
Python反爬蟲機制
-
新增請求頭User-Agent:
如果不新增請求頭,網站會認為不是用瀏覽器操作,會進行反爬蟲,新增請求頭,網站會識別你是用哪個瀏覽器,不同的瀏覽器User-Agent不同 -
修改訪問頻率:
大多數情況下,我們遇到的是訪問頻率限制。如果你訪問太快了,網站就會認為你不是一個人。這種情況下需要設定好頻率的閾值,否則有可能誤傷。
遇到這種網頁,最直接的辦法是限制訪問時間
需要你限制不定的時間,不能用一個準確的時間 -
代理IP
如果對頁的爬蟲的效率有要求,那就不能通過設定訪問時間間隔的方法來繞過頻率檢查了。
代理IP訪問可以解決這個問題。如果用100個代理IP訪問100個頁面,可以給網站造成一種有100個人,每個人訪問了1頁的錯覺。這樣自然而然就不會限制你的訪問了。
但是代理IP也很不穩定,需要時刻檢驗你的IP是否能用
- 分散式爬蟲
分散式爬蟲會部署在多臺伺服器上,每個伺服器上的爬蟲統一從一個地方拿網址。這樣平均下來每個伺服器訪問網站的頻率也就降低了。由於伺服器是掌握在我們手上的,因此實現的爬蟲會更加的穩定和高效。這也是我們這個課程最後要實現的目標。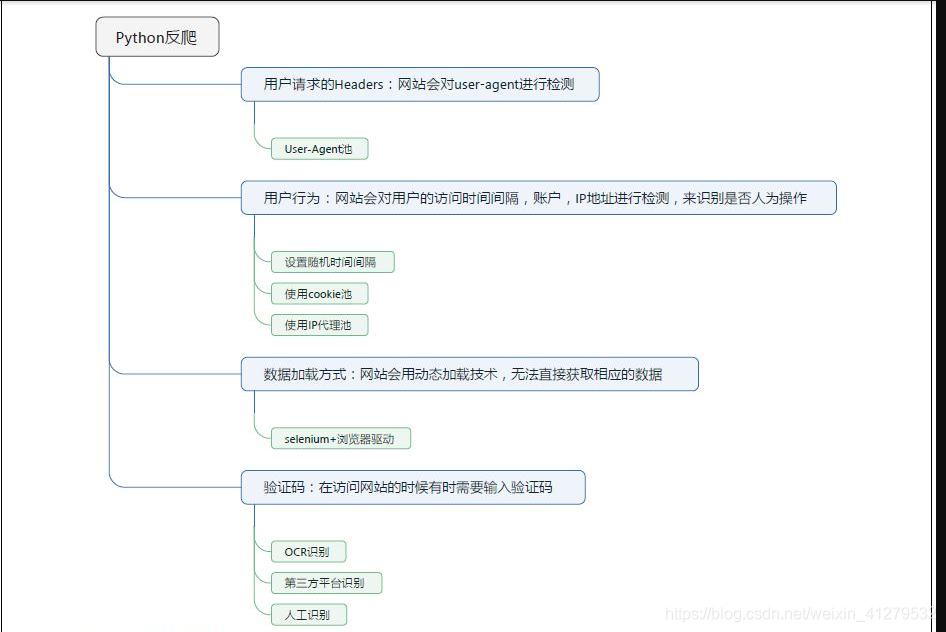
相關推薦
Python反爬蟲機制
新增請求頭User-Agent: 如果不新增請求頭,網站會認為不是用瀏覽器操作,會進行反爬蟲,新增請求頭,網站會識別你是用哪個瀏覽器,不同的瀏覽器User-Agent不同 修改訪問頻率: 大多數情況下,我們遇到的是訪問頻率限制。如果你訪問太快了,網站就會認為你不是一個人。
用Python破解有道翻譯反爬蟲機制
破解有道翻譯反爬蟲機制 web端的有道翻譯,在之前是直接可以爬的。也就是說只要獲取到了他的介面,你就可以肆無忌憚的使用他的介面進行翻譯而不需要支付任何費用。那麼自從有道翻譯推出他的API服務的時候,就對這個介面做一個反爬蟲機制(如果大家都能免費使用到他的翻譯介面,那他的
Python(4) 用Python破解有道翻譯反爬蟲機制
web端的有道翻譯,在之前是直接可以爬的。也就是說只要獲取到了他的介面,你就可以肆無忌憚的使用他的介面進行翻譯而不需要支付任何費用。那麼自從有道翻譯推出他的API服務的時候,就對這個介面做一個反爬蟲機制(如果大家都能免費使用到他的翻譯介面,那他的API服務怎麼賺錢)。這個反爬蟲機制在爬
python爬蟲-常見反爬蟲機制與應對方法
資料頭User-Agent反爬蟲機制解析: 當我們使用瀏覽器訪問網站的時候,瀏覽器會發送一小段資訊給網站,我們稱為Request Headers,在這個頭部資訊裡面包含了本次訪問的一些資訊,例如編碼方式,當前地址,將要訪問的地址等等。這些資訊一般來說是不必要的,但是現在很多
python爬蟲系統學習十一:常見反爬蟲機制與應對方法
