
從零開始學習PYTHON3講義(九)字典型別和插入排序

《從零開始PYTHON3》第九講
第六講、上一講我們都介紹了列表型別。列表型別是程式設計中最常用的一種型別,但也有挺明顯的缺陷,比如:
data = [5,22,34,12,87,67,3,43,56,23]還記得讓程式更友好的概念嗎?上一條語句所定義的列表,我們沒辦法很容易的知道這些值代表什麼、有什麼用、附加什麼樣的操作對這個列表來說才有意義。
在現實的場景中,往往應當是類似這樣的情形,比如有一份學習成績單:
Harry:87分
Joe:90分
Yolanda:67分
Aaron:88分
Charles:79分
Fred:93分為了有意義的描述這個成績單,我們可能需要用類似這樣的方法:
name = ['Harry','Joe','Yolanda','Aaron','Charles','Fred']
score = [87,90,67,88,79,93]這樣,想顯示第3個同學的考試成績,我們可以使用這樣的方式:
print(name[2],score[2]) #陣列下標從0開始計數利用Python同一個列表中可以儲存不同資料型別的特徵,還可以使用這樣的方案:
students = ["Harry",87,"Joe",90,"Yolanda",67,"Aaron",88,"Charles",79,"Fred",93]這樣想顯示一個同學的成績,可以這樣做(i在這裡代表從0計數,顯示第i個學生):
print(students[i*2],students[i*2+1])除此之外,還可以使用多維列表的方法。多位列表指的是2維以及2維以上的列表,我們之前學習的,都是1維列表。先舉一個另外的例子,比如我們有這樣一個數學矩陣:
$$
A = \left{
\begin{matrix}
2 & 3 & 4 \
5 & 6 & 7 \
8 & 9 & 10
\end{matrix}
\right}\tag{1}
$$
想使用列表來表示,可以用這樣的形式:
A = [[2, 3, 4], [5, 6, 7], [8, 9, 10]]也就是列表中的列表,或者稱2維列表。
矩陣的概念如果有的同學還沒有學習過,可以先不用管,這不是本課程的重點,不影響你學習程式設計的概念。不過還是要強調一下,數學中的矩陣運算是非常重要的部分,在人工智慧、圖形、影象、視訊、聲音的處理中,都非常頻繁的使用。
話題再拉回剛才講到的學生成績單,如果使用2維列表的方法,可以這樣處理:
students = [["Harry",87],["Joe",90],["Yolanda",67],["Aaron",88],["Charles",79],["Fred",93]]顯示學生成績則使用(i的含義同上):
print(students[i][0],students[i][1])我們已經講述了三種方法,讓列表的使用,更有實際的意義,同時也更友好。
如果只是處理類似這樣學生成績單的問題,Python中有一個更適用的資料型別,也是我們學的第四種資料型別,字典。
字典型別
使用字典來表示我們上面講過的程式單,簡直不能更合適:
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}跟列表的區別,首先使用的是“{}”大括號將立即數資料包裹起來。
其次,列表的每一個元素,是一對兒值,而不是列表中的一個值。一對兒值之間,使用“:”分割。冒號前面的部分稱為key,或者叫“關鍵字”;冒號後面的部分稱為value,或者稱為“值”。這樣的一對兒值習慣上稱為key-value對兒。
注意別把字典中的關鍵字,跟Python中指命令的關鍵字弄混。後者就是關鍵字,前者更類似列表中的下標。
訪問資料的時候,使用下面的形式:
>>> print(students["Harry"])
87 #使用學生名稱,直接獲取到學生的成績上面語句中,訪問字典型別跟訪問列表很像,只是列表強制規定下標必須是以0開始的連續整數數字;而字典則使用該項的名稱部分,也就是關鍵字部分。當然啦,關鍵字也可以使用數字變數,這時候會跟列表型別非常像,要留神別搞混了。
同列表一樣,字典型別,也是可以修改的型別。Python只有列表、字典兩種型別允許修改。其它型別都是隻讀型別。修改字典中的資料使用:
students["Harry"] = 91對於一個已經存在的字典變數,還可以為其增加資料,比如:
