1, seed =1))
y = tf.matmul(x, w)
loss = tf.reduce_mean(tf.square(y_ - y)) + tf.contrib.layers.l2_regularizer(lambda)(w)
L1正則化和L2正則化的區別:
weights = tf.constant([[1.0, -2.0], [-3.0, 4.0]])
with tf.Session() as sess:
# 輸出為(|1|+|-2|+|-3|+|4|) * 0.5 = 5。其中0.5為正則化項的權重
print sess.run(tf.contrib.layers.l1_regularizer(.5)(weights))
# 輸出為(1^2 + (-2)^2 + (-3)^2 + 4^2) / 2 * 0.5 = 7.5
print sess.run(tf.contrib.layers.l2_regularizer(.5)(weights))
4.6.4 滑動平均模型
滑動平均模型即用來控制模型引數調整的速度,如果有異常資料進入訓練不至於改變的太離譜
使用tf.train.ExponentialMovingAverage來實現滑動平均模型:
-
初始化ExponentialMovingAverage時,需要提供一個衰減率(decay),這個衰減率用於控制模型更新的速度
-
ExponentialMovingAverage對每一個變數會維護一個影子變數,這個影子變數的初始值就是相應變數的初始值,而且每次執行變數更新時,影子變數的值會更新為:
shadow_variable = decay * shadow_variable + (1 - decay) * variable
-
從公式中可以看出來,decay決定了模型更新的速度,decay越大模型越趨於穩定。(實際應用中,decay一般會設成非常接近1的數,比如0.999)
-
為了使得模型在訓練前期可以更新更快,ExponentialMovingAverage還提供了num_updates引數來動態設定decay大小,如果初始化時提供了num_updates引數,那麼每次使用的衰減率是:
min{decay, (1 + num_updates) / (10 + num_updates)}
-
下面程式碼解釋ExponentialMovingAverage是如何被使用:
import tensorflow as tf
# 定義一個變數用於計算滑動平均,這個變數的初始值為0
# 這裡手動指定了變數的型別為tf.float32,因為所有需要計算滑動平均的變數必須是實數型
v1 = tf.Variable(0, dtype = tf.float32)
# 這裡step變數模擬神經網路中迭代的輪數,可以用於動態控制衰減率
step = tf.Variable(0, trainable = False)
# 定義一個滑動平均的類(class)
# 初始化時給定了衰減率(0.99)和控制衰減率的變數step
ema = tf.train.ExponentialMovingAverage(0.99, step)
# 定義一個更新變數滑動平均的操作。
# 這裡需要給定一個列表,每次執行這個操作時這個列表中的變數都會被更新
maintain_averages_op = ema.apply([v1])
with tf.Session() as sess:
# 初始化所有變數
init_op = tf.initialize_all_variables()
sess.run(init_op)
# 通過ema.average(v1)獲取滑動平均之後變數的取值
# 在初始化之後變數v1的值和v1的滑動平均都為0
# 輸出[0.0, 0.0]
print sess.run([v1, ema.average(v1])
# 更新變數v1的值到5
sess.run(tf.assign(v1, 5))
# 更新v1的滑動平均值。衰減率為min{0.99, (1 + step)/(10 + step) = 0.1} = 0.1
# 所以v1的滑動平均會被更新為0.1 * 0 + 0.9 * 5 = 4.5
sess.run(maintain_averages_op)
# 輸出[5.0, 4.5]
print sess.run([v1, ema.average(v1)])
# 更新step的值為10000
sess.run(tf.assign(step, 10000))
# 更新v1的值為10
sess.run(tf.assign(v1, 10))
# 更新v1的滑動平均值。衰減率為min{0.99, (1 + step) / (10 + step) ≈ 0.999} = 0.99
# 所以v1的滑動平均會被更新為0.99*4.5+0.01*10 = 4.555
sess.run(maintain_averages_op)
# 輸出[10.0, 4.5549998]
print sess.run([v1, ema.average(v1)])
# 再次更新滑動平均值,得到的新滑動平均值為0.99*4.555+0.01*10 = 4.60945
sess.run(maintain_averages_op)
# 輸出[10.0, 4.6094499]
print sess.run([v1, ema.average(v1)])