
網路結構搜尋(1)—— NAS(Neural architecture search with reinforcement learning)論文筆記
一、NAS
論文地址:https://arxiv.org/abs/1611.01578
程式碼連線:https://github.com/tensorflow/models
ICLR2017由Googlebrain推出的論文
二、Motivation for architecture search:
•Designing neural network architectures is hard
•Lots of human efforts go into tuning them
•There is not a lot of intuition into how to design them well
•Can we try and learn good architectures automatically?
總結來說就是手工設計網路代價較大,並且並無直覺指導設計,希望能夠自動生成網路結構。
三、Related work:
(1)超引數優化,儘管取得了成功,但這些方法仍然有限,因為他們只能從固定長度的空間搜尋模型。換句話說,要求他們生成一個規定網路結構和連線性的可變長度配置是很困難的。在實踐中,如果這些方法提供了良好的初始模型這些方法往往會更好地工作。有貝葉斯優化方法可以用來搜尋非固定尺寸的建築物,但與本文提出的方法相比,它們不那麼一般和靈活。
注:神經網路架構並不位於歐式空間,因為架構所包含的層級數和引數數量並不確定,很難將引數化為固定長度的向量。傳統的高斯過程(GP)在傳統上是用於歐式空間的,在神經網路搜尋中可以考慮使用貝葉斯優化(後續此係列會對論文:Auto-keras : Efficient Neural Architecture Search with Network Morphism做分析,其中便使用了貝葉斯優化來引導神經網路的態射,在ENAS的基礎上降低計算成本,引入神經網路核(edit-distance)、tree/graph structure採集函式優化演算法)
(2)現代神經進化演算法,例如Wierstra等人(2005年); Floreano等人(2008);另一方面,斯坦利等人(2009)在組成新模型方面更加靈活,然而它們在大規模時是無法實用的。它們的侷限性在於它們是基於搜尋的方法,因此它們很慢或需要許多啟發式才能執行良好。
(3)神經架構搜尋,與程式合成和歸納程式設計有一些相似之處,它們從例子中搜索程式(Summers,1977; Biermann,1978)。在機器學習中,概率性程式誘導已成功用於許多環境中,比如學習簡單問答(Liang et al。,2010; Neelakantan et al。,2015; Andreas et al。,2016),對數字列表(Reed &de Freitas,2015年),並以極少數例子進行學習(Lake等,2015)。
神經架構搜尋中的控制器是自動迴歸的,這意味著它預測一次一次的超引數,並以先前的預測為條件。這個想法是從decoderin端對端序列借鑑序列學習(Sutskever等,2014)。與序列學習序列不同,我們的方法優化了一個不可區分的度量標準,這是子網路的準確性。因此它類似於神經機器翻譯中的BLEU優化工作(Ran-zato等,2015; Shen等,2016)。與這些方法不同,我們的方法直接從沒有任何監督引導的訊號中學習。
與我們的工作相關的還有學習學習或元學習的想法(Thrun&Pratt,2012),這是一個使用在一項任務中學到的資訊來改進未來任務的通用框架。更密切相關的是使用神經網路學習另一網路的梯度下降更新(Andrychowicz et al。,2016)以及使用強化學習為另一網路找到更新策略的想法(Li&Malik,2016)。
meta-learning也是一個大坑。。。待我慢慢挖。。。哭唧唧
四、reinforcement learning 背景介紹:
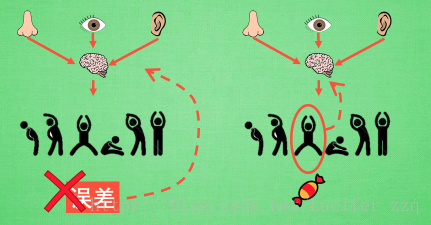
強化學習:是通過和環境互動獲得反饋,再根據反饋調整動作以期望總獎勵最大化。強化學習強調如何基於環境而行動,以取得最大化的預期利益。
loss & reward
強化學習與監督學習的loss訓練方法不同,不是用誤差而是用reward(獎勵機制)來進行更新。
強化學習演算法:
value -based:q learning;sersa;DQN
policy-based:policy gradient(直接輸出行為)
Policy gradient 不像 Value-based 方法 (Q learning,Sarsa),但也要接受環境資訊 (observation),不同的是要輸出不是 action 的 value, 而是具體的那一個 action,這樣 policy gradient 就跳過了 value 這個階段,這種反向傳遞的目的是讓這次被選中的行為更有可能在下次發生。

強化學習的目標函式:
其中E[……]表示在策略πθ條件下一輪互動(0到t步)中的累計獎勵的期望值
五、Methods:
這篇文章通過一個controller在搜尋空間(search space)中得到一個網路結構(child network),然後用這個網路結構在資料集上訓練得到準確率,再將這個準確率回傳給controller,controller繼續優化得到另一個網路結構,如此反覆進行直到得到最佳的結果。

通過一個controllerRNN在搜尋空間(search space)中得到一個網路結構(論文中稱為child network),然後用這個網路結構在資料集上訓練,在驗證集上測試得到準確率R,再將這個準確率回傳給controller,controller繼續優化得到另一個網路結構,如此反覆進行直到得到最佳的結果,整個過程稱為Neural Architecture Search。
(1)如何生成模型:
Question:為什麼用RNN作為controller?
Our work is based on the observation that the structure and connectivity of a neural network can be typically specified by a variable-length string. It is therefore possible to use a recurrent network – the controller – to generate such string.
通過觀察發現目前的神經網路的結構和內部連線是一個可變的長度string來指定的,所以可以使用RNN去產生如此的可變長度的網路結構。
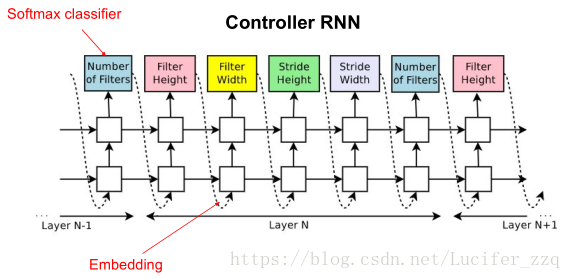
圖中預測的網路只包含conv層,使用RNN去預測生成conv層的超引數,這些超引數如圖2所示,包括:卷積核的Height、卷積核的Width、卷積核滑動stride的Height、卷積核滑動stride的Width、卷積核數量。RNN中每一個softmax預測的輸出作為下一個的輸入。 Controller生成一個網路結構後,用訓練資料進行訓練直到收斂,然後在驗證集上進行測試得到一個準確率。論文中提到生成網路結構的終止條件是當網路層數達到一個值時就會停止。
(2)Training with reinforce
將RNN控制器預測一系列輸出對應為一系列的actions:a1-T去設計network。
生成的網路在驗證集上測試得到一個準確率R,將R作為reward訊號並使用policy gradient的方法去更新此RNN(引數θc)。
目標函式:

更新θc求導: 
近似:

m:是控制器在訓練過程中一個batch中不同神經網路結構的數量,
T:是控制器設計網路結構中預測的超引數的數量,
Rk:是第k個神經網路訓練完後在驗證集上的測試準確率。
上述為無偏估計,為了降低方差引入b(bias):
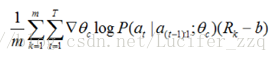

RNN輸出會經過softmax來選著architecture的引數。