students["Andrew"] = 91當字典中當前不存在“Andrew”這個學生的話,上面語句將在字典中新增一個元素,其關鍵字為“Andrew”,值是91。
本例中我們使用學生的名字作為字典的關鍵字來舉例,但前面說了,字典並非必須使用字串作為“下標”名。比如:
dict1 = { 1:"abcd",4:"789a",6:"point" }這個字典跟“成績單”的例子相反,使用數字作為關鍵字,使用字串當做值。訪問的時候使用這種形式:
>>> print(dict1[4])
'789a' 訪問的方法跟列表一模一樣,如果不看賦值的部分,太容易弄混了。不過不用擔心,兩種資料型別通常都應用在不同的場景,只要你的變數名起的比較易記、易讀,通常不會出現你擔心的情況。
獲取字典中元素的個數同樣使用len函式,不過要注意,字典中的每個元素指的是一對兒。就是說關鍵字和值一起記為1個元素:
len(students)字典看起來很像序列型別,但實際本身並不是。原因是,字典並沒有列表下標這樣的概念來天然的為字典指定一個固有的順序。想有序的訪問字典,需要使用內建的函式轉換,以for迴圈遍歷為例:
for k,v in students.items(): #items()返回的是序列型別
print(k,v)items內建函式返回的序列並不是單個值,而是用逗號隔開的一對兒值,也就是一個元組。
元組是Python六個基本型別中的第5個。其實我們前面也見到過了很多次元組的應用,只是並不知道元組這個名字。
比如多重賦值就是元組:
a,b,c = 1,2,3元組型別也是一種序列型別,可以使用for來遍歷。但元組型別是隻讀型別,不能更改其內容。
元組雖然經常用到,但並沒有過多的附加概念和難以理解的內容。我們還是繼續講述字典的常用操作。
字典的初始化(賦值)有兩種形式:
#第一種形式我們前面一直在用
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
#第二種形式實際是一組關鍵字、值的元組,然後使用dict函式轉換成字典
students = dict(Harry=87,Joe=90,Yolanda=67,Aaron=88,Charles=79,Fred=93)注意第二種形式實際也是我們平常使用函式呼叫時候引數所使用的方式,可能看起來並不完全相同,但實際就是一回事。不過這個概念不用著急理解,你慢慢的會習慣。
再來看看列表和字典兩種型別的區別:
| 列表型別 | 字典型別 |
|---|---|
| 以下標順序為序 | 以加入的順序為序 |
| 使用數字(下標)訪問 | 使用關鍵字(標誌字)訪問 |
因為字典中元素加入是有順序的,但實際這種順序有很大的隨機性。所以在使用字典的時候,除非你很清楚元素新增的邏輯,否則你應當假定字典是亂序的,或者說沒有順序。前面也已經說過,字典型別不是序列型別。
*匿名函式
匿名函式很有用,但是有一點學習難度,我們只是為了繼續引出關於列表和字典的一些操作概念。所以如果這一節和下一節中,不能馬上看懂的話,可以先做了解,能記住多少就算多少。將來真正操作用的多了,自然可以慢慢理解。
概念上說,匿名函式可以說是普通函式的簡寫形式,比如:
#傳統的函式定義方式:
def calc(x)
return x ** x
#匿名函式的定義方式:
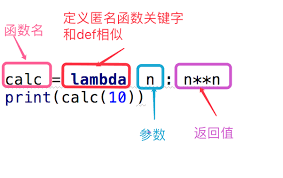
calc1 = lambda x : x**x
#呼叫起來是一樣的
print(calc(10))
print(calc1(10))
注意匿名函式的宣告方式,首先是使用lambda關鍵字,而不是def,接著是函式的引數,冒號之後就是函式本身。
匿名函式適合用在非常簡單的小函式中,這樣這種簡寫的形式,往往一行就完成,才顯示出來匿名函式的優勢。我們前面還講過,函式其實也是變數的一種,現在使用匿名函式這種寫法,你可能理解了這句話了。
我們再看一個例子:
#傳統的函式定義方式:
def add(x,y)
return x+y
#匿名函式的定義方式:
add = lambda x,y : x+y匿名函式還適用把函式當做引數的場合中,畢竟函式本身也是變數,變數當做引數我們已經一再見到了。函式當做變數的例子我們後面會看到。
*列表生成表示式
匿名函式就講這些,我們繼續講列表和字典。