資料頭User-Agent反爬蟲機制解析 我們小時候都聽過一首兒歌。我說一個開頭,大家肯定能把剩下的幾句背出來:小兔子乖乖,把門開啟... 當我們使用瀏覽器訪問網站的時候,瀏覽器會發送一小段資訊給網站,我們稱為Request Headers,在這個頭部資訊裡面包含了本
Python爬取拉勾網資料(破解反爬蟲機制)
人生苦短, 我學 Python! 這篇文章主要記錄一下我學習 Python 爬蟲的一個小例子, 是爬取的拉勾網的資料. 1.準備 配置 Python 環境什麼的就不說了, 網上教程很多, 自行解決. 2.扒原始碼 先開啟拉勾網的網頁. 我們要爬取這部分的資料
【爬蟲】關於企業信用信息公示系統-加速樂最新反爬蟲機制
pos 錯誤頁面 code 小時 timeout googl ear 系統 phantom ( ̄▽ ̄)~*又得半夜修仙了,作為一個爬蟲小白,花了3天時間寫好的程序,才跑了一個月目標網站就更新了,是有點悲催,還是要只有一天的時間重構。 升級後網站的層次結構並沒有太多變化,
【逆向工程2】反爬蟲機制報告
今天的主題是反爬蟲機制,網站如何能保護好自己的資料,又不影響正常使用者體驗,所謂當今業界一場持久的攻防博弈。 一階爬蟲(技術篇) 應用場景一:靜態結果頁,無頻率限制,無黑名單。 攻:直接採用scrapy爬取 防:nginx層寫lua指令碼,將爬蟲IP加入黑名單,遮蔽一段時間(不提示時
普通反爬蟲機制的應對策略
爬蟲與反爬蟲,這相愛相殺的一對,簡直可以寫出一部壯觀的鬥爭史。而在大資料時代,資料就是金錢,很多企業都為自己的網站運用了反爬蟲機制,防止網頁上的資料被爬蟲爬走。然而,如果反爬機制過於嚴格,可能會誤傷到真正的使用者請求;如果既要和爬蟲死磕,又要保證很低的誤傷率,那麼又會加大研發的成本。 簡單低階的爬蟲速度快,
scrapy: 使用HTTP代理繞過網站反爬蟲機制
scrapy提供下載中介軟體機制, 可以在請求佇列與下載請求之間做一些動作. scrapy本身也提供了一個ProxyMiddleware, 但是它只能使用固定的IP地址, 由於免費的代理相當不穩定, 很多代理其實根本不能用. 因此需要對ProxyMiddleware改造使得這個middleware能夠發現代
一.python 反爬蟲
一.爬蟲比例: 二.爬蟲頭資訊 瀏覽器header資訊: Accept 瀏覽器可接受的MIME型別 ,設定某種副檔名的檔案,瀏覽器會自動使用指定應用程式來開啟 Accept-Charset 瀏覽器支援的字元編碼 Accept-Encoding 瀏覽器知道如何解碼的資料編
java給爬蟲設定User-Agent(繞過最表面的反爬蟲機制)
今天在爬my電影評分時發現訪問被控制,但瀏覽器依舊能訪問,查閱後得知因為java程式與瀏覽器訪問不同,一些採取了簡單採反爬蟲機制的網站可以拒絕這些小爬蟲的訪問。my電影也用了不少反爬蟲策略,比如說票房、評分人數都轉換了編碼讓你不好直接爬取,但我目前不需要那一部分。在給java
