
完全分散式Hadoop叢集的安裝搭建和配置(4節點)
Hadoop版本:hadoop-2.5.1-x64.tar.gz
學習參考了給力星http://www.powerxing.com/install-hadoop-cluster/的兩個節點的hadoop搭建過程,我用VirtualBox開了四個Ubuntu(版本15.10)虛擬機器,搭建了四個節點的Hadoop分散式叢集,並配置了HA,適合首次搭建的同學參考,節點設計如下:
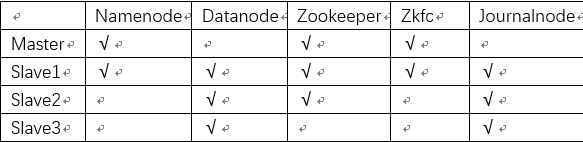
一、準備工作
在Master節點完成基本工作,包括配置Hadoop使用者,安裝配置ssh,安裝配置java環境,這個階段給力星同學寫得很詳細,每一步都有解釋。1、新建hadoop使用者
建議安裝虛擬機器時使用hadoop使用者名稱,如果不是,新增一個hadoop使用者:sudo useradd -m hadoop -s /bin/bash為hadoop使用者設定密碼,建議所有密碼都設定為hadoop:
sudo passwd hadoopsudo adduser hadoop sudo最後登出當前使用者(點選螢幕右上角的齒輪,選擇登出),在登陸介面使用剛建立的 hadoop使用者進行登陸。用 hadoop 使用者登入後,我們先更新一下 apt,方便後續安裝軟體:
sudo apt-get update安裝Vim進行文字編輯:
sudo apt-get install vim2、安裝配置ssh
叢集、單節點模式都需要用到 SSH 登陸(類似於遠端登陸,你可以登入某臺 Linux 主機,並且在上面執行命令),Ubuntu 預設已安裝了 SSH client,此外還需要安裝 SSH server:
sudo apt-get install openssh-server配置ssh無密碼登入的步驟我們後邊再做。
3、安裝配置java環境
直接通過命令安裝 OpenJDK7:
sudo apt-get install openjdk-7-jre openjdk-7-jdk安裝好 OpenJDK 後,需要找到相應的安裝路徑,這個路徑是用於配置 JAVA_HOME 環境變數的。執行如下命令:
dpkg -L openjdk-7-jdk | grep '/bin/javac'該命令會輸出一個路徑,除去路徑末尾的 “/bin/javac”,剩下的就是正確的路徑了。如輸出路徑為/usr/lib/jvm/java-7-openjdk-amd64/bin/javac,則我們需要的路徑為/usr/lib/jvm/java-7-openjdk-amd64。接著配置 JAVA_HOME 環境變數,為方便,我們在 ~/.bashrc 中進行設定:
vim ~/.bashrc在檔案最前面新增如下單獨一行(注意 = 號前後不能有空格),將“JDK安裝路徑”改為上述命令得到的路徑,並儲存:
export JAVA_HOME=JDK安裝路徑接著還需要讓該環境變數生效,執行如下程式碼:
source ~/.bashrc # 使變數設定生效【在 Linux系統中,~代表的是使用者的主資料夾,即“/home/使用者名稱”這個目錄,如你的使用者名稱為hadoop,則 ~就代表 “/home/hadoop/”。】
4、克隆節點
我把Master節點在Virtualbox中克隆了3次,分別命名Slave1,Slave2和Slave3,網路連線方式改為橋接,在所有節點上都要做如下2件事:
修改主機名,和我們設定的節點名稱對應(重啟系統生效):vim /etc/hostname把你的所有主機名和對應的ip地址加進去(ifconfig檢視本機ip)
vim /etc/hosts所有節點都完成後,測試一下能不能ping通。
ping Slave1 -c 3 # ping Slave1節點,-c3表示只ping 3次,按Ctrl+c中斷命令5、配置ssh無密碼登入
在Master節點執行:cd ~/.ssh/ # 若沒有該目錄,請先執行一次ssh localhost,然後使用exit退出
ssh-keygen -t rsa # 會有提示,都按回車就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授權
接著在 Master 節點將公匙傳輸到 Slave1 節點:
scp ~/.ssh/id_rsa.pub [email protected]:/home/hadoop/然後在Slave1節點上操作,將 ssh 公匙加入授權:
mkdir ~/.ssh # 如果不存在該資料夾需先建立,若已存在則忽略
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 用完就可以刪掉了
在別的Slave節點上也要做傳輸和授權公鑰的步驟!