講for迴圈的時候,我們曾經講過了range函式,用於生成一個連續序列。當然range函式生成的還不是列表,所以如果希望當做列表使用,還需要使用list()函式轉換一下,比如:
>>> list(range(10)) #實際上是序列轉換成列表
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]這樣的使用方法可以叫“列表生成式”,或者完整的名字“列表生成表示式”。我們來看個更復雜的例子:
>>> a = [x**2 for x in range(10)]
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]這個例子的關鍵在當做列表值來使用的部分,把這部分用大家熟悉了的程式碼重寫一下可能看上去更清楚:
a=[]
for x in range(10):
a.append(x ** 2)列表生成式的形式,很類似匿名函式的形式,但更抽象。
字典也有生成表示式:
>>> a={x:x**2 for x in range(10)}
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}這個字典生成表示式,相當於下面的語句:
a={}
for x in range(10):
a[x]=x**2 #因為"關鍵字"選取了數字,看上去很類似列表,但並不是挑戰
今天的挑戰是:
有一個字典,其中儲存著學生的成績單:
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}請將這個成績單按照成績的多少,從低到高排列。
上面講過,字典實際上是“無序”的型別,想容納有序的資料應當先轉換為其它有序的資料型別,比如列表。
轉換的方法可以使用for迴圈遍歷的方法,完整的遍歷整個字典。
因為在遍歷的時候每次都是拿到一組新資料,插入到陣列中,所以這種請境況下使用插入排序法,比氣泡排序效果更好。
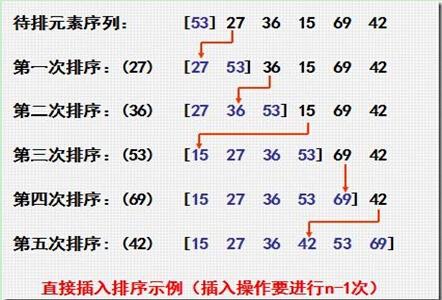
對照上圖,我們來說說插入排序的方法。在一開始,我們假設列表中只有一個值,比如53。然後每次迴圈,我們加入1個新的元素,把這個元素,同當前表中的資料逐個比對,根據大小放到合適的位置。
這樣迴圈,直至所有資料都插入列表中。因為每次插入的時候都對資料做了比較,並且放入了合適位置。插入結束,就等於排序結束。通常情況下插入排序都比氣泡排序效率要高。
看完了原理,思考一下,理清思路,弄明白核心的理念,然後我們繼續看插入排序的原始碼。
#排序字典版
#作者:andrew
#原始資料
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
sortedLists =[]
#插入排序
def insert(l,b):
i=0
for x in l:
if x[1]>b[1]:
l.insert(i,b)
return
i += 1
l.append(b)
print("排序前:",students)
for k,v in students.items():
insert(sortedLists,[k,v])
print("排序後:",sortedLists)程式一開始初始化了字典,定義的sortedLists變數是一個空的列表,用於儲存排序後的值,原因剛才說了,是因為字典不擅長儲存有序的內容。
程式最後的部分是主流程,先顯示排序前的字典,隨後遍歷整個字典,每獲取到一對兒值,則呼叫插入排序函式插入到列表中合適的位置。
插入函式中,b引數是一個列表引數,但其內容實際是原來的關鍵字-值對兒。因為被封裝在列表變數中,所以b[0]是關鍵字,b[1]是值。此外這裡使用列表型別的原因,是因為我們排序完成後,儲存在了一個列表型別中,實際是列表中的列表的形式。
排序方法使用for迴圈,遍歷所有的資料,記住第一次呼叫插入函式的時候,列表中實際上沒有任何元素;第二次呼叫,列表中有1個元素;第三次呼叫,列表中有2個元素,並且排好了序。後續的呼叫都是如此。
因此這裡只要逐個比較列表中已經存在的值,就能找到新插入值應當插入的位置。這個列表是“列表中的列表”形式,所以遍歷用的變數x,實際上也是一個包含兩個值的列表,也就是一個關鍵字-值對兒,跟插入的型別完全相同。
因為我們使用學生成績來排序,所以比較都是比較第二個元素,下標是1。第0個元素是學生的名字。
最後如果迴圈完也沒有找到比新插入值更大的元素,說明要插入的元素已經是最大,應當新增在列表的最後。