利用python爬蟲成功突破12306反爬機制「打包更新」
12306自動搶票 已經到春運了,在這裡為大家奉上一個搶票的軟體,希望大家喜歡哦! 最近12306更新的比較快,而且反爬比較嚴重,研究了好長時間也不容易。 希望大家可以免費點個贊,隨手轉發一下,這裡的驗證碼。 會在本地當
【Python】爬蟲與反爬蟲大戰
公司 學校 爬取 nbsp 識別 防止 toc 壓力 自動 爬蟲與發爬蟲的廝殺,一方為了拿到數據,一方為了防止爬蟲拿到數據,誰是最後的贏家? 重新理解爬蟲中的一些概念 爬蟲:自動獲取網站數據的程序反爬蟲:使用技術手段防止爬蟲程序爬取數據誤傷:反爬蟲技術將普通用戶識別為爬蟲,
python3爬蟲--反爬蟲應對機制
網頁 gitbook python python2 正常 ip池 spi target books python3爬蟲--反爬蟲應對機制 內容來源於: Python3網絡爬蟲開發實戰; 網絡爬蟲教程(python2); 前言: 反爬蟲更多是一種攻防戰,針對網站的反爬
python網頁爬蟲開發之五-反爬
build referer mac eee pac -o strip 不響應 win64 1、頭信息檢查是否頻繁相同 隨機產生一個headers, #user_agent 集合 user_agent_list = [ ‘Mozilla/5.0 (Windows N
python 反反爬蟲策略之js動態加密url破解
這次這個爬蟲廢了我好幾天時間,第一次遇到js反爬蟲策略,瞬間被打趴下了。不過研究了好幾天之後終於是搞定了,求助的一個朋友,最後的原理我可能也不是太清楚,寫下來,記錄一下,有遇到類似問題的可以參考一下。 這個反爬蟲策略,具體是這樣的,當我寫了一個這樣的get請求。 content = re
為反反爬蟲,打造一個自己的IP池?Python獲取西刺代理IP並驗證!
胡蘿蔔醬最近在爬取知乎使用者資料,然而爬取不了一會,IP就被封了,所以去爬取了西刺代理IP來使用。 這裡爬取的是西刺國內高匿IP。我們需要的就是這一串數字。 分
Python:爬蟲例項2:爬取貓眼電影——破解字型反爬
字型反爬 字型反爬也就是自定義字型反爬,通過呼叫自定義的字型檔案來渲染網頁中的文字,而網頁中的文字不再是文字,而是相應的字型編碼,通過複製或者簡單的採集是無法採集到編碼後的文字內容的。 現在貌似不少網站都有采用這種反爬機制,我們通過貓眼的實際情況來解釋一下。 下圖的是貓眼網頁
此Python破解反爬蟲例項,曾幫助過我成長,你也會對它表示感謝!
通過用JS在本地生成隨機字串的反爬蟲機制,在利用Python寫爬蟲的時候經常會遇到的一個問題。希望通過講解,能為大家提供一種思路。以後再碰到這種問題的時候知道該如何解決。(如果缺乏學習資料的同學,文末已經給你提供!) 破解有道翻譯反爬蟲機制 web端的有道翻譯,在之前是直接可以爬的。也就是說