
redis筆記2--資料持久化和叢集
阿新 • • 發佈:2018-12-25
資料持久化
資料持久化的用處:
1.恢復資料。 2.減少資料的運算,如:從關係型資料庫載入資料到redis後,redis服務重啟時不需要在去關係型資料庫獲取資料,直接讀取硬碟上的備份即可。
快照方式
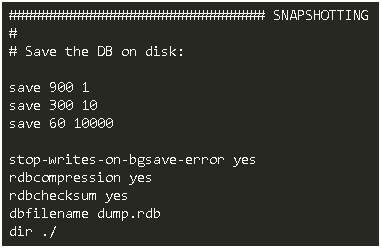
記錄某個時刻的資料到硬碟上。
注意:快照這種方式,在上次快照儲存後,下次快照儲存之前,這之間寫入redis的資料,如果redis服務崩潰了,這部分資料會丟失。
啟動快照的方法:
- 在客戶端執行 bgsave命令,redis會新建一個子執行緒去儲存快照,父執行緒繼續響應執行各個命令。
- 客戶端執行 save 命令,阻塞式,redis會停止任何命令的執行,直到快照儲存完成。一般我們沒有足夠的記憶體來執行bgsave或是允許等待save儲存快照完成的情況下執行該命令。
- 配置檔案中配置save 引數。如:save 60 10000 ,每分鐘至少10000次操作,redis會自動觸發bgsave操作。
- redis伺服器接收到了shutdown命令,redis會執行save命令,同時阻止客戶端再執行任何命令,然後關閉。
- 如果redis伺服器連線了另一個redis伺服器,並且執行了sync命令,主機會執行bgsave 操作來備份資料。
幾種常見場景下的配置:
- 開發環境(development)
作為開發伺服器,我們關心的是最小化快照的儲存。一般可以設定規則為:save 900 1 。每15分鐘儲存一次。
觸發儲存快照的原則就是:不能觸發太頻繁,會耗費很多資源。也不能不觸發或觸發太少,容易丟失資料。
- 記錄日誌(aggregating logs)
為了恢復損失的資料,首先,我們需要知道我們丟失了什麼資料。因此我們要記錄操作資訊到日誌中。假如我們有一個函式,每當新的日誌準備好處理時,就會呼叫這個函式。這個函式提供redis連線,日誌檔案路徑,回撥函式三個引數。在回撥函式中,我們可以向日志中寫入操作記錄。(每次儲存快照後,就新建一個日誌檔案,記錄這次快照結束到下次快照儲存之前這段時間內的操作記錄。) 通過記錄程式日誌,我們就可以在伺服器宕機後及時恢復丟失的資料。因為我們是pipeline中使用了事務控制,所以日誌檔案中只會記錄執行完成的命令,不會記錄處理了一部分的資訊。
- 大資料(big data)
當我們儲存的資料上GB時,使用快照方式會比較合適。但是隨著記憶體佔用的持續增長,執行bgsave操作的時間也會持續增加。 如果redis用了10多GB的記憶體,導致沒有多餘的記憶體來執行bgsave命令。可能會造成系統停止等一系列問題(從而降低系統性能甚至造成系統不可用)。 為了防止這種問題,我們需要停止自動儲存快照功能,通過手動去呼叫save或是bgsave命令。如果是save命令,redis會阻塞直到快照儲存完成。這種情況不會像bgsave一樣去建立子執行緒處理備份,這樣就不會有建立子執行緒的延遲,也不會有子執行緒和自己爭奪資源,所以save命令會更快速的完成備份工作。 作者經驗:
當redis伺服器上有50GB資料時。使用bgsave命令,建立子執行緒需要花費大概15秒鐘或更久,然後儲存快照需要大概15-20分鐘。如果是使用save命令,只需要3-5分鐘即可。 實際運用中,每天凌晨3:00儲存一個快照。通過指令碼去停止客戶端的連線,然後呼叫save命令去儲存快照,儲存完後再恢復客戶端連線。 總結:
當我們可以處理潛在的資料丟失時,使用快照很方便。但是如果我們不能容忍15min或1hr或更大量的資料丟失時,使用append-only file方式來持久化會是比較好的選擇。
AOF方式(append-only file)
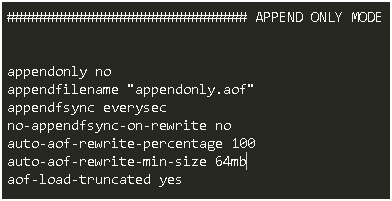
每當有寫命令執行時,記錄命令到日誌檔案中,當server重啟時,將這些寫操作重新執行一遍。這種方式會記錄每一次修改,最大限度保證資料的完整性。
這種方式,會記錄每一次的資料改動到日誌檔案中,每次需要恢復資料,就將日誌記錄的資訊從頭到尾再執行一遍。
通過設定appendonly yes 引數
檔案同步(File Syncing)
當將檔案儲存到硬碟上時,過程如下:
1.呼叫file.write()方法,將內容寫到快取中。
2.呼叫file.flush(),將快取中的資料重新整理儲存到硬碟。(程式只是傳送一個寫磁碟的請求,具體有作業系統去執行,會阻塞。執行完後資料就儲存在磁碟上了)。