程式的執行結果如下:
排序前: {'Harry': 87, 'Joe': 90, 'Yolanda': 67, 'Aaron': 88, 'Charles': 79, 'Fred': 93}
排序後: [['Yolanda', 67], ['Charles', 79], ['Harry', 87], ['Aaron', 88], ['Joe', 90], ['Fred', 93]]Python內建的排序同樣可以對字典型別進行排序,但因為字典型別每個元素是兩個值,需要使用一個匿名函式來指定對哪個值進行排序:
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
sorted(students.items(),key = lambda x:x[1],reverse = True)三點需要說明:1.因為字典不能儲存有序資料,所以使用內建的items()函式轉換成了元組列表型別(列表的元素為元組);2.使用匿名函式,函式引數x會被賦予每一個元素當做引數,剛才說了,每一個元素是一個元組,匿名函式中使用x[1]返回了成績部分,表示使用成績排序;3.reverse=True表示逆序排序,這種逆序的方法在列表排序或者其它排序中都能使用。
再次說明,匿名函式相關的部分,難度有點高,但並沒有完全超出我們的課程的範圍。如果在學習中理解有困難的同學,可以先死記幾種形式來使用。逐漸通過動手操作和練習慢慢理解。
練習時間
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
1.請將上面學生成績表由高分到低分排序排列
2.請將上面學生成績表按照學生姓名的字母順序排列
*3.第五講,象棋麥粒問題中,(國際象棋有8行8列共64格,第1個格子放1粒麥子,第2個格子放2粒麥子,以後每格都比前面格子數量多一倍)
請使用一行程式碼,生成一個字典,字典的關鍵字為格子編號(1-64),值為該格子中的麥粒數量(提示,使用列表生成表示式)
本講小結
- 本講從列表的實際應用開始,匯出了Python的字典型別,並以學生成績單為例講解了基本應用
- 元組是Python的另外一種資料型別,也是序列性的,但不可更改其中的值。元組的應用往往是不知不覺的,一般不用特殊記憶
- Python的常用資料型別到這一講就完成了,還有一種集合型別,在我們的課程中用的少,我們不再講解。更復雜的資料結構就是這些基本型別的組合。不管多麼複雜的實際場景,通過多層次的基本資料型別組合都是能達成的。
- 匿名函式是高階語言的一個特徵,也是函式化程式設計的較新成果。但匿名元素比較抽象,無法馬上掌握的同學不要急,先用背的方法記住一些常用方式,以後在練習中慢慢理解
- 插入排序是另外一種常用的排序方式,速度更快,但有一定的使用條件約束。
練習答案
練習1:
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
sortedLists =[]
#插入排序
def insert(l,b):
i=0
for x in l:
if x[1]<b[1]:
l.insert(i,b)
return
i += 1
l.append(b)
print("排序前:",students)
for k,v in students.items():
insert(sortedLists,[k,v])
print("排序後:",sortedLists)練習2:
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
sortedLists =[]
#插入排序
def insert(l,b):
i=0
for x in l:
if x[0]<b[0]:
l.insert(i,b)
return
i += 1
l.append(b)
print("排序前:",students)
for k,v in students.items():
insert(sortedLists,[k,v])
print("排序後:",sortedLists)*練習3
{i+1:2**i for i in range(64)}匿名函式,列表、字典生成表示式都比較抽象,但能量巨大。
延伸一下,使用一行程式碼完成“棋盤麥粒問題”:
sum([2**i for i in range(64)])