
《推薦系統》003 基於物品的最近鄰推薦
在基於使用者的最近鄰推薦演算法中,使用者資訊的大批量計算是很難達到實時性要求的。而基於物品的最近鄰推薦演算法通常線上下進行預處理,所以能夠實現實時計算。
預處理的時候會建立物品相似度矩陣,描述物品之間兩兩相似度關係。近鄰的數量受使用者已經評論物品數量的限制。
基於物品的最近鄰推薦
其主要思想就是利用物品之間的相似性而不是使用者之間的相似性來預測。
餘弦相似度的計算
在基於物品的最近鄰推薦的演算法中 ,相似度的計算較為精確的是餘弦相似度的演算法。
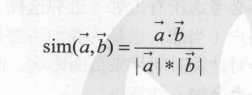
這種相似度的計算往往不會考慮到平均值的問題。
所以,改進型的餘弦相似度解決了這個問題:
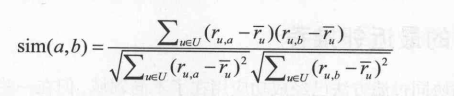
類似的,我們基於上一篇文章中的案例計算物品間的相似度問題:

以物品1和物品5為例,計算物品相似度:
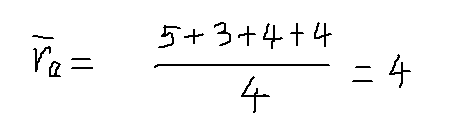

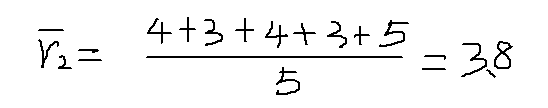
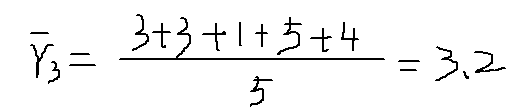
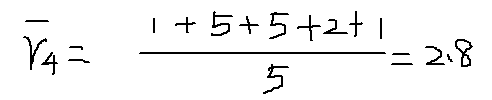
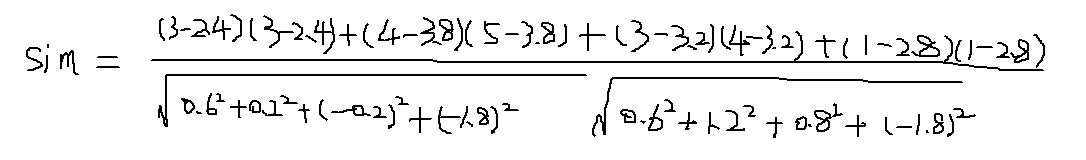
類似於基於使用者的最近鄰推薦演算法,也會計算一個推薦分數:
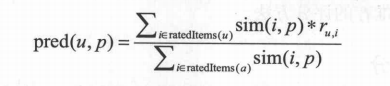
相關推薦
《推薦系統》基於標籤的使用者推薦系統
1:聯絡使用者興趣和物品的方式 2:標籤系統的典型代表 3:使用者如何打標籤 4:基於標籤的推薦系統 5:演算法的改進 6:標籤推薦 一:聯絡使用者興趣和物品的方式 推薦系統的目的是聯絡使用者的興趣和物品,這種聯絡
《推薦系統》003 基於物品的最近鄰推薦
在基於使用者的最近鄰推薦演算法中,使用者資訊的大批量計算是很難達到實時性要求的。而基於物品的最近鄰推薦演算法通常線上下進行預處理,所以能夠實現實時計算。 預處理的時候會建立物品相似度矩陣,描述物品之間兩兩相似度關係。近鄰的數量受使用者已經評論物品數量的限制。 基於物品的最近
《推薦系統》002 基於使用者的最近鄰推薦
協同過濾: 利用已經存在的使用者群體,對當前的使用者的喜好進行推測。 基於使用者的最近鄰推薦: 先找出與當前使用者喜好相似的使用者資訊,然後根據他們的評價體系對當前使用者對未知物品的評價等級。 前提假設: 1
機器學習-推薦系統中基於深度學習的混合協同過濾模型
近些年,深度學習在語音識別、影象處理、自然語言處理等領域都取得了很大的突破與成就。相對來說,深度學習在推薦系統領域的研究與應用還處於早期階段。 攜程在深度學習與推薦系統結合的領域也進行了相關的研究與應用,並在國際人工智慧頂級會議AAAI 2017上發表了相應的研究成果《A Hy
基於物品(使用者)的推薦演算法
mapreduce 用mapreduce計算框架實現了3個小demo: wordcount、基於物品的推薦演算法(itemCF)和基於使用者的推薦演算法(userCF) 程式碼連線: https://github.com/marvelousgirl/mapreduce item
吳恩達機器學習(十四)推薦系統(基於梯度下降的協同過濾演算法)
目錄 0. 前言 學習完吳恩達老師機器學習課程的推薦系統,簡單的做個筆記。文中部分描述屬於個人消化後的理解,僅供參考。 如果這篇文章對你有一點小小的幫助,請給個關注喔~我會非常開心的~ 0. 前言 在推薦系統中,主要有兩種方法,基於內容的推薦
推薦系統之基於領域的協同過濾
(作者:陳玓玏) 主要是看《推薦系統實踐》這本書做的筆記,寫得不好請見諒,一些我自己的拙見有需要討論的可以留言,謝謝! 1. 分類及度量 1、 評分預測:預測使用者對物品的評分,用RMSE和MAE做度量 2、 Top N推薦:給出個性化推薦列表,預測準確率通過準
新聞推薦系統:基於內容的推薦演算法——TFIDF、衰減機制(github java程式碼)
轉自:因為開發了一個新聞推薦系統的模組,在推薦演算法這一塊涉及到了基於內容的推薦演算法(Content-Based Recommendation),於是藉此機會,基於自己看了網上各種資料後對該分類方法的理解,用盡量清晰明瞭的語言,結合演算法和自己開發推薦模組本身,記錄下這些過