appendfsync:引數配置
作為中和的選擇,可以設定為everysec。在保證資料安全的同時也能提供一個不錯的效能。對大多數普通應用來說,每秒同步和不做持久化相比,這之間沒有多大的效能損失(即每秒同步不會造成明顯的效能損失)。
- always:每次redis的寫命令都會觸發儲存記錄到磁碟,可以保證最小的資料丟失,但是會影響redis效能(由於頻繁的io操作)。
- everysec:每秒同步一次,明確同步寫命令到磁碟
- no:讓作業系統控制同步到磁碟
當硬碟跟不上寫入資料的速度時,redis會減緩寫入速度來適應硬體驅動的最大寫入效率。
no選項不建議使用。
這種情況下,完全交給作業系統處理,不會有效能上的損失,但是一旦發生宕機,丟失的資料我們無法獲取或預測。而且,如果我們用的硬碟寫入速度不夠快,redis會執行到快取區寫滿了才重新整理到硬碟,這會導致redis變慢,在向磁碟寫資料的時候也會阻塞。append-only files 方式很靈活,缺點就是附件檔案比較大。
重寫/壓縮aof檔案
通過附加檔案(append-only files)的方式,我們可以最小化資料丟失,並且最小化持久化資料到硬碟的時間。 但是隨著時間的推移,aof檔案會持續增長。可能造成磁碟空間不足。更常見的是,當我們重啟redis伺服器時,會重新執行aof日誌檔案裡的命令,當aof檔案很大時,啟動redis會花費很長時間。 為了解決這個問題:
使用bgrewriteaof命令:會刪除重複的命令。執行方式域bgsave命令類似。建立一個子執行緒,重寫附加檔案(快照中的問題,子執行緒時間延遲,記憶體消耗同樣存在,並且更嚴重。因為aof檔案可能是快照檔案dump的好幾倍)當aof重寫時,作業系統需要刪除aof檔案,刪除10多GB的檔案會導致系統掛起數秒鐘。 配置檔案方式呼叫重寫:
auto-aof-rewrite-percentage 100:表示當aof檔案比上次增長了一倍(100%)時 auto-aof-rewrite-min-size 64mb:aof檔案至少有64mb大如果重寫太頻繁,可以適當調整引數(將100調大),儘管可能造成redis重啟花費更長時間。
如果允許,建議備份快照和最新的重寫的aof檔案到其他伺服器。
叢集
叢集在關係型資料庫中很常見,主機(master)傳送寫資料到多個從機(slaves),從機執行所有的查詢命令。redis也採用了這種模式。
雖然redis速度很快,但是任然有很多場景下,光單機的redis提供服務是不夠的。實際應用中,對set和zset集合的操作可能涉及成千上萬,甚至上百萬條資料。當涉及到上百萬條資料時,set集合的 操作會花費數秒。
在主機向叢集中其他伺服器傳送初始化資料拷貝後,客戶端向主機寫入資料,都會同步更新到從機上。以後查詢都是通過負載均衡連線到其中的一個從機去查詢,而不是直接連線主機了。
叢集配置
當從機連線到主機時,主機會執行一個bgsave操作。為了配置叢集,需要保證快照配置中的dir和dbfilename引數正確有效,且可讀。 儘管從機自己有很多控制狀態的配置選項,其中只有一個選項是真正需要的:slaveof host port。當redis啟動時,就會把這個地址的機器當作主機去連線。如果是一個執行中的系統,可以通過slaveof host port命令去操作。
slaveof no one :停止與主機的同步更新

叢集啟動過程
概述:當slave連線master時,master會立刻儲存一個快照,然後傳送給slave。 詳細步驟:
在叢集中,redis會設法保持大多數的伺服器同步,除了網路頻寬不夠快的情況,或者是主機沒有足夠的記憶體空間來建立子執行緒進行快照儲存,或是記錄積壓的寫命令的記憶體不夠。 儘管不是必須,但是最好還是保證redis主機只用了系統50-65%的記憶體,預留出30-45%的備用記憶體空間來執行bgsave命令和記錄積壓命令(command backlogs) slave的配置很簡單,可以在配置檔案中配置slaveof host port,或是在執行的時候執行slaveof命令。 如果用的是配置檔案方式,redis在啟動初始化時就會先載入快照或aof檔案,然後連線到主機執行上面表中的流程。如果是命令方式,redis會立刻連線主機,如果連線成功,就會執行上面表中的流程。
- 同步過程中,slave會重新整理所有的資料
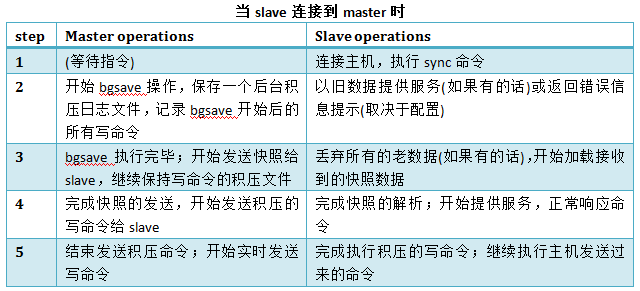
