
Spark troubleshooting yarn佇列資源不足
生產環境配置 以及對應問題
spark用的yarn資源佇列的情況:500G記憶體,200個cpu core
啟動Spark application spark-submit配置 80個 executor 每個executor 4g記憶體,2個cpu core
--executor-cores 2
--executor-memory 4g
每次執行spark作業 大概耗費320G記憶體,160個cpu core
乍看起來,咱們的佇列資源,是足夠的,500G記憶體,280個cpu core。
首先,第一點,你的spark作業實際執行起來以後,耗費掉的資源量,可能是比你在spark-submit裡面配置的,以及你預期的,是要大一些的。400G記憶體,190個cpu core。
那麼這個時候,的確,咱們的佇列資源還是有一些剩餘的。但是問題是,如果你同時又提交了一個spark作業上去,一模一樣的。那就可能會出問題。
第二個spark作業,又要申請320G記憶體+160個cpu core。結果,發現佇列資源不足。。。。
此時,可能會出現兩種情況:(備註,具體出現哪種情況,跟你的YARN、Hadoop的版本,你們公司的一些運維引數,以及配置、硬體、資源肯能都有關係)
1、YARN,發現資源不足時,你的spark作業,並沒有hang在那裡,等待資源的分配,而是直接列印一行fail的log,直接就fail掉了。
2、YARN,發現資源不足,你的spark作業,就hang在那裡。一直等待之前的spark作業執行完,等待有資源分配給自己來執行。
解決方案
1、在你的J2EE(我們這個專案裡面,spark作業的執行,之前說過了,J2EE平臺觸發的,執行spark-submit指令碼),限制,同時只能提交一個spark作業到yarn上去執行,確保一個spark作業的資源肯定是有的。
2、你應該採用一些簡單的排程區分的方式,比如說,你有的spark作業可能是要長時間執行的,比如執行30分鐘;有的spark作業,可能是短時間執行的,可能就執行2分鐘。此時,都提交到一個佇列上去,肯定不合適。很可能出現30分鐘的作業卡住後面一大堆2分鐘的作業。分佇列,可以申請(跟你們的YARN、Hadoop運維的同學申請)。你自己給自己搞兩個排程佇列。每個佇列的根據你要執行的作業的情況來設定。在你的J2EE程式裡面,要判斷,如果是長時間執行的作業,就乾脆都提交到某一個固定的佇列裡面去把;如果是短時間執行的作業,就統一提交到另外一個佇列裡面去。這樣,避免了長時間執行的作業,阻塞了短時間執行的作業。
3、你的佇列裡面,無論何時,只會有一個作業在裡面執行。那麼此時,就應該用我們之前講過的效能調優的手段,去將每個佇列能承載的最大的資源,分配給你的每一個spark作業,比如80個executor;6G的記憶體;3個cpu core。儘量讓你的spark作業每一次執行,都達到最滿的資源使用率,最快的速度,最好的效能;並行度,240個cpu core,720個task。
4、在J2EE中,通過執行緒池的方式(一個執行緒池對應一個資源佇列),來實現上述我們說的方案。
所有executor能使用的核心數 如果不設定預設叢集所有core
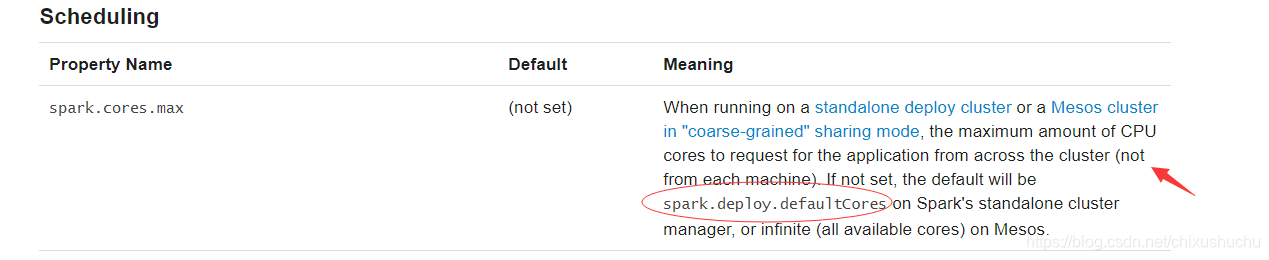

yarn模式 一個executor預設開啟1個core