推薦系統學習--基於item的協同過濾演算法及python實現
轉載地址:http://blog.csdn.net/gamer_gyt/article/details/51346159 1:協同過濾演算法簡介 2:協同過濾演算法的核心 3:協同過濾演算法的應用方式 4:基於使用者的協同過濾演算法實現
推薦系統_基於內容的推薦
關於推薦系統的演算法大概可以分類兩類: 一類就是基於使用者或者基於商品的協同過濾,我們主要是通過使用者行為這個海量資料來挖掘出使用者在品味上的一些相似程度,或者說 商品的相似程度,然後我們在利用相似性來進行推薦。 另一類就是更早期的,而且更加容
推薦系統學習——基於概率分析的方法
用途:預測使用者對物品評分 輸入:所有使用者對所有物品的評分矩陣 輸出:使用者A對物品I的評分 預測使用者A對物品I的所有可能評分的概率,然後選出概率最大的評分作為輸出 物品1 物品2 物品3 物品4
基於Spark實現推薦演算法-4:基於物品的協同過濾(實現篇)
演算法設計與實現 基於物品的協同過濾又稱Item-Based CF. 基於Spark的Item-Based CF演算法其實現原理和步驟與經典方法基本一致,不同的地方主要在於具體步驟內的並行化計算。 相似度演算法 在Spark MLlib中提供了餘弦相
《推薦系統》基於使用者和Item的協同過濾演算法的分析與實現(Python)
開啟微信掃一掃,關注《資料與演算法聯盟》1:協同過濾演算法簡介2:協同過濾演算法的核心3:協同過濾演算法的應用方式4:基於使用者的協同過濾演算法實現5:基於物品的協同過濾演算法實現一:協同過濾演算法簡介 關於協同過濾的一個最經典的例子就是看電影,有時候不知道哪一部電影是
新聞推薦系統:基於內容的推薦演算法(Recommender System:Content-based Recommendation)
2018/10/04更新 這篇文章似乎被越來越多的小夥伴看到了,所以覺得有必要做一些進一步的詳細說明。 首先按照本文所講解的推薦思路進行新聞推薦的推薦系統,我已經實現並已經放在Github上了。歡迎小夥伴們積極star和fork,更歡迎隨時提建議,我們一起交
推薦系統中基於深度學習的混合協同過濾模型
【宣告:鄙人菜鳥一枚,寫的都是入門級部落格,如遇大神路過鄙地,請多賜教;內容有誤,請批評指教,如有雷同,屬我偷懶轉運的,能給你帶來收穫就是我的部落格價值所在。】 歡迎各路大神小妖精來這看我的部落格,這周太忙了,明早要趕飛機參加一個沙漠拓展活動,就匆匆整了篇
推薦系統之基於內容推薦CB
(個性化)推薦系統構建三大方法:基於內容的推薦content-based,協同過濾collaborative filtering,隱語義模型(LFM, latent factor model)推薦。這篇部落格主要講基於內容的推薦content-based。 基於內容的推薦
推薦系統之基於圖的推薦:基於隨機遊走的PersonalRank演算法
一 基本概念 基於圖的模型是推薦系統中相當重要的一種方法,以下內容的基本思想是將使用者行為資料表示為一系列的二元組,每一個二元組(u,i)代表使用者u對物品i產生過行為,這樣便可以將這個資料集表示為一個二分圖。 假設我們有以下的資料集,只考慮使用者喜不喜歡該物品而不考慮使用
推薦系統實踐----基於使用者的協同過濾演算法(python程式碼實現書中案例)
本文參考項亮的《推薦系統實踐》中基於使用者的協同過濾演算法內容。因其中程式碼實現部分只有片段,又因本人初學,對python還不是很精通,難免頭大。故自己實現了其中的程式碼,將整個過程走了一遍。 1. 過程簡述 a. 首先我們因該先找到和目標使用者興趣相似的使用者集合。簡單來
【推薦系統】基於內容的推薦系統和基於知識的推薦系統
1、基於內容的推薦系統 (1)基於內容的推薦演算法概述 基於內容的推薦演算法(Content-based Recommendations, CB)也是一種工業界應用比較廣的一種推薦演算法。由於協同過濾推薦演算法中僅僅基於使用者對於商品的評分進行推薦,所以有可
推薦演算法之基於物品的協同過濾
基於物品的協同過濾( item-based collaborative filtering )演算法是此前業界應用較多的演算法。無論是亞馬遜網,還是Netflix 、Hulu 、 YouTube ,其推薦演算法的基礎都是該演算法。為行文方便,下文以英文簡稱ItemCF表示。本文將從其基礎演算法講起,一步步進行