這樣,在 Master 節點上就可以無密碼 SSH 到各個 Slave 節點了。
【scp 是 secure copy 的簡寫,用於在 Linux 下進行遠端拷貝檔案,類似於 cp 命令,不過 cp 只能在本機中拷貝。如果在scp傳檔案時報錯,出現permission denied,到目標檔案修改許可權就行了:
sudo chown –R hadoop 路徑
如果修改許可權時報錯:/etc/sudoers屬於使用者id1000應為0或沒有找到有效的sudoers資源,把上述命令中的sudo去掉就行了】
二、安裝配置Hadoop
1、主節點安裝和配置hadoop
我使用的是2.5.1的64位版本,安裝包放在了“~/下載”這個路徑下,Master節點下執行:
sudo tar -zxf ~/下載/hadoop-2.6.0.tar.gz -C /usr/local # 解壓到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.6.0/ ./hadoop # 將資料夾名改為hadoop
sudo chown -R hadoop ./hadoop # 修改檔案許可權
裝完後要改配置檔案,Hadoop 的配置檔案位於 /usr/local/hadoop/etc/hadoop/ 中,在主節點Master上述目錄下修改core-site.xml和hdfs-site.xml和slaves這三個配置檔案:
vim core-site.xml<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://myhadoop</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>Master:2181,Slave1:2181,Slave2:2181</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop2</value>
</property>
</configuration>
vim hdfs-site.xml新增如下內容:
<configuration>
<property>
<name>dfs.nameservices</name>
<value> myhadoop </value>
</property>
<property>
<name>dfs.ha.namenodes. myhadoop </name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.myhadoop.nn1</name>
<value>Master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.myhadoop.nn2</name>
<value>Slave1:8020</value>
</property>
<property>
<name>dfs.namenode.http-address. myhadoop.nn1</name>
<value>Master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address. myhadoop.nn2</name>
<value>Slave1:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://Slave1:8485;Slave2:8485;Slave3:8485/ myhadoop </value>
</property>
<property>
<name>dfs.client.failover.proxy.provider. myhadoop </name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/jn/data</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
最後修改這個:
vim slaves新增如下內容(標示DataNode節點):
Slave1
Slave2
Slave3
2、把配好的hadoop傳給別的節點
cd /usr/local
sudo rm -r ./hadoop/tmp # 刪除 Hadoop 臨時檔案
sudo rm -r ./hadoop/logs/* # 刪除日誌檔案
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先壓縮再複製
cd ~
scp ./hadoop.master.tar.gz Slave1:/home/hadoop
scp ./hadoop.master.tar.gz Slave2:/home/hadoop
scp ./hadoop.master.tar.gz Slave3:/home/hadoop
然後在所有Slave節點執行:
sudo rm -r /usr/local/hadoop # 刪掉舊的(如果存在)
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop
三、配置HA和啟動
1、zookeeper
下載zookeeper包(我用的3.4.6版本)解壓到/user/local並改成簡單的名子zookeeper(這個過程的操作和裝Hadoop包那一步是一樣的),複製這個目錄下的conf目錄裡的zoo_sample.cfg檔案,重新命名為zoo.cfg儲存在同目錄,命令如下:
cp -a zoo_sample.cfg zoo.cfg然後修改zoo.cfg,命令如下:
vim zoo.cfg
修改dataDir後的路徑為/opt/zookeeper(這是在opt目錄建立一個zookeeper的檔案),接著在最後新增如下三行(就是在這三個節點上配置zookeeper):
server.1=Master:2888:3888
server.2=Slave1:2888:3888
server.3=Slave2:2888:3888
然後在opt目錄下建立zookeeper檔案,在檔案內新建一個myid檔案並修改:
mkdir /opt/zookeeper
cd /opt/zookeeper/
vim myid
新增一個數字1就行,然後把zookeeper目錄傳到別的zk節點(即slave1和2)的相同目錄(和傳ssh公鑰的操作相同),並修改myid.(Slave1修改為2,Slave2修改為3)
然後給zk新增Path變數(這一步各個zk節點都要做,也就是要做3次):
vim /etc/profile新增這麼一行:
export PATH=$PATH:/usr/local/zookeeper/bin然後使之生效:
source /etc/profile然後就能在任意目錄下啟動zk了(這也就是給zk新增PATH變數的原因):
zkServer.sh start輸入jps命令檢視一下,有QuorumPeerMain就說明zookeeper啟動成功了。
【如果防火牆沒關,可能會報錯,關防火牆指令:service iptables stop】
2、JournalNode
可在所有Slave節點上啟動journalnode:
hadoop-daemon.sh start journalnode3、配置Hadoop的PATH路徑
因為hadoop很多命令都是在安裝目錄下執行的,所以我們可以將 Hadoop 安裝目錄加入 PATH 變數中,這樣就可以在任意目錄中直接使用hdfs等命令了,如果還沒有配置的,需要在 Master 節點上進行配置。首先執行 vim ~/.bashrc,加入一行:
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin儲存後執行 source ~/.bashrc 使配置生效。
4、主備NameNode
首次啟動hadoop需要先在 Master 節點執行 NameNode 的格式化:
hdfs namenode -format # 首次執行需要執行初始化,之後不需要因為Slave1是備用的NameNode節點,它要複製主節點的元資料(儲存在Master的/opt/hadoop2/dfs/name/current中),在複製之前,要先開啟Master節點的NameNode:
hadoop-daemon.sh start namenode然後再Slave1節點執行:
hdfs namenode -bootstrapStandby5、zkfc
啟動前要先格式化:
hdfs zkfc -formatZK沒有error就行,然後可以把所有的都啟動起來了:
start-dfs.sh各個節點執行jps,Master節點應該有jps、NameNode、QuorumPeerMain、DFSZKFailoverConteroller四個服務,Slave1節點應該有前邊4個外加DataNode和journalnode共6個,Slave2節點應該有jps、QuorumPeerMain、DataNode和journalnode四個服務,Slave3節點應該有jps、DataNode和journalnode三個服務。
【如果出現所有的datanode節點沒有啟動,別的正常啟動的情況,把你的每個Slave節點的/opt/hadoop2/dfs/目錄下的data檔案刪除,然後再開啟試試。】
6、上傳檔案
hdfs dfs -mkdir -p /usr/file #新建hdfs一個目錄
hdfs dfs -put /home/hadoop/test /usr/file #put上傳
四、配置YARN
這裡和給力星的配置有差別,建議用我下邊的配置,不然可能會有節點掉線的情況。找到mapred-site.xml檔案(和core-site.xml檔案在一個目錄),新增如下內容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
再找到yarn-site.xml檔案(和core-site.xml檔案在一個目錄),新增如下內容:
<configuration>
<property>
<name>yarn.resourcemanager.hostname </name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name> yarn.nodemanager.aux-services.mapreduce.shuffle.class </name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>