就是為了保證資料一致性:當slave連線到master時,任何當前記憶體中儲存的資料都會被清除,替換成從master機器傳送過來的資料。
- 警告:redis不支援主機和主機之間的複製
有時候可能會出現下面這種配置:兩臺redis伺服器相互做主從關係(都配置slaveof指向對方)。顯然這種配置是不起作用的。兩臺機器會來回通訊,依賴於我們連線哪臺機器去查詢,可能會導致我們獲取的資料不一致或者根本獲取不到資料。當多個slave嘗試去連線redis時,可能會有不同的情況發生

對大多數情況,redis會保證只做必要的工作。某些情況下,slave會在不恰當的 時機去連線主機,這樣會導致主機做更多的工作。另一方面,多個slave在同時連線主機時,最初用來保證slave同步的頻寬會佔用很多資源,可能造成其他的命令很難通過,同時可能造成網路速度變慢,影響同一網路下的其他裝置。
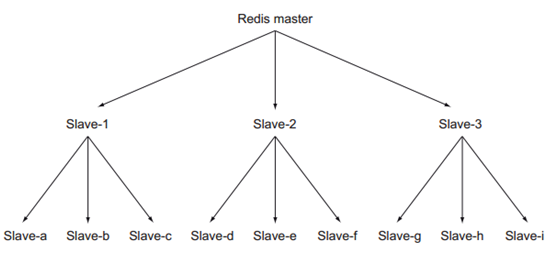
主/從伺服器鏈(Master/slave chains)
當我們去新增很多個slave節點時,會發現有時候網路跟不上(尤其是在網際網路上或是兩個資料中心之間)。由於主機和從機之間沒有什麼區別,slave節點也可以有自己的slave節點,這樣就可以形成主/從伺服器鏈 當讀負載明顯高出寫負載時,或者是當讀資料的請求量超出了一個單機redis的處理範圍。常見的處理方法就是給主機新增從節點來分攤壓力。 當負載持續增長時,總會有某一個時刻,單個的redis主機伺服器無法及時同步資料到所有的slave節點(或者是在同步或連線是超載了)。為了緩解這種問題,我們可以建立一個能夠進行主/從複製的中間層的redis節點,如下圖:
說回aof資料備份方式,這種方式會同步所有的寫操作到硬碟中,以此防止資料的丟失,但是也嚴重限制了伺服器的效能。或者設定成每秒同步一次,效能會好很多,但是可能丟失這一秒鐘內的資料。 對於上面的問題,可以結合使用叢集複製和aof檔案備份方式來解決上面的問題。 為了保證資料存放在多個機器的磁碟上,必須顯示的設定主機和從機。通過配置appendonly yes和appendfsync everysec兩個引數,可以使這組叢集機器每秒同步資料到硬碟。但是我們必須等待資料一一同步到各個從節點。
驗證硬碟寫操作(verifying disk writes)
要檢查寫入主節點的資料是否同步到了從節點很簡單,只需要在每次重要資料操作之後都輸出一個唯一的臨時檔案,然後在slave節點上去驗證這個檔案。
通過
info
命令檢視redis伺服器的各個狀態資訊
系統故障處理(handling system failures)
如果我們將redis作為我們應用的唯一資料庫,就必須保證我們永遠不丟失資料。不像傳統資料庫的4個特性:原子性(atomicity),一致性(consistency),隔離性(isolation)和永續性(durability)。redis需要做一些額外的工作來保證資料的一致性。1.驗證快照和aof檔案
當系統崩潰時,我們有工具來幫助自己恢復資料。 redis-check-aof :檢測aof檔案的狀態 redis-check-dump :檢測dump快照檔案的狀態
如果提供了--fix引數,命令就會修復這個引數指定的aof檔案。通過掃描aof檔案,查詢未完成或錯誤的命令,從第一個錯誤的命令開始,丟棄後面所有的部分。 目前沒有修復損壞的快照檔案的工具,儘管我們同樣可以發現第一個錯誤命令發生的地方,但是因為快照本身被壓縮了,中途錯誤可能導致檔案不可讀取。由於這個原因,建議對重要的快照檔案保留多個備份,在恢復的同時通過計算sha1和sha256來驗證內容。 checksums and hashes:CRC family checksum適合發現網路傳輸或磁碟損壞的錯誤。hash密碼適合發現任意的錯誤。2.替換故障的主機(replacing a failed master)
場景: A機器跑了一個redis的master節點,B機器跑了一個slave節點。由於某些目前無法確定的原因,A機器失去了網路連線。但是我們有一個C機器安裝了。 方案: B機器執行save命令,儲存當前最新的快照檔案,拷貝快照檔案到C 機器的指定目錄。啟動C機器載入快照資料到記憶體中。告訴B機器去連線C機器,作為其slave幾點。關鍵字:redis sentinel(哨兵):該工具可以自動檢測處理節點宕機的情況。
- B機器執行save命令
- 拷貝dump.rdb到C機器的redis目錄下
- 啟動C機器
- B機器執行slaveof host port 指向C機器。
